2021 Talent Plan KV 学习营结营总结
背景
2021 年 11 月 ~ 2022 年 1 月 ,PingCAP 举办了第一届 Talent Plan KV 学习营,相关介绍可参考 推送。
在本次比赛中,由于我们小组的两位成员之前都刷过 MIT 6.824,已经对教学级别的 raft 有一定的了解,所以参加此次比赛的目的就是去感受一下生产级别分布式 KV 的代码实现,学习实践一下 lsm, etcd, raftstore 和 percolator 的理论知识和 codebase。
u1s1,刷 lab 的过程十分曲折,我们俩所在的实验室到年底的时候都非常忙,前几周基本每周都只能抽出顶多一两天的时间来写代码,而理解 lab2b/lab3b raftstore 的难度是非常大的,我们用了一周多的时间才勉强看懂 raftstore 的代码。这使得到还剩两周时间的时候,我们才刷到 lab2c。最后两周我们利用中午午休时间和晚上睡觉时间疯狂加班,在 lab 上花了更多的时间,最后才堪堪刷完。
在刷 lab 的过程中,由于时间有限,我们始终秉持着学习优先,成绩第二的原则。即以 了解 codebase,学习知识,做最容易做且最有用的优化 为主,并没有去卷很多功能点。在处理 bug 的态度上,对于 safety 的问题比如错误读写的 bug 等,我们对这类问题进行了重点关注和解决;对于 liveness 的问题比如 request timeout 等,我们则是在有限的时间内尽力做了优化,但并没有投入太多精力,因为这种工作没有上限,tikv 的 raftstore 也一定在持续做这些工作,时间不够的情况下去卷这些就没有太大意义了。

出人意料的是,我们得了第二名的好成绩,具体可参考 官宣。事后反省一下,在 safety 上我们遇到的问题都解决了;在 liveness 上我们没投入太多精力;在文档上,我们简单介绍了代码实现,但将重点放在了我们对相关知识的理解和思考上;在性能上,我们重点做了最容易做的 batching 优化,其本质上是使用 raft 的优化而不是 raft 自身的优化,但对性能的提升却异常关键,比如 tidb 对于一个事务打包的一堆写请求,到 tikv 的 region 之后,这些写请求同步成一条还是多条 raftlog 对于性能的影响是巨大的。
从结果来看,我们的策略是正确的,我们在很有限的时间内拿到了很高的收益。
最后,出于对课程的保护,也出于跟大家分享一些刷 lab 的经验,让大家少踩坑,在此处我仅将文档公开,希望能为大家提供一些思路,欢迎一起交流。
文档
lab1
解题思路
Part 1 : Implement a standalone storage engine
本部分是对底层 badger api 的包装,主要涉及修改的代码文件是 standalone_storage.go, 需要实现 Storage 接口的 Write 和 Reader 方法,来实现对底层 badger 数据库的读写。
1.Write 部分实现思路
Write 部分涉及到 Put 和 Delete 两种操作。
因为 write_batch.go 中已经实现了对 badger 中 entry 的 put 和 delete 操作,我们只需要判断 batch 中的每一个 Modify 的操作类型,然后直接调用 write_batch.go 中相对应的方法即可。
2.Reader 部分实现思路
Reader 部分会涉及到 point read 和 scan read 两种不同读方式。
因为提示到应该使用 badger.Txn 来实现 Reader 函数,所以我们声明了一个 badgerReader 结构体来实现 StorageReader 接口,badgerReader 结构体内部包含对 badger.Txn 的引用。
针对 point read,
我们直接调用 util.go 中的 GetCF 等函数,对 cf 中指定 key 进行读取。
针对 scan read,
直接调用 cf_iterator.go 中的 NewCFIterator 函数,返回一个迭代器,供 part2 中调用。
Part 2 : Implement raw key/value service handlers
本部分需要实现 RawGet/ RawScan/ RawPut/ RawDelete 四个 handlers,主要涉及修改的代码文件是 raw_api.go
针对 RawGet,
我们调用 storage 的 Reader 函数返回一个 Reader,然后调用其 GetCF 函数进行点读取即可,读取之后需要判断对应 key 是否存在。
针对 RawScan,
同样地调用 storage 的 Reader 函数返回一个 Reader,然后调用其 IterCF 函数返回一个迭代器,然后使用迭代器读取即可。
针对 RawPut 和 RawDelete,
声明对应的 Modify 后,调用 storage.Write 函数即可。
