Raft 算法介绍
背景
共识算法
共识算法允许一组节点像一个整体一样一起工作,即使其中一些节点出现故障也能够继续工作下去,其正确性主要源于复制状态机的性质:
任何初始状态一样的状态机,如果执行的命令序列一样,则最终达到的状态也一样。如果将此特性应用在多参与者进行协商共识上,可以理解为系统中存在多个具有完全相同的状态机(参与者),这些状态机能最终保持一致的关键就是起始状态完全一致和执行命令序列完全一致。
共识算法常被用来确保每一个节点上的状态机一定都会按相同的顺序执行相同的命令, 并且最终会处于相同的状态。换句话说,可以理解为共识算法就是用来确保每个节点上的日志顺序都是一致的。(不过需要注意的是,只确保“提交给状态机的日志”顺序是一致的,而有些日志项可能只是暂时添加,尚未决定要提交给状态机)。正因为如此,共识算法在构建可容错的大规模分布式系统中扮演着重要的角色。
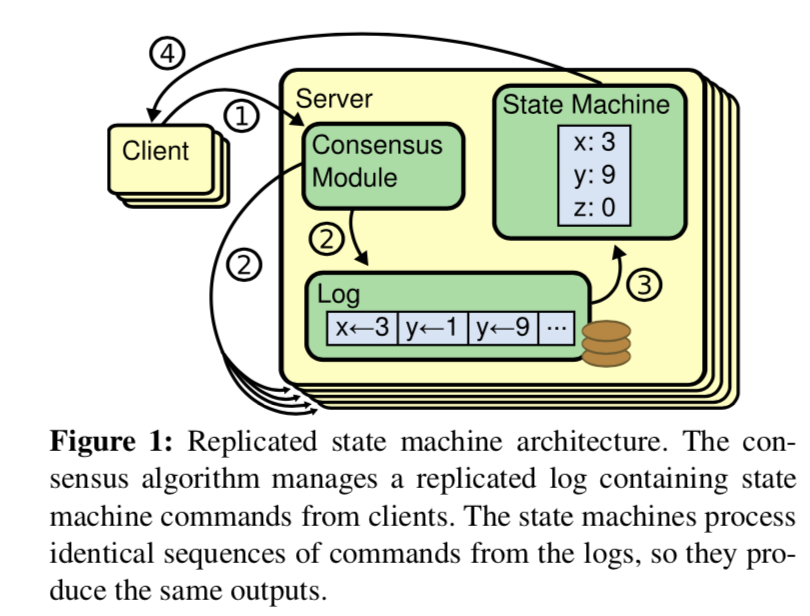
上图就是每个节点的状态机,日志模块,共识模块与客户端交互的过程。
当然,实际使用系统中的共识算法一般满足以下特性:
- 在非拜占庭条件下保证共识的一致性。(非拜占庭条件,指的就是每一个节点都是诚实可信的,每一次信息的传递都是真实的且符合协议要求的,当节点无法满足协议所要求的条件时,就停止服务,节点仅会因为网络延迟或崩溃出现不一致,而不会有节点传递错误的数据或故意捏造假数据。)
- 在多数节点存活时,保持可用性。(“多数”永远指的是配置文件中所有节点的多数,而不是存活节点的多数。)
- 不依赖于时间,错误的时钟和高延迟只会导致可用性问题,而不会导致一致性问题。
- 在多数节点一致后就返回结果,而不会受到个别慢节点的影响。
Raft 的由来与宗旨
众所周知,Paxos 是一个非常划时代的共识算法。在 Raft 出现之前的 10 年里,Paxos 几乎统治着共识算法这一领域:因为绝大多数共识算法的实现都是基于 Paxos 或者受其影响,同时 Paxos 也成为了教学领域里讲解共识问题时的示例。
但是不幸的是,尽管有很多工作都在尝试降低 Paxos 的复杂性,但是它依然十分难以理解。并且,Paxos 自身的算法结构需要进行大幅的修改才能够应用到实际的系统中。这些都导致了工业界和学术界都对 Paxos 算法感到十分头疼。比如 Google Chubby 的论文就提到,因为 Paxos 的描述和现实差距太大,所以最终人们总会实现一套未经证实的类 Paxos 协议。
基于以上背景,Diego Ongaro 在就读博士期间,深入研究 Paxos 协议后提出了 Raft 协议,旨在提供更为易于理解的共识算法。Raft 的宗旨在于可实践性和可理解性,并且相比 Paxos 几乎没有牺牲多少性能。
趣闻:Raft 名字的来源。简而言之,其名字即来自于
R{eliable|plicated|dundant} And Fault-Tolerant, 也来自于这是一艘可以帮助你逃离 Paxos 小岛的救生筏(Raft)。
工业界的实现
tikvconsuletcdsofajraft- …
概述
这一部分会简单介绍 Raft 的一些基本概念。若暂时没看懂并没有关系,后面会一一介绍清楚,带着问题耐心读完此博客即可。
子问题
Raft 将共识算法这个难解决的问题分解成了多个易解决,相对独立的子问题,这些问题都会在接下来的章节中进行介绍。
Leader election:选出集群的 leader 来统筹全局。Log replication:leader 负责从客户端接收请求,并且在集群中扩散同步。Safety:各节点间状态机的一致性保证。
在博士论文和实际生产系统中,还有更多可以探讨的模块或细节功能:
Log compaction:压缩日志以节约磁盘空间;加速重启后节点恢复速率;加速新节点 catch up 速率。Leader transfer:能够将 leader 禅让另一个 follower,便于平滑的负载均衡。Pre vote:在竞选开始时先进行一轮预备竞选,若被允许再转变为 candidate,这样有助于防止某些异常节点扰乱整个集群的正常工作。Membership change:集群动态增删节点。Client interaction:客户端交互。Linearizable read:线性一致性读。Optimization:业界常见优化。- …
节点类型
Raft 将所有节点分为三个身份:
Leader:集群内最多只会有一个 leader,负责发起心跳,响应客户端,创建日志,同步日志。Candidate:leader 选举过程中的临时角色,由 follower 转化而来,发起投票参与竞选。Follower:接受 leader 的心跳和日志同步数据,投票给 candidate。
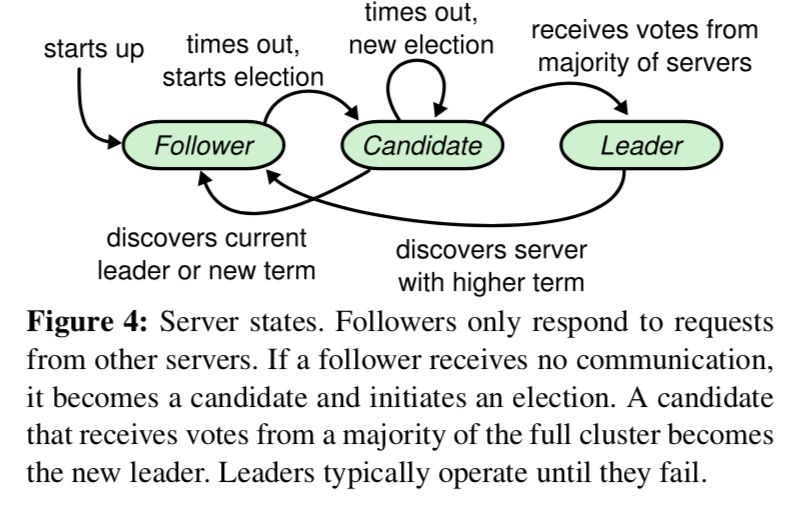
上图可以看出 Raft 中节点状态之间变迁的条件。
在博士论文和实际生产系统中,其实又增加了两种身份:
Learner:不具有选举权,参与日志复制过程但不计数的节点。可以作为新节点加入集群时的过渡状态以提升可用性,也可以作为一种类似于 binlog 的对 leader 日志流进行订阅的角色,比如可以参考 PingCAP 公司 tikv 和 tiflash 的架构。Pre candidate:刚刚发起竞选,还在等待Pre-Vote结果的临时状态, 取决于Pre-Vote的结果,可能进化为 candidate,可能退化为 follower。
