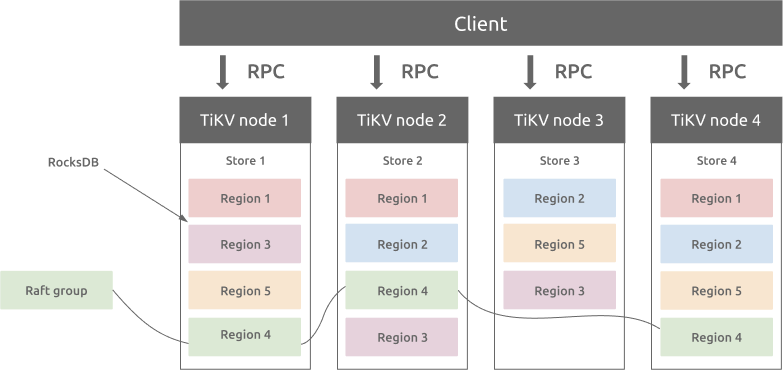
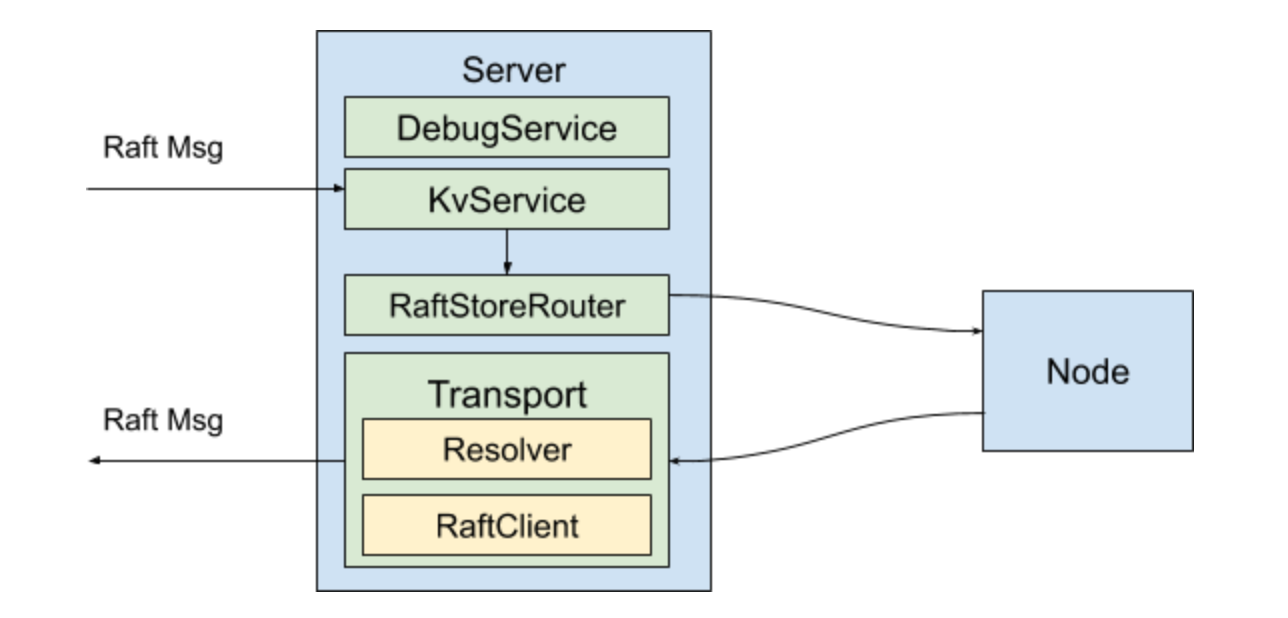
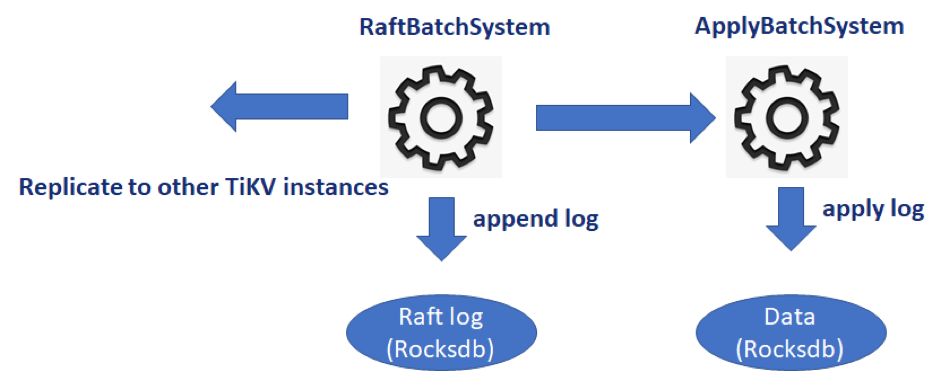
/// Run a TiKV server. Returns when the server is shutdown by the user, in which /// case the server will be properly stopped. pubfnrun_tikv(config: TikvConfig) {
...