相关知识学习
LSM 是一个伴随 NoSQL 运动一起流行的存储引擎,相比 B+ 树以牺牲读性能的代价在写入性能上获得了较大的提升。
近年来,工业界和学术界均对 LSM 树进行了一定的研究,具体可以阅读 VLDB2018 有关 LSM 的综述:LSM-based Storage Techniques: A Survey, 也可直接阅读针对该论文我认为还不错的一篇 中文概要总结。
介绍完了 LSM 综述,可以简单聊聊 badger,这是一个纯 go 实现的 LSM 存储引擎,参照了 FAST2016 有关 KV 分离 LSM 的设计: WiscKey 。有关其项目的动机和一些 benchmark 结果可以参照其创始人的 博客。
对于 Wisckey 这篇论文,除了阅读论文以外,也可以参考此 阅读笔记 和此 总结博客。这两篇资料较为系统地介绍了现在学术界和工业界对于 KV 分离 LSM 的一些设计和实现。
实际上对于目前的 NewSQL 数据库,其底层大多数都是一个分布式 KV 存储系统。对于 OLTP 业务,其往往采用行存的方式,即 key 对应的 value 便是一个 tuple。在这样的架构下,value 往往很大,因而采用 KV 分离的设计往往能够减少大量的写放大,从而提升性能。
之前和腾讯云的一个大佬聊过,他有说 TiKV 的社区版和商业版存储引擎性能差异很大。目前想一下,KV 分离可能便是 RocksDB 和 Titan 的最大区别吧。
lab2
解题思路
lab2a
Leader election
本部分是对 raft 模块 leader 选举功能的实现,主要涉及修改的代码文件是 raft.go、log.go
raft 模块 leader 选举流程如下:
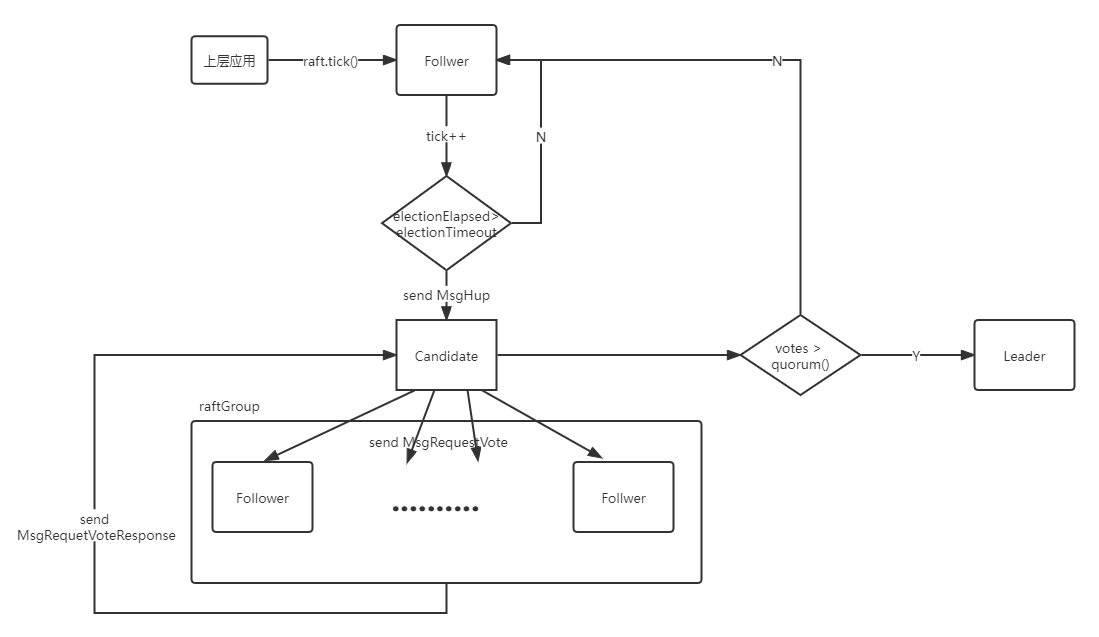
第一步,我们首先实现对 raft 的初始化。
实现 log.go 中的 newLog 方法,调用 storage 的 InitialState 等方法对 RaftLog 进行初始化,读取持久化在 storage 中 term、commit、vote 和 entries,为后面的 lab 做准备。完成 RaftLog 的初始化后,再填充 Raft 中的相应字段,即完成 Raft 对象的初始化。
第二步,我们实现 Raft 对象的 tick() 函数
上层应用会调用 tick() 函数,作为逻辑时钟控制 Raft 模块的选举功能和心跳功能。因此我们实现 tick() 函数,当 Raft 状态是 Follower 时,检查自上次接收心跳之后,间隔时间是否超过了 election timeout,如果超过了,将发送 MessageType_MsgHup;当 Raft 状态时 Leader 时,检查自上次发送心跳之后,间隔时间是否超过了 heartbeat timeout,如果超过了,将发送 MessageType_MsgBeat。
第三步,我们实现 raft.Raft.becomeXXX 等基本函数
实现了 becomeFollower(),becomeCandidate(),becomeLeader() 等 stub 函数,对不同状态下的属性进行赋值。
第四步,我们实现 Step() 函数对不同 Message 的处理
主要涉及到的 Message 有
MessageType_MsgHup
MessageType_MsgRequestVote
MessageType_MsgRequestVoteResponse
接下来分情况实现:
(1)MessageType_Msgup
当 Raft 状态为 Follower 和 Candidate 时,会先调用 becomeCandidate() 方法,将自己的状态转变为 Candidate,然后向所有 peer 发送 MessageType_MsgRequestVote 消息,请求他们的投票
(2)MessageType_MsgRequestVote
当 Raft 接收到此消息时,会在以下情况拒绝投票:
当 Candidate 的 term 小于当前 raft 的 term 时拒绝投票
如果当前 raft 的 term 与 candidate 的 term 相等,但是它之前已经投票给其他 Candidate 时,会拒绝投票
如果当前 raft 发现 candidate 的日志不如自己的日志更 up-to-date 时,也会拒绝投票
(3)MessageType_MsgRequestVoteResponse
Candidate 接收到此消息时,就会根据消息的 reject 属性来确定自己的得票,当自己的得票数大于一半以上,就会调用 becomeLeader() 函数,将状态转变为 Leader;当拒绝票数也大于一半以上时,就会转回到 Follower 状态。
Log replication
本部分是对 raft 模块日志复制功能的实现,主要涉及修改的代码文件是 raft.go、log.go