节点状态
每一个节点都应该有的持久化状态:
currentTerm:当前任期,保证重启后任期不丢失。votedFor:在当前 term,给哪个节点投了票,值为 null 或candidate id。即使节点重启,Raft 算法也能保证每个任期最多只有一个 leader。log[]:已经 committed 的日志,保证状态机可恢复。
每一个节点都应该有的非持久化状态:
commitindex:已提交的最大 index。leader 节点重启后可以通过 appendEntries rpc 逐渐得到不同节点的 matchIndex,从而确认 commitIndex,follower 只需等待 leader 传递过来的 commitIndex 即可。lastApplied:已被状态机应用的最大 index。raft 算法假设了状态机本身是易失的,所以重启后状态机的状态可以通过 log[] (部分 log 可以压缩为 snapshot) 来恢复。
leader 的非持久化状态:
nextindex[]:为每一个 follower 保存的,应该发送的下一份entry index;初始化为本地 last index + 1。matchindex[]:已确认的,已经同步到每一个 follower 的entry index。初始化为 0,根据复制状态不断递增,
(注:每次选举后,leader 的此两个数组都应该立刻重新初始化并开始探测)
任期
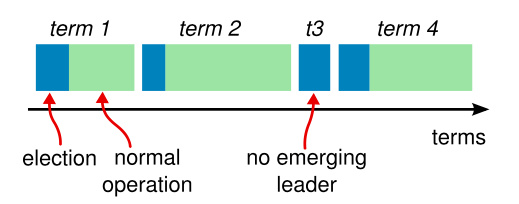
Raft 将时间划分成为任意不同长度的 term。term 用连续的数字进行表示。每一个 term 的开始都是一次选举,一个或多个 candidate 会试图成为 leader。如果一个 candidate 赢得了选举,它就会在该 term 担任 leader。在某些情况下,选票会被均分,即 split vote(例如总数为偶数节点时两个 candidate 节点各获得了两票),此时无法选出该 term 的 leader,那么在该 term 的选举超时后将会开始另一个 term 的选举。
不同的服务器节点可能多次观察到 term 之间的转换,但在某些情况下,一个节点也可能观察不到任何一次选举或者整个 term 全程。term 在 Raft 算法中充当逻辑时钟(类似于 Lamport timestamp)的作用,这会允许服务器节点查明一些过期的信息比如过期的 leader。
每个节点都会存储当前 term 号,这一编号在整个时间内单调增长。当服务器之间通信的时候会交换当前 term 号;如果一个服务器的当前 term 号比其他人小,那么他会更新自己的 term 到较大的 term 值。如果一个 candidate 或者 leader 发现自己的 term 过期了,那么他会立即退回 follower。如果一个节点接收到一个包含过期 term 号的请求,那么它会拒绝或忽略这个请求。这实际上就是一个 Lamport 逻辑时钟的具体实现。
日志
entry:Raft 中,将每一个事件都称为一个 entry,每一个 entry 都有一个表明它在 log 中位置的 index(之所以从 1 开始是为了方便prevLogIndex从 0 开始)。只有 leader 可以创建 entry。entry 的内容为<term, index, cmd>,其中 cmd 是可以应用到状态机的操作。在 raft 组大部分节点都接收这条 entry 后,entry 可以被称为是 committed 的。log:由 entry 构成的数组,只有 leader 可以改变其他节点的 log。 entry 总是先被 leader 添加进本地的 log 数组中去,然后才发起共识请求,获得 quorum 同意后才会被 leader 提交给状态机。follower 只能从 leader 获取新日志和当前的 commitIndex,然后应用对应的 entry 到自己的状态机。
保证
Election Safety:每个 term 最多只会有一个 leader;集群同时最多只会有一个可以读写的 leader。Leader Append-Only:leader 的日志是只增的。Log Matching:如果两个节点的日志中有两个 entry 有相同的 index 和 term,那么它们就是相同的 entry。Leader Completeness:一旦一个操作被提交了,那么在之后的 term 中,该操作都会存在于日志中。State Machine Safety:一致性,一旦一个节点应用了某个 index 的 entry 到状态机,那么其他所有节点应用的该 index 的操作都是一致的。
领导人选举
Raft 使用心跳来维持 leader 身份。任何节点都以 follower 的身份启动。 leader 会定期的发送心跳给所有的 follower 以确保自己的身份。 每当 follower 收到心跳后,就刷新自己的 electionElapsed,重新计时。
(后文中,会将预设的选举超时称为 electionTimeout,而将当前经过的选举耗时称为 electionElapsed)