// Do some prepare works before start. pre_start();
/// Scheduler which schedules the execution of `storage::Command`s. #[derive(Clone)] pubstructScheduler<E: Engine, L: LockManager> { inner: Arc<SchedulerInner<L>>, // The engine can be fetched from the thread local storage of scheduler threads. // So, we don't store the engine here. _engine: PhantomData<E>, }
structSchedulerInner<L: LockManager> { // slot_id -> { cid -> `TaskContext` } in the slot. task_slots: Vec<CachePadded<Mutex<HashMap<u64, TaskContext>>>>,
// cmd id generator id_alloc: CachePadded<AtomicU64>,
// write concurrency control latches: Latches,
sched_pending_write_threshold: usize,
// worker pool worker_pool: SchedPool,
// high priority commands and system commands will be delivered to this pool high_priority_pool: SchedPool,
// used to control write flow running_write_bytes: CachePadded<AtomicUsize>,
// It stores context of a task. structTaskContext { task: Option<Task>,
lock: Lock, cb: Option<StorageCallback>, pr: Option<ProcessResult>, // The one who sets `owned` from false to true is allowed to take // `cb` and `pr` safely. owned: AtomicBool, write_bytes: usize, tag: CommandKind, // How long it waits on latches. // latch_timer: Option<Instant>, latch_timer: Instant, // Total duration of a command. _cmd_timer: CmdTimer, }
/// Latches which are used for concurrency control in the scheduler. /// /// Each latch is indexed by a slot ID, hence the term latch and slot are used /// interchangeably, but conceptually a latch is a queue, and a slot is an index /// to the queue. pubstructLatches { slots: Vec<CachePadded<Mutex<Latch>>>, size: usize, }
/// Tries to acquire the latches specified by the `lock` for command with ID /// `who`. /// /// This method will enqueue the command ID into the waiting queues of the /// latches. A latch is considered acquired if the command ID is the first /// one of elements in the queue which have the same hash value. Returns /// true if all the Latches are acquired, false otherwise. pubfnacquire(&self, lock: &mut Lock, who: u64) ->bool { letmut acquired_count: usize = 0; for &key_hash in &lock.required_hashes[lock.owned_count..] { letmut latch = self.lock_latch(key_hash); match latch.get_first_req_by_hash(key_hash) { Some(cid) => { if cid == who { acquired_count += 1; } else { latch.wait_for_wake(key_hash, who); break; } } None => { latch.wait_for_wake(key_hash, who); acquired_count += 1; } } } lock.owned_count += acquired_count; lock.acquired() }
/// Releases all the latches held by a command. fnrelease_lock(&self, lock: &Lock, cid: u64) { letwakeup_list = self.inner.latches.release(lock, cid); forwcidin wakeup_list { self.try_to_wake_up(wcid); } }
/// Releases all latches owned by the `lock` of command with ID `who`, /// returns the wakeup list. /// /// Preconditions: the caller must ensure the command is at the front of the /// latches. pubfnrelease(&self, lock: &Lock, who: u64) ->Vec<u64> { letmut wakeup_list: Vec<u64> = vec![]; for &key_hash in &lock.required_hashes[..lock.owned_count] { letmut latch = self.lock_latch(key_hash); let (v, front) = latch.pop_front(key_hash).unwrap(); assert_eq!(front, who); assert_eq!(v, key_hash); ifletSome(wakeup) = latch.get_first_req_by_hash(key_hash) { wakeup_list.push(wakeup); } } wakeup_list }
/// Tries to acquire all the necessary latches. If all the necessary latches /// are acquired, the method initiates a get snapshot operation for further /// processing. fntry_to_wake_up(&self, cid: u64) { matchself.inner.acquire_lock_on_wakeup(cid) { Ok(Some(task)) => { fail_point!("txn_scheduler_try_to_wake_up"); self.execute(task); } Ok(None) => {} Err(err) => { // Spawn the finish task to the pool to avoid stack overflow // when many queuing tasks fail successively. letthis = self.clone(); self.inner .worker_pool .pool .spawn(asyncmove { this.finish_with_err(cid, err); }) .unwrap(); } } }