日志复制的流程如下:
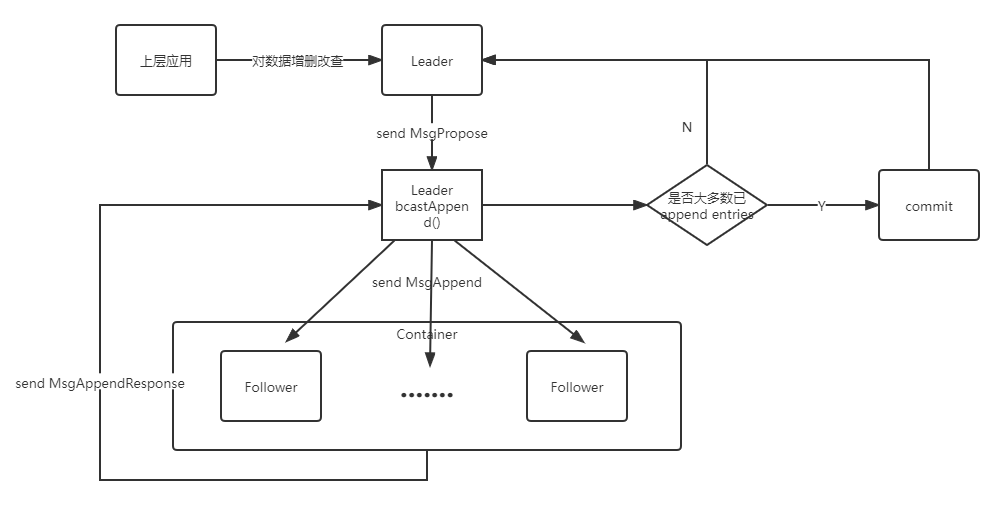
本部分主要实现不同状态的 raft 对以下 Message 的处理:
- MessageType_MsgBeat
- MessageType_MsgHeartbeat
- MessageType_MsgHeartbeatResponse
- MessageType_MsgPropose
- MessageType_MsgAppend
- MessageType_MsgAppendResponse
接下来分情况实现:
(1)MessageType_MsgBeat
当上层应用调用 tick() 函数时,Leader 需要检查是否到了该发送心跳的时候,如果到了,那么就发送 MessageType_MsgHeartbeat。
leader 会将自己的 commit 值赋给在 MsgHeartbeat 消息中响应值,以让 Follower 能够及时 commit 安全的 entries
(2)MessageType_MsgHeartbeat
当 Follower 接收到心跳时,会更新自己的 electionTimeout,并会将自己的 lastIndex 与 leader 的 commit 值比较,让自己能够及时 commit entry。
(3)MessageType_MsgHeartbeatResponse
当 Leader 接收到心跳回复时,会比较对应 Follower 的 Pr.Match, 如果发现 Follower 滞后,就会向其发送缺少的 entries
(4)MessageType_MsgPropose
当 Leader 要添加 data 到自己的 log entries 中时,会发送一个 local message—MsgPropose 来让自己向所有 follower 同步 log entries,发送 MessageType_MsgAppend
(5)MessageType_MsgAppend
当 Follower 接收到此消息时,会在以下情况拒绝 append:
- 当 Leader 的 term 小于当前 raft 的 term 时拒绝 append
- 当 Follower 在对应 Index 处不含 entry,说明 Follower 滞后比较严重
- 当 Follower 在对应 Index 处含有 entry,但是 term 不相等,说明产生了冲突
其他情况,Follower 会接收新的 entries,并更新自己的相关属性。
(6)MessageType_MsgAppendResponse
当 Leader 发现 Follower 拒绝 append 后,会更新 raft.Prs 中对应 Follower 的进度信息,并根据新的进度,重新发送 entries。
Implement the raw node interface
本部分主要实现 raw node 的接口,涉及修改的代码文件为 rawnode.go
RawNode 对象中的属性除了 Raft 对象,还增加了 prevSoftState 和 preHardState 两个属性,用于在 HasReady() 函数中判断 node 是否 pending
此外还实现了 Advance() 函数,主要是对 Raft 内部属性进行更新。
lab2b
Implement peer storage
本部分主要实现 peer_storage.go 中 SaveReadyState() 方法和 Append() 方法,涉及修改的代码文件为 peer_storage.go
peer storage 除了管理持久化 raft log 外,也会管理持久化其他元数据(RaftLocalState、RaftApplyState 和 RegionLocalState),因此我们需要实现 SaveReadyState() 方法,将 raft.Ready 中修改过的状态和数据保存到 badger 中。
首先我们通过实现 Append() 方法,保存需要持久化的 raft log。遍历 Ready 中 Entries,调用 SetMeta() 方法将他们保存到 raftWB,并删除可能未提交的 raft log,最后更新 raftState。
在处理完 raft log 后,我们还需要保存 Ready 中的 hardState,并在最后调用 WriteToDB() 方法保证之前的修改落盘。
Implement raft ready process
本部分主要实现 peer_storage_handler.go 中的 proposeRaftCommand() 和 HandleRaftReady() 方法,涉及修改的代码文件为 peer_storage_handler.go