一旦一个 follower 在指定的时间内没有收到任何 RPC(称为 electionTimeout),则会发起一次选举。 当 follower 试图发起选举后,其身份转变为 candidate,在增加自己的 term 后, 会向所有节点发起 RequestVoteRPC 请求,candidate 的状态会一直持续直到:
- 赢得选举
- 其他节点赢得选举
- 一轮选举结束,无人胜出
选举的方式非常简单,谁能获取到多数选票 (N/2 + 1),谁就成为 leader。 在一个 candidate 节点等待投票响应的时候,它有可能会收到其他节点声明自己是 leader 的心跳, 此时有两种情况:
- 该请求的 term 和自己一样或更大:说明对方已经成为 leader,自己立刻退为 follower。
- 该请求的 term 小于自己:拒绝请求并返回当前 term 以让请求节点更新 term。
为了防止在同一时间有太多的 follower 转变为 candidate 导致无法选出绝对多数, Raft 采用了随机选举超时(randomized election timeouts)的机制, 每一个 candidate 在发起选举后,都会随机化一个新的选举超时时间, 一旦超时后仍然没有完成选举,则增加自己的 term,然后发起新一轮选举。 在这种情况下,应该能在较短的时间内确认出 leader。 (因为 term 较大的有更大的概率压倒其他节点)
etcd 中将随机选举超时设置为 [electiontimeout, 2 * electiontimeout - 1]。
通过一个节点在一个 term 只能给一个节点投票,Raft 保证了对于给定的一个 term 最多只有一个 leader,从而避免了选举导致的 split brain 以确保 safety;通过不同节点每次随机化选举超时时间,Raft 在实践中(注意:并没有在理论上)避免了活锁以确保 liveness。
以下是 6.824 lab2 中选举相关逻辑的具体实现,以供参考。
1 | |
日志同步
leader 被选举后,则负责所有的客户端请求。每一个客户端请求都包含一个命令,该命令可以被作用到 RSM。
leader 收到客户端请求后,会生成一个 entry,包含 <index, term, cmd>,再将这个 entry 添加到自己的日志末尾后,向所有的节点广播该 entry。
follower 如果同意接受该 entry,则在将 entry 添加到自己的日志后,返回同意。
如果 leader 收到了多数的成功答复,则将该 entry 应用到自己的 RSM, 之后可以称该 entry 是 committed 的。该 committed 信息会随着随后的 AppendEntries 或 Heartbeat RPC 被传达到其他节点。
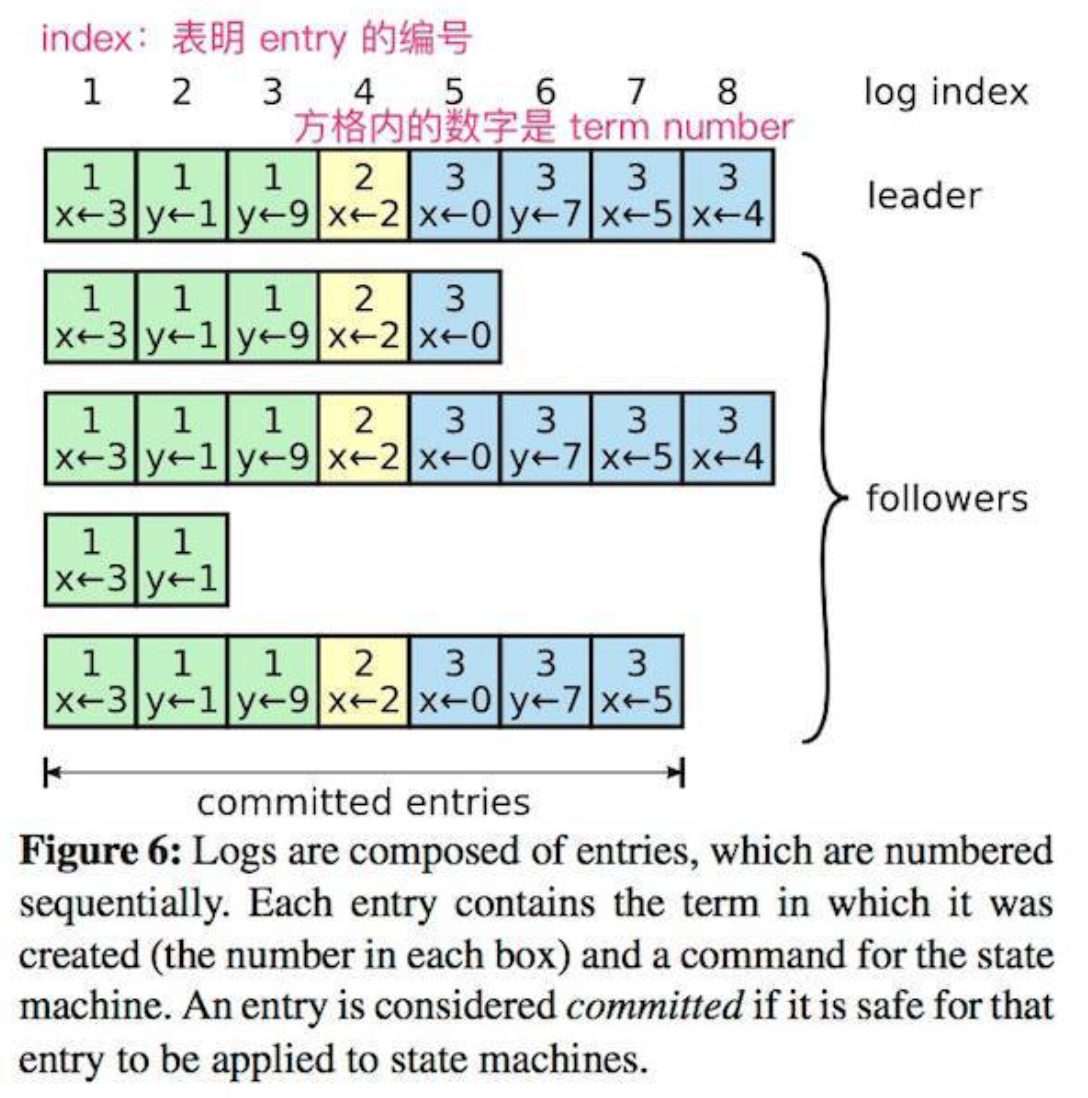
Raft 保证下列两个性质:
- 如果在两个日志(节点)里,有两个 entry 拥有相同的 index 和 term,那么它们一定有相同的 cmd;
- 如果在两个日志(节点)里,有两个 entry 拥有相同的 index 和 term,那么它们前面的 entry 也一定相同。
通过”仅有 leader 可以生成 entry”来确保第一个性质, 第二个性质则通过一致性检查(consistency check)来保证,该检查包含几个步骤:
leader 在通过 AppendEntriesRPC 和 follower 通讯时,会带上上一块 entry 的信息, 而 follower 在收到后会对比自己的日志,如果发现这个 entry 的信息(index、term)和自己日志内的不符合,则会拒绝该请求。一旦 leader 发现有 follower 拒绝了请求,则会与该 follower 再进行一轮一致性检查, 找到双方最大的共识点,然后用 leader 的 entries 记录覆盖 follower 所有在最大共识点之后的数据。
寻找共识点时,leader 还是通过 AppendEntriesRPC 和 follower 进行一致性检查, 方法是发送再上一块的 entry, 如果 follower 依然拒绝,则 leader 再尝试发送更前面的一块,直到找到双方的共识点。 因为分歧发生的概率较低,而且一般很快能够得到纠正,所以这里的逐块确认一般不会造成性能问题。当然,在这里进行二分查找或者某些规则的查找可能也能够在理论上得到收益。
每个 leader 都会为每一个 follower 保存一个 nextIndex 的变量, 标志了下一个需要发送给该 follower 的 entry 的 index。 在 leader 刚当选时,该值初始化为该 leader 的 log 的 index+1。 一旦 follower 拒绝了 entry,则 leader 会执行 nextIndex—,然后再次发送。直到 follower 接收后将 matchIndex 设置为此时的 nextIndex - 1,然后开始正常的复制。这里还可以做一些更细粒度的优化,比如在正常复制时可以批量复制日志以减少系统调用的开销;在寻找共识点时可以只携带一条日志以减少不必要的流量传输,具体可以参考 etcd 的 设计。