/// A `Fsm` is a finite state machine. It should be able to be notified for /// updating internal state according to incoming messages. pubtraitFsm { typeMessage: Send;
fnis_stopped(&self) ->bool;
/// Set a mailbox to FSM, which should be used to send message to itself. fnset_mailbox(&mutself, _mailbox: Cow<'_, BasicMailbox<Self>>) where Self: Sized, { } /// Take the mailbox from FSM. Implementation should ensure there will be /// no reference to mailbox after calling this method. fntake_mailbox(&mutself) ->Option<BasicMailbox<Self>> where Self: Sized, { None }
/// A unify type for FSMs so that they can be sent to channel easily. pubenumFsmTypes<N, C> { Normal(Box<N>), Control(Box<C>), // Used as a signal that scheduler should be shutdown. Empty, }
/// A handler that polls all FSMs in ready. /// /// A general process works like the following: /// /// loop { /// begin /// if control is ready: /// handle_control /// foreach ready normal: /// handle_normal /// light_end /// end /// } /// /// A [`PollHandler`] doesn't have to be [`Sync`] because each poll thread has /// its own handler. pubtraitPollHandler<N, C>: Send + 'static { /// This function is called at the very beginning of every round. fnbegin<F>(&mutself, _batch_size: usize, update_cfg: F) where for<'a> F: FnOnce(&'a Config);
/// This function is called when the control FSM is ready. /// /// If `Some(len)` is returned, this function will not be called again until /// there are more than `len` pending messages in `control` FSM. /// /// If `None` is returned, this function will be called again with the same /// FSM `control` in the next round, unless it is stopped. fnhandle_control(&mutself, control: &mut C) ->Option<usize>;
/// This function is called when some normal FSMs are ready. fnhandle_normal(&mutself, normal: &mutimplDerefMut<Target = N>) -> HandleResult;
/// This function is called after [`handle_normal`] is called for all FSMs /// and before calling [`end`]. The function is expected to run lightweight /// works. fnlight_end(&mutself, _batch: &mut [Option<implDerefMut<Target = N>>]) {}
/// This function is called at the end of every round. fnend(&mutself, batch: &mut [Option<implDerefMut<Target = N>>]);
/// This function is called when batch system is going to sleep. fnpause(&mutself) {}
/// This function returns the priority of this handler. fnget_priority(&self) -> Priority { Priority::Normal } }
大体来看,状态机分成两种,normal 和 control。对于每一个 Batch System,只有一个 control 状态机,负责管理和处理一些需要全局视野的任务。其他 normal 状态机负责处理其自身相关的任务。每个状态机都有其绑定的消息和消息队列。PollHandler 负责驱动状态机,处理自身队列中的消息。Batch System 的职责就是检测哪些状态机需要驱动,然后调用 PollHandler 去消费消息。消费消息会产生副作用,而这些副作用或要落盘,或要网络交互。PollHandler 在一个批次中可以处理多个 normal 状态机。
/// A system that can poll FSMs concurrently and in batch. /// /// To use the system, two type of FSMs and their PollHandlers need to be /// defined: Normal and Control. Normal FSM handles the general task while /// Control FSM creates normal FSM instances. pubstructBatchSystem<N: Fsm, C: Fsm> { name_prefix: Option<String>, router: BatchRouter<N, C>, receiver: channel::Receiver<FsmTypes<N, C>>, low_receiver: channel::Receiver<FsmTypes<N, C>>, pool_size: usize, max_batch_size: usize, workers: Arc<Mutex<Vec<JoinHandle<()>>>>, joinable_workers: Arc<Mutex<Vec<ThreadId>>>, reschedule_duration: Duration, low_priority_pool_size: usize, pool_state_builder: Option<PoolStateBuilder<N, C>>, }
/// Polls for readiness and forwards them to handler. Removes stale peers if /// necessary. pubfnpoll(&mutself) { fail_point!("poll"); letmut batch = Batch::with_capacity(self.max_batch_size); letmut reschedule_fsms = Vec::with_capacity(self.max_batch_size); letmut to_skip_end = Vec::with_capacity(self.max_batch_size);