proposeRaftCommand() 方法使得系统有能力将接收到的 client 请求通过 raft 模块进行同步,以实现分布式环境下的一致性。在本方法中,我们直接调用 raft 模块的 Propose 方法,将 client 请求进行同步,并为该请求初始化对应的 proposal,以便该请求 committed 后将结果返回给 client
当 msg 被 raft 模块处理后,会导致 raft 模块的一些状态变化,这时候需要 HandleRaftReady() 方法进行一些操作来处理这些变化:
- 需要调用 peer_storage.go() 中的 SaveReadyState() 方法,将 log entries 和一些元数据变化进行持久化。
- 需要调用 peer_storage_handler 中的 send() 方法,将一些需要发送的消息,发送给同一个 region 中的 peer
- 我们需要处理一些 committed entries,将他们应用到状态机中,并把结果通过 callback 反馈给 client
- 在上述处理完后,需要调用 advance() 方法,将 raft 模块整体推进到下一个状态
lab2c
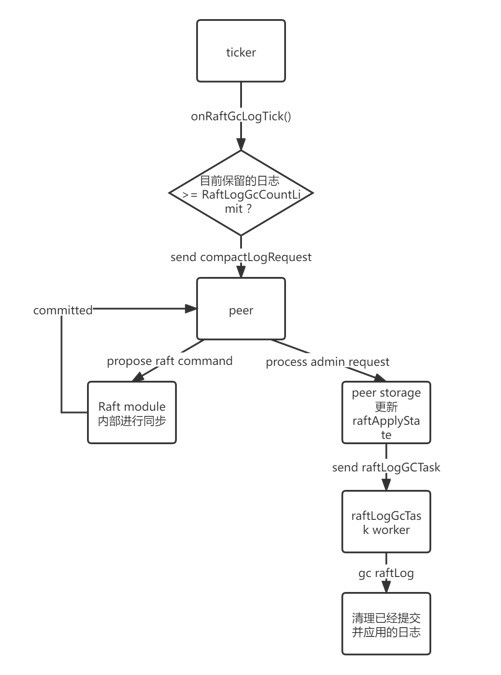
因为 raft entries 不可能一直无限增长下去,所以本部分我们需要实现 snapshot 功能,清理之前的 raft entries。
整个 lab2c 的执行流程如下:
- gc log 的流程:
- 发送和应用 snapshot 的流程:
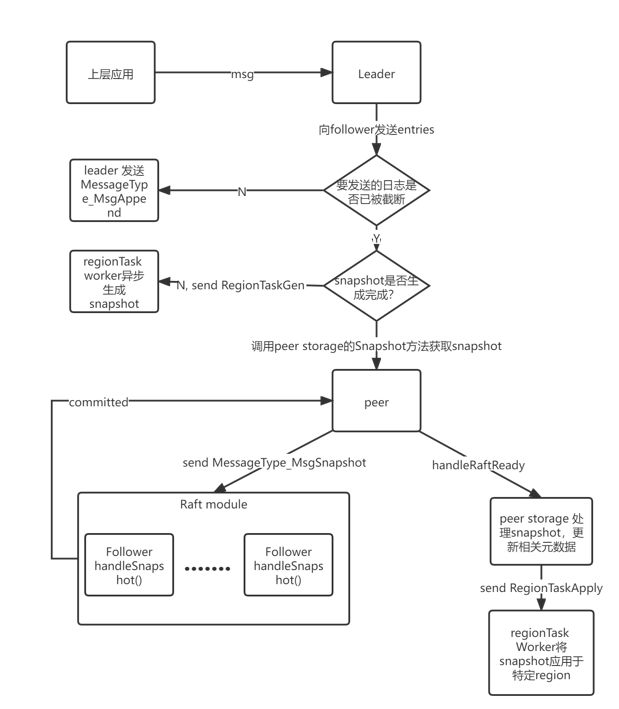
Implement in raft
当 leader 发现 follower 落后太多时,会主动向 follower 发送 snapshot,对其进行同步。在 Raft 模块内部,需要增加对 MessageType_MsgSnapshot 消息的处理,主要对以下两点进行处理:
- 当 leader 需要向 follower 同步日志时,如果同步的日志已经被 compact 了,那么直接发送 snapshot 给 follower 进行同步,否则发送 MessageType_MsgAppend 消息,向 follower 添加 entries。通过调用 peer storage 的 Snapshot() 方法,我们可以得到已经制作完成的 snapshot
- 实现 handleSnapshot() 方法,当 follower 接收到 MessageType_MsgSnapshot 时,需要进行相应处理。
在第二步中,follower 需要判断 leader 发送的 snapshot 是否会与自己的 entries 产生冲突,如果发送的 snapshot 是目前现有 entries 的子集,说明 snapshot 是 stale 的,那么要返回目前 follower 的进度,更新 leader 中相应的 Match 和 Next,以便再下一次发送正确的日志;如果没有发生冲突,那么 follower 就根据 snapshot 中的信息进行相应的更新,更新自身的 committed 等 index,如果 confstate 也产生变化,有新的 node 加入或者已有的 node 被移除,需要更新本节点的 confState,为 lab3 做准备。
Implement in raftstore
在本部分中,当日志增长超过 RaftLogGcCountLimit 的限制时,会要求本节点整理和删除已经应用到状态机的旧日志。节点会接收到类似于 Get/Put/Delete/Snap 命令的 CompactLogRequest,因此我们需要在 lab2b 的基础上,当包含 CompactLogRequest 的 entry 提交后,增加 processAdminRequest() 方法来对这类 adminRequest 的处理。
在 processAdminRequest() 方法中,我们需要更新 RaftApplyState 中 RaftTruncatedState 中的相关元数据,记录最新截断的最后一个日志的 index 和 term,然后调用 ScheduleCompactLog() 方法,异步让 RaftLog-gc worker 能够进行旧日志删除的工作。
另外,因为 raft 模块在处理 snapshot 相关的 msg 时,也会对一些状态进行修改,所以在 peer_storage.go 方法中,我们需要在 SaveReadyState() 方法中,调用 ApplySnapshot() 方法中,对相应的元数据进行保存。
在 ApplySnapshot() 方法中,如果当前节点已经处理过的 entries 只是 snapshot 的一个子集,那么需要对 raftLocalState 中的 commit、lastIndex 以及 raftApplyState 中的 appliedIndex 等元数据进行更新,并调用 ClearData() 和 ClearMetaData() 方法,对现有的 stale 元数据以及日志进行清空整理。同时,也对 regionLocalState 进行相应更新。最后,我们需要通过 regionSched 这个 channel,将 snapshot 应用于对应的状态机