以下是 6.824 lab2 中 日志同步相关逻辑的具体实现,以供参考。
1 | |
安全
选举限制
因为 leader 的强势地位,所以 Raft 在投票阶段就确保选举出的 leader 一定包含了整个集群中目前已 committed 的所有日志。
当 candidate 发送 RequestVoteRPC 时,会带上最后一个 entry 的信息。 所有的节点收到该请求后,都会比对自己的日志,如果发现自己的日志更新一些,则会拒绝投票给该 candidate。 (Pre-Vote 同理,如果 follower 认为 Pre-Candidate 没有资格的话,会拒绝 PreVote)
判断日志新旧的方式:获取请求的 entry 后,比对自己日志中的最后一个 entry。 首先比对 term,如果自己的 term 更大,则拒绝请求。 如果 term 一样,则比对 index,如果自己的 index 更大(说明自己的日志更长),则拒绝请求。
1 | |
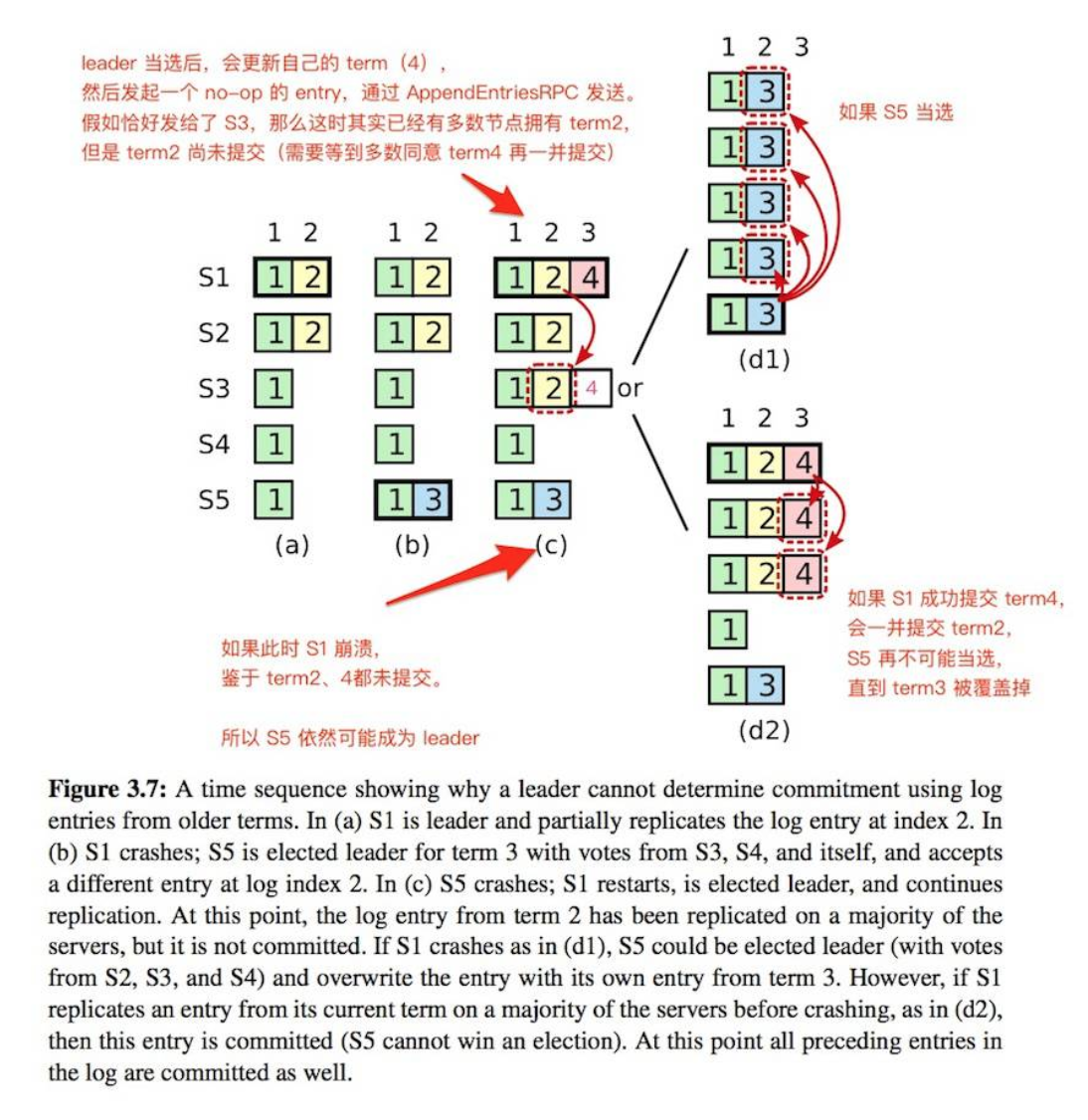
在上图中,raft 为了避免出现一致性问题,要求 leader 绝不会提交过去的 term 的 entry (即使该 entry 已经被复制到了多数节点上)。leader 永远只提交当前 term 的 entry, 过去的 entry 只会随着当前的 entry 被一并提交。(上图中的 c,term2 只会跟随 term4 被提交。)
如果一个 candidate 能取得多数同意,说明它的日志已经是多数节点中最完备的, 那么也就可以认为该 candidate 已经包含了整个集群的所有 committed entries。
因此 leader 当选后,应当立刻发起 AppendEntriesRPC 提交一个 no-op entry。注意,这是一个 Must,不是一个 Should,否则会有许多 corner case 存在问题。比如:
- 读请求:leader 此时的状态机可能并不是最新的,若服务读请求可能会违反线性一致性,即出现 safety 的问题;若不服务读请求则可能会有 liveness 的问题。
- 配置变更:可能会导致数据丢失,具体原因和例子可以参考此 博客。
实际上,leader 当选后提交一个 no-op entry 日志的做法就是 Raft 算法解决 “幽灵复现” 问题的解法,感兴趣的可以看看此 博客。
节点崩溃
如果 leader 崩溃,集群中的所有节点在 electionTimeout 时间内没有收到 leader 的心跳信息就会触发新一轮的选主。总而言之,最终集群总会选出唯一的 leader 。按论文中的说法,计算一次 RPC 耗时高达 30~40ms 时,99.9% 的选举依然可以在 3s 内完成,但一般一个机房内一次 RPC 只需 1ms。当然,选主期间整个集群对外是不可用的。
如果 follower 和 candidate 奔溃相对而言就简单很多, 因为 Raft 所有的 RPC 都是幂等的,所以 Raft 中所有的请求,只要超时,就会无限的重试。follower 和 candidate 崩溃恢复后,可以收到新的请求,然后按照上面谈论过的追加或拒绝 entry 的方式处理请求。
时间与可用性
Raft 原则上可以在绝大部分延迟情况下保证一致性, 不过为了保证选择和 leader 的正常工作,最好能满足下列时间条件:
1 | |
broadcastTime:向其他节点并发发送消息的平均响应时间;electionTimeout:follower 判定 leader 已经故障的时间(heartbeat 的最长容忍间隔);MTBF(mean time between failures):单台机器的平均健康时间;
一般来说,broadcastTime 一般为 0.5~20ms,electionTimeout 可以设置为 10~500ms,MTBF 一般为一两个月。
日志压缩
Raft 的日志在正常运行期间会增长以合并更多的客户请求,但是在实际的系统中,Raft 的日志无法不受限制地增长。随着日志的增长,日志会占用更多空间,并且需要花费更多时间进行重放。如果没有某种机制可以丢弃日志中累积的过时信息,这最终将导致可用性问题。因此需要定时去做 snapshot。
snapshot 会包括:
- 状态机当前的状态。
- 状态机最后一条应用的 entry 对应的 index 和 term。
- 集群最新配置信息。
- 为了保证 exactly-once 线性化语义的去重表(之后会介绍到)。
各个节点自行择机完成自己的 snapshot 即可,如果 leader 发现需要发给某一个 follower 的 nextIndex 已经被做成了 snapshot,则需要将 snapshot 发送给该 follower。注意 follower 拿到非过期的 snapshot 之后直接覆盖本地所有状态即可,不需要留有部分 entry,也不会出现 snapshot 之后还存在有效的 entry。因此 follower 只需要判断 InstallSnapshot RPC 是否过期即可。过期则直接丢弃,否则直接替换全部状态即可。
snapshot 可能会带来两个问题:
做 snapshot 的策略?