// Fetch batch after every round is finished. It's helpful to protect regions // from becoming hungry if some regions are hot points. Since we fetch new FSM // every time calling `poll`, we do not need to configure a large value for // `self.max_batch_size`. letmut run = true; while run && self.fetch_fsm(&mut batch) { // If there is some region wait to be deal, we must deal with it even if it has // overhead max size of batch. It's helpful to protect regions from becoming // hungry if some regions are hot points. letmut max_batch_size = std::cmp::max(self.max_batch_size, batch.normals.len()); // Update some online config if needed. { // TODO: rust 2018 does not support capture disjoint field within a closure. // See https://github.com/rust-lang/rust/issues/53488 for more details. // We can remove this once we upgrade to rust 2021 or later edition. letbatch_size = &mutself.max_batch_size; self.handler.begin(max_batch_size, |cfg| { *batch_size = cfg.max_batch_size(); }); } max_batch_size = std::cmp::max(self.max_batch_size, batch.normals.len());
if batch.control.is_some() { letlen = self.handler.handle_control(batch.control.as_mut().unwrap()); if batch.control.as_ref().unwrap().is_stopped() { batch.remove_control(&self.router.control_box); } elseifletSome(len) = len { batch.release_control(&self.router.control_box, len); } }
letmut hot_fsm_count = 0; for (i, p) in batch.normals.iter_mut().enumerate() { letp = p.as_mut().unwrap(); letres = self.handler.handle_normal(p); if p.is_stopped() { p.policy = Some(ReschedulePolicy::Remove); reschedule_fsms.push(i); } elseif p.get_priority() != self.handler.get_priority() { p.policy = Some(ReschedulePolicy::Schedule); reschedule_fsms.push(i); } else { if p.timer.saturating_elapsed() >= self.reschedule_duration { hot_fsm_count += 1; // We should only reschedule a half of the hot regions, otherwise, // it's possible all the hot regions are fetched in a batch the // next time. if hot_fsm_count % 2 == 0 { p.policy = Some(ReschedulePolicy::Schedule); reschedule_fsms.push(i); continue; } } ifletHandleResult::StopAt { progress, skip_end } = res { p.policy = Some(ReschedulePolicy::Release(progress)); reschedule_fsms.push(i); if skip_end { to_skip_end.push(i); } } } } letmut fsm_cnt = batch.normals.len(); while batch.normals.len() < max_batch_size { ifletOk(fsm) = self.fsm_receiver.try_recv() { run = batch.push(fsm); } // When `fsm_cnt >= batch.normals.len()`: // - No more FSMs in `fsm_receiver`. // - We receive a control FSM. Break the loop because ControlFsm may change // state of the handler, we shall deal with it immediately after calling // `begin` of `Handler`. if !run || fsm_cnt >= batch.normals.len() { break; } letp = batch.normals[fsm_cnt].as_mut().unwrap(); letres = self.handler.handle_normal(p); if p.is_stopped() { p.policy = Some(ReschedulePolicy::Remove); reschedule_fsms.push(fsm_cnt); } elseifletHandleResult::StopAt { progress, skip_end } = res { p.policy = Some(ReschedulePolicy::Release(progress)); reschedule_fsms.push(fsm_cnt); if skip_end { to_skip_end.push(fsm_cnt); } } fsm_cnt += 1; } self.handler.light_end(&mut batch.normals); forindexin &to_skip_end { batch.schedule(&self.router, *index); } to_skip_end.clear(); self.handler.end(&mut batch.normals);
// Iterate larger index first, so that `swap_reclaim` won't affect other FSMs // in the list. forindexin reschedule_fsms.iter().rev() { batch.schedule(&self.router, *index); batch.swap_reclaim(*index); } reschedule_fsms.clear(); } ifletSome(fsm) = batch.control.take() { self.router.control_scheduler.schedule(fsm); info!("poller will exit, release the left ControlFsm"); } letleft_fsm_cnt = batch.normals.len(); if left_fsm_cnt > 0 { info!( "poller will exit, schedule {} left NormalFsms", left_fsm_cnt ); foriin0..left_fsm_cnt { letto_schedule = match batch.normals[i].take() { Some(f) => f, None => continue, }; self.router.normal_scheduler.schedule(to_schedule.fsm); } } batch.clear(); } }