相关知识学习
Raft
Raft 是 2015 年以来最受人瞩目的共识算法,有关其前世今生可以参考我们总结的 博客,此处不再赘述。
etcd 是一个生产级别的 Raft 实现,我们在实现 lab2a 的时候大量参考了 etcd 的代码。这个过程不仅帮助我们进一步了解了 etcd 的 codebase,也让我们进一步意识到一个工程级别的 raft 实现需要考虑多少 corner case。整个学习过程收获还是很大的,这里贴一些 etcd 的优质博客以供学习。
KVRaft
在 Raft 层完成后,下一步需要做的便是基于 Raft 层搭建一个高可用的 KV 层。这里依然参考了 etcd KV 层驱动 Raft 层的方式。
即总体的思路如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15for {
select {
case <-s.Ticker:
Node.Tick()
default:
if Node.HasReady() {
rd := Node.Ready()
saveToStorage(rd.State, rd.Entries, rd.Snapshot)
send(rd.Messages)
for _, entry := range rd.CommittedEntries {
process(entry)
}
s.Node.Advance(rd)
}
}
做过 tinykv 的同学应该都能够感觉到 lab2b 的难度与之前有一个大 gap,我认为主要原因是需要看的代码实现是太多了。
如今回首,建议分三个步骤来做,这样效率可能会高一些:
- 了解读写流程的详细步骤。对于 client 的请求,其处理和回复均在 raft_server.go 中进行了处理,然而其在服务端内部的生命周期如何,这里需要知根知底。(注意在遇到 channel 打断同步的执行流程时不能瞎猜,一定要明确找到 channel 的接收端和发送端继续把生命周期理下去)
- 仔细阅读 raft_server.go, router.go, raftstore.go, raft_worker.go, peer_storage.go, peer_msg_handle.go 等文件的代码。这会对了解整个系统的 codebase 十分有帮助。
- 仔细阅读 tinykv 的 lab2 文档,了解编码,存储等细节后便可以动手实现了。
在实现 lab2b 中,由于时间有限,我们重点关注了 batching 的优化和 apply 时的 safety,以下进行简单的介绍:
batching 优化:客户端发来的一条 command 可能包含多个读写请求,服务端可以将其打包成一条或多条 raft 日志。显然,打包成一条 Raft 日志的性能会更高,因为这样能够节省大量 IO 资源的消耗。当然这也需要在 apply 时对所有的 request 均做相应的业务和容错处理。
apply 时的 safety:要想实现基于 Raft 的 KV 服务,一大难点便是如何保证 applyIndex 和状态机数据的原子性。比如在 6.824 的框架中,Raft 层对于上层状态机的假设是易失的,即重启后状态机为空,那么 applyIndex 便可以不被持久化记录,因为一旦发生重启 Raft 实例可以从 0 开始重新 apply 日志,对于状态机来说这个过程保证不会重复。然而这样的实现虽然保证了 safety,但却不是一个生产可用的实现。对于 tinykv,其状态机为非易失的 LSM 引擎,一旦要记录 applyIndex 就可能出现与状态机数据不一致的原子性问题,即重启后可能会存在日志被重复 apply 到状态机的现象。为了解决这一问题,我们将每个 Index 下 entry 的应用和对应 applyIndex 的更新放到了一个事务中来保证他们之间的原子性,巧妙地解决了该过程的 safety 问题。
Snapshot
tinykv 的 Snapshot 几乎是一个纯异步的方案,在架构上有很多讲究,这里可以仔细阅读文档和一位社区同学分享的 Snapshot 流程 后再开始编码。
一旦了解了以下两个流程,代码便可以自然而然地写出来了。
- log gc 流程
- snapshot 的异步生成,异步分批发送,异步分批接收和异步应用。
lab3
解题思路
lab3a
本部分主要涉及 Raft 算法 leader transfer 和 conf change 功能的两个工作,主要涉及修改的代码文件是 raft.go
对于 leader transfer,注意以下几点即可:
- leader 在 transfer 时需要阻写。