一般为定时或者定大小,达到阈值即做 snapshot,做完后对状态机和 raft log 进行原子性替换即可。做 snapshot 时是否还可继续提供写请求?
一般情况下,做 snapshot 期间需要保证状态机不发生变化,也就是需要保证 snapshot 期间状态机不处理写请求。当然 raft 层依然可以去同步,只是状态机不能变化,即不能 apply 新提交的日志到状态机中而已。要想做的更好,可以对状态机采用copy-on-write的复制来不阻塞写请求。
以下是 6.824 lab2 中 日志压缩相关逻辑的具体实现,以供参考。
1 | |
禅让
有时候,会希望取消当前 leader 的管理权,比如:
- leader 节点因为运维原因需要重启;
- 有其他更适合当 leader 的节点;
直接将 leader 节点停机的话,其他节点会等待 electionTimeout 后进入选举状态, 这期间会集群会停止响应。为了避免这一段不可用的时间,可以采用禅让机制(leadership transfer)。
禅让的步骤为:
- leader 停止响应客户端请求;
- leader 向 target 节点发起一次日志同步;
- leader 向 target 发起一次 TimeoutNowRPC,target 收到该请求后立刻发起一轮投票。
etcd 中实现了更多的细节(也有一些改动):
- leader 先检查禅让对象(leadTransferee)的身份,如果是 follower,直接忽略;
- leader 检查是否有正在进行的禅让,如果有,则中止之前的禅让状态,开始处理最新的请求;
- 检查禅让对象是否是自己,如果是,忽略;
- 将禅让状态信息计入 leader 的状态,并且重置 electionElapsed(因为禅让应该在 electionTimeout 内完成);
- 检查禅让对象的日志是否是最新的
- 如果禅让对象已经是最新,则直接发送 TimeoutNowRPC
- 如果不是,则发送 AppendEntriesRPC,待节点响应成功后,再发送 TimeoutNowRPC
可以看出,在 etcd 中,leader 除了重置 electionElapsed 外,不会改动自己的状态。 既不会停止对客户端的响应,同时还会继续发送心跳。
因为 target 机器会更新自己的 term,而且率先发起投票,其有很大的概率赢得选举。 需要注意的是,target 发起的 RequestVoteRPC 中的 isLeaderTransfer=true, 以防止被其他节点忽略。
如果 target 机器没能在一次 electionTimeout 内完成选举,那么 leader 认为本次禅让失败, 立刻恢复响应客户端的请求。(这时可以再次重新发起一次禅让请求)
在 etcd/raft 中,RequestVoteRPC.context 会被设置为 campaignTransfer, 表明本次投票请求来源于 leader transfer,可以强行打断 follower 的租约发起选举。
预投票
一个暂时脱离集群网络的节点,在重新加入集群后会干扰到集群的运行。
因为当一个节点和集群失去联系后,在等待 electionTimeout 后,它就会增加自己的 term 并发起选举, 因为联系不上其他节点,所以在 electionTimeout 后,它会继续增加自己的 term 并继续发起选举。
一段时间以后,它的 term 就会显著的高于原集群的 term。如果此后该节点重新和集群恢复了联络, 它的高 term 会导致 leader 立刻退位,并重新举行选举。
为了避免这一情形,引入了 Pre-Vote 的机制。在该机制下,一个 candidate 必须在获得了多数赞同的情形下, 才会增加自己的 term。一个节点在满足下述条件时,才会赞同一个 candidate:
- 该 candidate 的日志足够新;
- 当前节点已经和 leader 失联(electionTimeout)。
也就是说,candidate 会先发起一轮 Pre-Vote,获得多数同意后,更新自己的 term, 再发起一轮 RequestVoteRPC。
这种情形下,脱离集群的节点,只会不断的发起 Pre-Vote,而不会更新自己的 term。