- 当 leader 发现 transferee 的 matchIndex 与本地的 lastIndex 相等时直接发送 timeout 请求让其快速选举即可,否则继续发送日志让其快速同步。
- 当 follower 收到 leader transfer 请求时,直接发起选举即可
对于 conf change,注意以下几点即可:
- 只对还在共识组配置中的 raftnode 进行 tick。
- 新当选的 leader 需要保证之前任期的所有 log 都被 apply 后才能进行新的 conf change 变更,这有关 raft 单步配置变更的 safety,可以参照 邮件 和相关 博客。
- 只有当前共识组的最新配置变更日志被 apply 后才可以接收新的配置变更日志。
- 增删节点时需要维护 PeerTracker。
lab3b
本部分主要是在 3a 的基础上,在 raft store 层面实现对 TransferLeader、ChangePeer 和 Split 三种 AdminRequest 的处理,涉及修改的文件主要是 peer_msg_handler.go 和 peer.go
对于 TransferLeader,比较简单:
TransferLeader request 因为不需要复制到 follower 节点,所以在 peer_msg_handler.go 的 pproposeRaftCommand() 方法中直接调用 raw_node.go 中的 TransferLeader() 方法即可
对于 ConfChange,分 addNode 和 removeNode 两种行为处理。
当 addNode 的命令 commit 之后,不需要我们手动调用 createPeer() 或者 maybeCreatePeer() 来显式创建 peer。我们只需要对 d.ctx 中的 storeMeta 进行修改即可,新 peer 会通过心跳机制进行创建。
当 removeNode 的命令 commit 之后,与 addNode 命令不同的是,我们需要显式调用 destroyPeer() 函数来停止相应的 raft 模块。这时需要注意的一个点时,当 Region 中只剩下两个节点,要从这两个节点中移除一个时,如果有一个节点挂了,会使整个集群不可用,特别是要移除的节点是 leader 本身。
在测试中会遇到这样的问题:当 Region 中只剩下节点 A(leader)和 节点 B(follower),当 removeNode A 的命令被 commit 之后,leader 就进行自我销毁,如果这个时候进入了 unreliable 的状态,那么 leader 就有可能无法在 destory 之前通过 heartbeat 去更新 follower 的 commitIndex。这样使得 follower B 不知道 leader A 已经被移除,就算发起选举也无法收到节点 A 的 vote,最终无法成功,导致 request timeout。
对于 split, 需要注意:
- 因为 Region 会进行分裂,所以需要对 lab2b 进行修改,当接收到 delete/put/get/snap 等命令时,需要检查他们的 key 是否还在该 region 中,因为在 raftCmd 同步过程中,可能会发生 region 的 split,也需要检查 RegionEpoch 是否匹配。
- 在比较 splitKey 和当前 region 的 endKey 时,需要使用 engine_util.ExceedEndKey(),因为 key range 逻辑上是一个环。
- split 时也需要对 d.ctx 中的 storeMeta 中 region 相关信息进行更新。
- 需要显式调用 createPeer() 来创建新 Region 中的 peer。
- 在 3b 的最后一个测试中,我们遇到以下问题:
- 达成共识需要的时间有时候比较长,这就会导致新 region 中无法产生 leade 与 Scheduler 进行心跳交互,来更新 Scheduler 中的 regions,产生 find no region 的错误。这一部分可能需要 pre-vote 来进行根本性地解决,但时间不够,希望以后有时间解决这个遗憾。
- 会有一定概率遇到“多数据”的问题,经排查发现 snap response 中会包含当前 peer 的 region 引用返回,但是这时可能会产生的一个问题时,当返回时 region 是正常的,但当 client 端要根据这个 region 来读的时候,刚好有一个 split 命令改变了 region 的 startKey 或者 endKey,最后导致 client 端多读。该问题有同学在群中反馈应该测试中对 region 进行复制。
- 会有一定概率遇到“少数据”的问题,这是因为当 peer 未初始化时,apply snapshot 时不能删除之前的元数据和数据。