在 etcd 的实现中,如果某个节点赞同了某个 candidate, 是不需要更新自己的状态的,它依然可以赞同其他 candidate。 而且,即使收到的 PreVote 的 term 大于自己,也不会更新自己的 term。 也就是说,PreVote 不会改变其他节点的任何状态。
etcd 中还有一个设计是,当发起 PreVote 的时候,针对的是下一轮的 term, 所以会向所有的节点发送一个 term+1 的 PreVoteReq。
1 | |
配置变更
raft 的配置变更一般分为两种方式:一次变更一个和一次变更多个,前者实现相对简单(谬误,其实并不简单,感兴趣可以参考该 博客),改动多个节点的配置变更可以被分成多个一次变更一个来执行;后者相对复杂,并且在某些场景下可用性更强,具体可参考 TiDB 5.0 的 介绍。
以下仅会简单介绍两种成员变更方式,具体可以参考 raft 作者博士论文的 第四章 和 Raft 成员变更的工程实践。
一次变更一台
因为在 Raft 算法中,集群中每一个节点都存有整个集群的信息,而集群的成员有可能会发生变更(节点增删、替换节点等)。 Raft 限制一次性只能增/删一个节点,在一次变更结束后,才能继续进行下一次变更。
如果一次性只变更一个节点,那么只需要简单的要求“在新/旧集群中,都必须取得多数(N/2+1)”, 那么这两个多数中必然会出现交集,这样就可以保证不会因为配置不一致而导致脑裂。
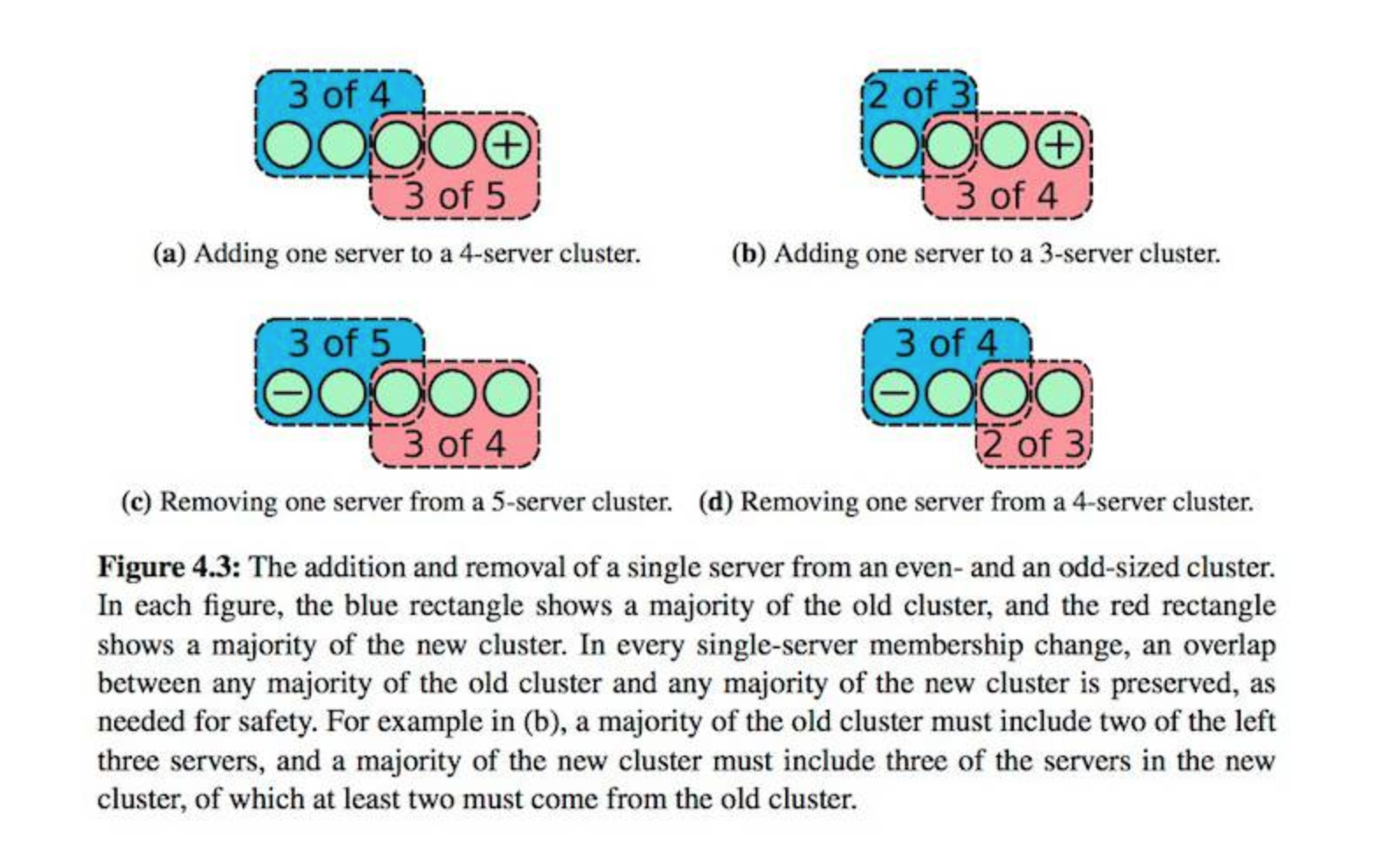
当 leader 收到集群变更的请求后,就会生成一个特殊的 entry 项用来保存配置, 在将配置项添加到 log 后,该配置立刻生效(也就是说任何节点在收到新配置后,就立刻启用新配置)。 然后 leader 将该 entry 扩散至多数节点,成功后则提交该 entry。 一旦一个新配置项被 committed,则视为该次变更已结束,可以继续处理下一次变更了。
为了保证可用性,需要新增一项规则,节点在响应 RPC 时,不考虑来源节点是否在自己的配置文件之中。 也就是说,即使收到了一个并不在自己配置文件之中的节点发来的 RPC, 也需要正常处理和响应,包括 AppendEntriesRPC 和 RequestVoteRPC。
一次变更多台
这种变更方式可以一次性变更多个节点(arbitrary configuration)。
当集群成员在变更时,为了保证服务的可用性(不发生中断),以及避免因为节点变更导致的一致性问题, Raft 提出了两阶段变更,当接收到新的配置文件后,集群会首先进入 joint consensus 状态, 待新的配置文件提交成功后,再回到普通状态。
更具体的,joint consensus 指的是包含新/旧配置文件全部节点的中间状态:
- entries 会被复制到新/旧配置文件中的所有节点;
- 新/旧配置文件中的任何一个节点都有可能被选为 leader;
- 共识(选举或提交)需要同时在新/旧配置文件中分别获取到多数同意(
separate majorities)
(注:separate majorities的意思是需要新/旧集群中的多数都同意。比如如果是从 3 节点切换为全新的 9 节点, 那么要求旧配置中的 2 个节点,和新配置中的 5 个节点都同意,才被认为达成了一次共识)
所以,在一次配置变更中,一共有三个状态:
C_old:使用旧的配置文件;C_old,new:同时使用新旧配置文件,也就是新/旧节点的并集;C_new:使用新的配置文件。
配置文件使用特殊的 entries 进行存储,一个节点一旦获取到新的配置文件, 即使该配置 entry 并没有 committed,也会立刻使用该配置。 所以一次完整的配置变更可以表示为下图:
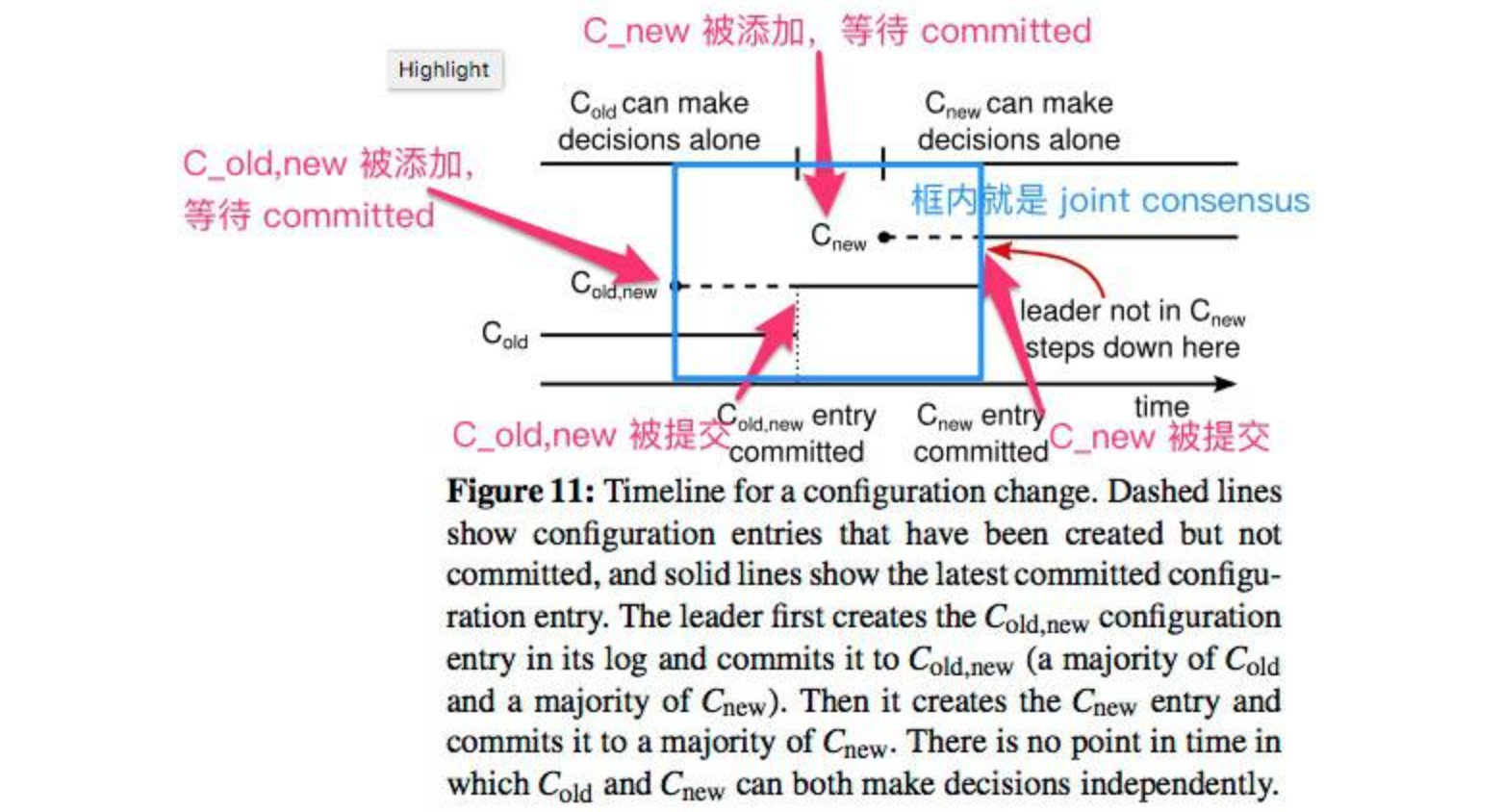
- C_old,new 被创建,集群进入 joint consensus,leader 开始传播该 entry;
- C_old,new 被 committed,也就是说此时多数节点都拥有了 C_old,new,此后 C_old 已经不再可能被选为 leader;
- leader 创建并传播 C_new;
- C_new 被提交,此后不在 C_new 内的节点不允许被选为 leader,如有 leader 不在 C_new 则自行退位。