lab3c
本部分主要涉及对收集到的心跳信息进行选择性维护和对 balance-region 策略的具体实现两个工作,主要涉及修改的代码文件是 cluster.go 和 balance_region.go
对于维护心跳信息,按照以下流程执行即可:
- 判断是否存在 epoch,若不存在则返回 err
- 判断是否存在对应 region,如存在则判断 epoch 是否陈旧,如陈旧则返回 err;若不存在则选择重叠的 regions,接着判断 epoch 是否陈旧。
- 否则维护 region 并更新 store 的 status 即可。
对于 balance-region 策略的实现,按照以下步骤执行即可:
- 获取健康的 store 列表:
- store 必须状态是 up 且最近心跳的间隔小于集群判断宕机的时间阈值。
- 如果列表长度小于等于 1 则不可调度,返回空即可。
- 按照 regionSize 对 store 大小排序。
- 寻找可调度的 store:
- 按照大小在所有 store 上从大到小依次寻找可以调度的 region,优先级依次是 pending,follower,leader。
- 如果能够获取到 region 且 region 的 peer 个数等于集群的副本数,则说明该 region 可能可以在该 store 上被调度走。
- 寻找被调度的 store:
- 按照大小在所有 store 上从小到达依次寻找不存在该 region 的 store。
- 找到后判断迁移是否有价值,即两个 store 的大小差值是否大于 region 的两倍大小,这样迁移之后其大小关系依然不会发生改变。
- 如果两个 store 都能够寻找到,则在新 store 上申请一个该 region 的 peer,创建对应的 MovePeerOperator 即可。
相关知识学习
Multi-Raft
Multi-Raft 是分布式 KV 可以 scale out 的基石。TiKV 对每个 region 的 conf change 和 transfer leader 功能能够将 region 动态的在所有 store 上进行负载均衡,对 region 的 split 和 merge 则是能够解决单 region 热点并无用工作损耗资源的问题。不得不说,后两者尽管道理上理解起来很简单,但工程实现上有太多细节要考虑了(据说贵司写了好几年才稳定),分析可能的异常情况实在是太痛苦了,为贵司能够啃下这块硬骨头点赞。
最近看到有一个基于 TiKV 的 hackathon 议题,其本质是想通过更改线程模型来优化 TiKV 的写入性能、性能稳定性和自适应能力。这里可以简单提提一些想法,其实就我们在时序数据库方向的一些经验来说,每个 TSM(TimeSeries Merge Tree)大概能够用满一个核的 CPU 资源。只要我们将 TSM 引擎额个数与 CPU 核数绑定,写入性能基本是能够随着核数增加而线性提升的。那么对于 KV 场景,是否开启 CPU 个数的 LSM 引擎能够更好的利用 CPU 资源呢?即对于 raftstore,是否启动 CPU 个数的 Rocksdb 实例能够更好的利用资源呢?感觉这里也可以做做测试尝试一下。
负载均衡
负载均衡是分布式系统中的一大难题,不同系统均有不同的策略实现,不同的策略可能在不同的 workload 中更有效。
相比 pd 的实现,我们在 lab3c 实现的策略实际上很 trivial,因此我们简单学习了 pd 调度 region 的 策略。尽管这些策略道理上理解起来都比较简单,但如何将所有统计信息准确的量化成一个动态模型却是一件很难尽善尽美的事,这中间的很多指标也只能是经验值,没有严谨的依据。
有关负载均衡我们对学术界的相关工作还不够了解,之后有时间会进行一些关注。
lab4
解题思路
本 Lab 整体相对简单,在基本了解 MVCC, 2PC 和 Percolator 后便可动手了,面向测试用例编程即可。
lab4a
本部分是对 mvcc 模块的实现,主要涉及修改的代码文件是 transaction.go。需要利用对 CFLock, CFDefault 和 CFWrite 三个 CF 的一些操作来实现 mvcc。
针对 Lock 相关的函数:
- PutLock:将 PUT
- DeleteLock:将 Delete
添加到 Modify 即可。 - GetLock:在 CFLock 中查找即可。
针对 Value 相关的函数:
- PutValue:将 PUT
- DeleteValue:将 Delete
- GetValue:首先从 CFWrite 中寻找在当前快照之前已经提交的版本。如果未找到则返回空,如果找到则正对不同的 Kind 有不同的行为:
- Put:根据 value 中的 StartTS 去 CFDefault 寻找即可。
- Delete:返回空即可。
- Rollback:继续寻找之前的版本。
针对 Write 相关的函数:
- PutWrite:将 PUT
- CurrentWrite:从 CFWrite 当中寻找当前 key 对应且值的 StartTS 与当前事务 StartTS 相同的行。
- MostRecentWrite:从 CFWrite 当中寻找当前 key 对应且值的 StartTS 最大的行。
lab4b
本部分是对 Percolator 算法 KVPreWrite, KVCommit 和 KVGet 三个方法的实现,主要涉及修改的代码文件是 server.go, query.go 和 nonquery.go。
- KVPreWrite:针对每个 key,首先检验是否存在写写冲突,再检查是否存在行锁,如存在则需要根据所属事务是否一致来决定是否返回 KeyError,最后将 key 添加到 CFDefault 和 CFLock 即可。
- KVCommit:针对每个 key,首先检查是否存在行锁,如不存在则已经 commit 或 rollback,如存在则需要根据 CFWrite 中的当前事务状态来判断是否返回 KeyError,最后将 key 添加到 CFWrite 中并在 CFLock 中删除即可。
- KVGet:首先检查行锁,如为当前事务所锁,则返回 Error,否则调用 mvcc 模块的 GetValue 获得快照读即可。
lab4c
本部分是对 Percolator 算法 KvCheckTxnStatus, KvBatchRollback, KvResolveLock 和 KvScan 四个方法的实现,主要涉及修改的代码文件是 server.go, query.go 和 nonquery.go。
- KvCheckTxnStatus:检查 PrimaryLock 的行锁,如果存在且被当前事务锁定,则根据 ttl 时间判断是否过期从而做出相应的动作;否则锁很已被 rollback 或者 commit,从 CFWrite 中获取相关信息即可。
- KvBatchRollback:针对每个 key,首先检查是否存在行锁,如果存在则删除 key 在 CFLock 和 CFValue 中的数并且在 CFWrite 中写入一条 rollback 即可。如果不存在或者不归当前事务锁定,则从 CFWrite 中获取当前事务的提交信息,如果不存在则向 CFWrite 写入一条 rollback,如果存在则根据是否为 rollback 判断是否返回错误。
- KvResolveLock:针对每个 key,根据请求中的参数决定来 commit 或者 rollback 即可。
- KvScan:利用 Scanner 扫描到没有 key 或达到 limit 阈值即可。针对 scanner,需要注意不能读有锁的 key,不能读未来的版本,不能读已删除或者已 rollback 的 key。
代码结构
为了使得 server.go 逻辑代码清晰,在分别完成三个 lab 后对代码进行了进一步整理,针对读写请求分别抽象出来了接口,这样可以使得逻辑更为清晰。
1 | |
相关知识学习
有关分布式事务,我们之前有过简单的 学习,对 2PL, 2PC 均有简单的了解,因此此次在实现 Percolator 时只需要关注 2PC 与 MVCC 的结合即可,这里重点参考了以下博客:
- TiKV 源码解析系列文章(十二)分布式事务
- TiKV 事务模型概览,Google Spanner 开源实现
- Google Percolator 分布式事务实现原理解读
- Async Commit 原理介绍
实现完后,我们进一步被 Google 的聪明所折服,Percolator 基于单行事务实现了多行事务,基于 MVCC 实现了 SI 隔离级别。尽管其事务恢复流程相对复杂,但其本质上是在 CAP 定理中通过牺牲恢复时的 A 来优化了协调者正常写入时的 A,即协调者单点在 SQL 层不用高可用来保证最终执行 commit 或者 abort。因为一旦协调者节点挂掉,该事务在超过 TTL (TTL 的超时也是由 TSO 的时间戳来判断,对于各个 TiKV 节点来说均为逻辑时钟,这样的设计也避免了 Wall Clock 的同步难题)后会被其他事务 rollback,总体上来看 Percolator 比较优雅的解决了 2PC 的 safety 问题。
当然,分布式事务可以深究的地方还很多,并且很多思想都与 Lamport 那篇最著名的论文 Time, Clocks, and the Ordering of Events in a Distributed System 有关。除了 TiDB 外,Spanner,YugaByte,CockroachDB 等 NewSQL 数据库均有自己的大杀器,比如 TrueTime,HLC 等等。总之这块儿挺有意思的,虽然在这儿告一段落,但希望以后有机会能深入做一些相关工作。
总结
实现一个稳定的分布式系统实在是太有挑战太有意思啦。
感谢 PingCAP 社区提供如此优秀的课程!