注意事项
不在 C_new 的节点可能会干扰集群。
当 C_new 开始生效后,被移除的节点就会收不到 heartbeat,所以在 electionTimeout 后, 这些节点会更新自己的 term 然后开始尝试竞选,这会导致目前的 leader 被迫退回 follower 并启动一轮投票。 这会反复发生,严重影响效率。
解决办法是,每一个 follower 增加一个机制,当节点处于 minimum election timeout 之内时, 也就是当一个节点认为自己的 leader 依然存活时,将会拒绝 RequestVoteRPC,既不会同意投票, 也不会根据 RequestVoteRPC 更新自己的 term。
但如果此时集群正好处于选举之中,那么 C_old 集群的节点可能还是会造成干扰, 所以结合 PreVote 更为可靠。
这一机制会干扰到 leader transfer 机制,因为在 leader transfer 中,即使 electionTimeout 未到, RequestVoteRPC 也应该打断所有的节点,要求立刻开始进行选举。 所以需要给 RequestVoteRPC 增加一个 flag 来表明是否来自于 leader transfer。
etcd 中也是增加了一个 flag campaignTransfer 来做特殊标记,见上面的「禅让」一节。
客户端交互
虽然说 raft 算法只是一个 RSM,其只需要保证不同节点上的日志相同即可,其他的事情它都不需要关心。但是要想保证线性一致性语义,对于基于 raft 的 KV 往往还需要额外做一些事情,比如即使客户端会超时重试,也要保证日志的 exactly-once 执行。
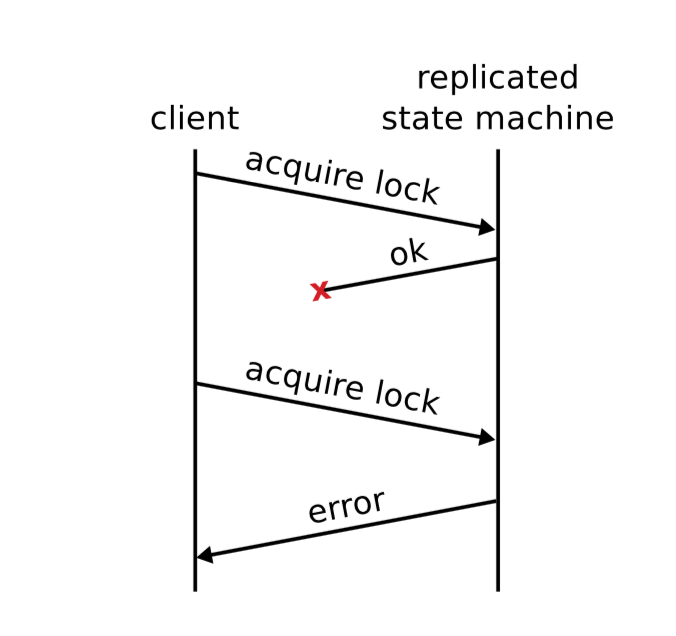
考虑这样一个场景,客户端向服务端提交了一条日志,服务端将其在 raft 组中进行了同步并成功 commit,接着在 apply 后返回给客户端执行结果。然而不幸的是,该 rpc 在传输中发生了丢失,客户端并没有收到写入成功的回复。因此,客户端只能进行重试直到明确地写入成功或失败为止,这就可能会导致相同地命令被执行多次,从而违背线性一致性。
有人可能认为,只要写请求是幂等的,那重复执行多次也是可以满足线性一致性的,实际上则不然。考虑这样一个例子:对于一个仅支持 put 和 get 接口的 raftKV 系统,其每个请求都具有幂等性。设 x 的初始值为 0,此时有两个并发客户端,客户端 1 执行 put(x,1),客户端 2 执行 get(x) 再执行 put(x,2),问(客户端 2 读到的值,x 的最终值)是多少。对于线性一致的系统,答案可以是 (0,1),(0,2) 或 (1,2)。然而,如果客户端 1 执行 put 请求时发生了上段描述的情况,然后客户端 2 读到 x 的值为 1 并将 x 置为了 2,最后客户端 1 超时重试且再次将 x 置为 1。对于这种场景,答案是 (1,1),这就违背了线性一致性。归根究底还是由于幂等的 put(x,1) 请求在状态机上执行了两次,有两个 LZ 点。因此,即使写请求的业务语义能够保证幂等,不进行额外的处理让其重复执行多次也会破坏线性一致性。当然,读请求由于不改变系统的状态,重复执行多次是没问题的。
对于这个问题,raft 作者介绍了想要实现线性化语义,就需要保证日志仅被执行一次,即它可以被 commit 多次,但一定只能 apply 一次。其解决方案原文如下:
The solution is for clients to assign unique serial numbers to every command. Then, the state machine tracks the latest serial number processed for each client, along with the associated response. If it receives a command whose serial number has already been executed, it responds immediately without re-executing the request.
基本思路便是:
- 每个 client 都需要一个唯一的标识符,它的每个不同命令需要有一个顺序递增的 commandId,clientId 和这个 commandId,clientId 可以唯一确定一个不同的命令,从而使得各个 raft 节点可以记录保存各命令是否已应用以及应用以后的结果。
为什么要记录应用的结果?因为通过这种方式同一个命令的多次 apply 最终只会实际应用到状态机上一次,之后相同命令 apply 的时候实际上是不应用到状态机上的而是直接返回的,那么这时候应该返回什么呢?直接返回成功吗?不行,如果第一次应用时状态机报了什么例如 key not exist 等业务上的错而没有被记录,之后就很难捕捉到这个执行结果了,所以也需要将应用结果保存下来。
如果默认一个客户端只能串行执行请求的话,服务端这边只需要记录一个 map,其 key 是 clientId,其 value 是该 clientId 执行的最后一条日志的 commandId 和状态机的输出即可。
raft 论文中还考虑了对这个 map 进行一定大小的限制,防止其无线增长。这就带来了两个问题:
- 集群间的不同节点如何就某个 clientId 过期达成共识。
- 不小心驱逐了活跃的 clientId 怎么办,其之后不论是新建一个 clientId 还是复用之前的 clientId 都可能导致命令的重执行。
这些问题在工程实现上都较为麻烦。比如后者如果业务上是事务那直接 abort 就行,但如果不是事务就很难办了。
实际上,个人感觉 clientId 是与 session 绑定的,其生命周期应该与 session 一致,开启 session 时从 map 中保存该 clientId,关闭 session 时从 map 中删除该 clientId 及其对应的 value 即可。map 中一个 clientId 对应的内存占用可能都不足 30 字节,相比携带更多业务语义的 session 其实很小,所以感觉没太大必要去严格控制该 map 的内存占用,还不如考虑下怎么控制 session 更大地内存占用呢。这样就不用去纠结前面提到的两个问题了。
感兴趣的可以参照 raft 博士论文第六章-客户端交互 和 dragonboat 作者在知乎上对其的 讨论。
线性一致性读
有关 raft 一致性读的实现,可以参考本人写的另一篇 博客。
优化
业界的实践很多,可以参考 tikv 的 优化 和 dragonboat 的 优化。
以下简单列举几种:
- batching:降低 system call 的开销。
- pipeline:提升 leader 向 follower 同步的吞吐量。
- 异步 apply:提升 raft 算法吞吐量。无法降低延迟,但能增加吞吐量。
- 并行同步日志与刷盘:并行 IO,提升 raft 算法吞吐量。
- …
接口
所有节点间仅通过三种类型的 RPC 进行通信:
AppendEntriesRPC:最常用的,leader 向 follower 发送心跳或同步日志。RequestVoteRPC:选举时,candidate 发起的竞选请求。InstallsnapshotRPC:用于 leader 下发 snapshot。
在 Diego 后续的博士论文中,又增加了一些 RPCs:
AddServerRPC:添加单台节点。RemoveServerRPC:移除一个节点。TimeoutNowRPC:立刻发起竞选。
(实际上 etcd 的实现中定义了几十种消息类型,甚至把内部事件也封装为消息一并处理。)
AppendEntriesRPC
参数:
term:leader 当前的 term;leaderId:leader 的 节点 id,让 follower 可以重定向客户端的连接;prevLogIndex:前一块 entry 的 index;prevlogterm:前一块 entry 的 term;entries[]:给 follower 发送的 entry,可以一次发送多个,heartbeat 时该项可缺省;leaderCommit:leader 当前的committed index,follower 收到后可用于自己的状态机。
返回:
term:响应者自己的 term;success:bool,是否接受请求。
该请求通过 leaderCommit 通知 follower 提交相应的 entries 到。通过 entries[] 复制 leader 的日志到所有的 follower。
实现细节:
- 如果
term < currentTerm,立刻返回 false - 如果 prevLogIndex 不匹配,返回 false
- 如果自己有块 entry 和新的 entry 不匹配(在相同的 index 上有不同的 term), 删除自己的那一块以及之后的所有 entry;
- 把新的 entries 添加到自己的 log;
5 。如果leaderCommit > commitindex,将 commitIndex 设置为min(leaderCommit, last index), 并且提交相应的 entries。
RequestVoteRPC
参数:
term:candidate 当前的 term;candidateId:candidate 的节点 idlastlogindex:candidate 最后一个 entry 的 index;lastlogterm:candidate 最后一个 entry 的 term。isleaderTransfer:用于表明该请求来自于禅让,无需等待 electionTimeout,必须立刻响应。isPreVote:用来表明当前是 PreVote 还是真实投票
返回:
term:响应者当前的 term;voteGranted:bool,是否同意投票。
实现细节:
- 如果
term < currentTerm,返回 false; - 如果 votedFor 为空或者为该
candidated id,且日志项不落后于自己,则同意投票。
InstallsnapshotRPC
参数:
term:leader 的 termleaderId:leader 的 节点 idlastIncludedindex:snapshot 中最后一块 entry 的 index;lastIncludedterm:snapshot 中最后一块 entry 的 term;offset:该份 chunk 的 offset;data[]:二进制数据;done:是否是最后一块 chunk
返回:
term:follower 当前的 term
实现细节:
- 如果
term < currentTerm就立即回复 - 如果是第一个分块(offset 为 0)就创建一个新的快照
- 在指定偏移量写入数据
- 如果 done 是 false,则继续等待更多的数据
- 保存快照文件,丢弃索引值小于快照的日志
- 如果现存的日志拥有相同的最后任期号和索引值,则后面的数据继续保持
- 丢弃整个日志
- 使用快照重置状态机
AddServerRPC
参数:
newServer:新节点地址
返回:
status:bool,是否添加成功;leaderHint:当前 leader 的信息。
实现细节:
- 如果节点不是 leader,返回 NOT_LEADER;
- 如果没有在 electionTimeout 内处理,则返回 TIMEOUT;
- 等待上一次配置变更完成后,再处理当前变更;
- 将新的配置项加入 log,然后发起多数共识,通过后再提交;
- 返回 OK。
RemoveServerRPC
参数:
oldServer:要删除的节点的地址
返回:
status:bool,是否删除成功;leaderHint:当前 leader 的信息。
实现细节:
- 如果节点不是 leader,返回 NOT_LEADER;
- 等待上一次配置变更完成后,再处理当前变更;
- 将新的配置项加入 log,然后发起多数共识,通过后再提交;
- 返回 OK。
TimeoutNowRPC
由 leader 发起,告知 target 节点立刻发起竞选,无视 electionTimeout。主要用于禅让。
总结
本篇博客较为详细的介绍了 raft 算法的实现,希望能对读者理解 raft 算法有所帮助。