Talent-Plan:用 Rust 实现简易 KV 引擎
版本
前期准备
Rust 学习
过关过程
Rust Project 1: The Rust toolbox
本 project 过关代码可参考该 commit。
主要参照了 README 来完成本 project,具体过程比较 trivial 不再细述。主要工作如下:
- 搭建项目基本目录结构。
- 使用 clap 来解析命令行参数,根据官方文档学习 crate 的具体使用方法。
- 使用 cargo.toml 中的若干参数,包括 dev-dependencies,条件编译等等。
- 完成基于内存 hashmap 的 KvStore 的增删改查接口。
- 增加包文档和函数文档并在文档中添加了文档测试
- 使用 cargo fmt 和 cargo clippy 来提升代码质量
Rust Project 2: Log-structured file I/O
本 project 过关代码可参考该 commit。
错误处理
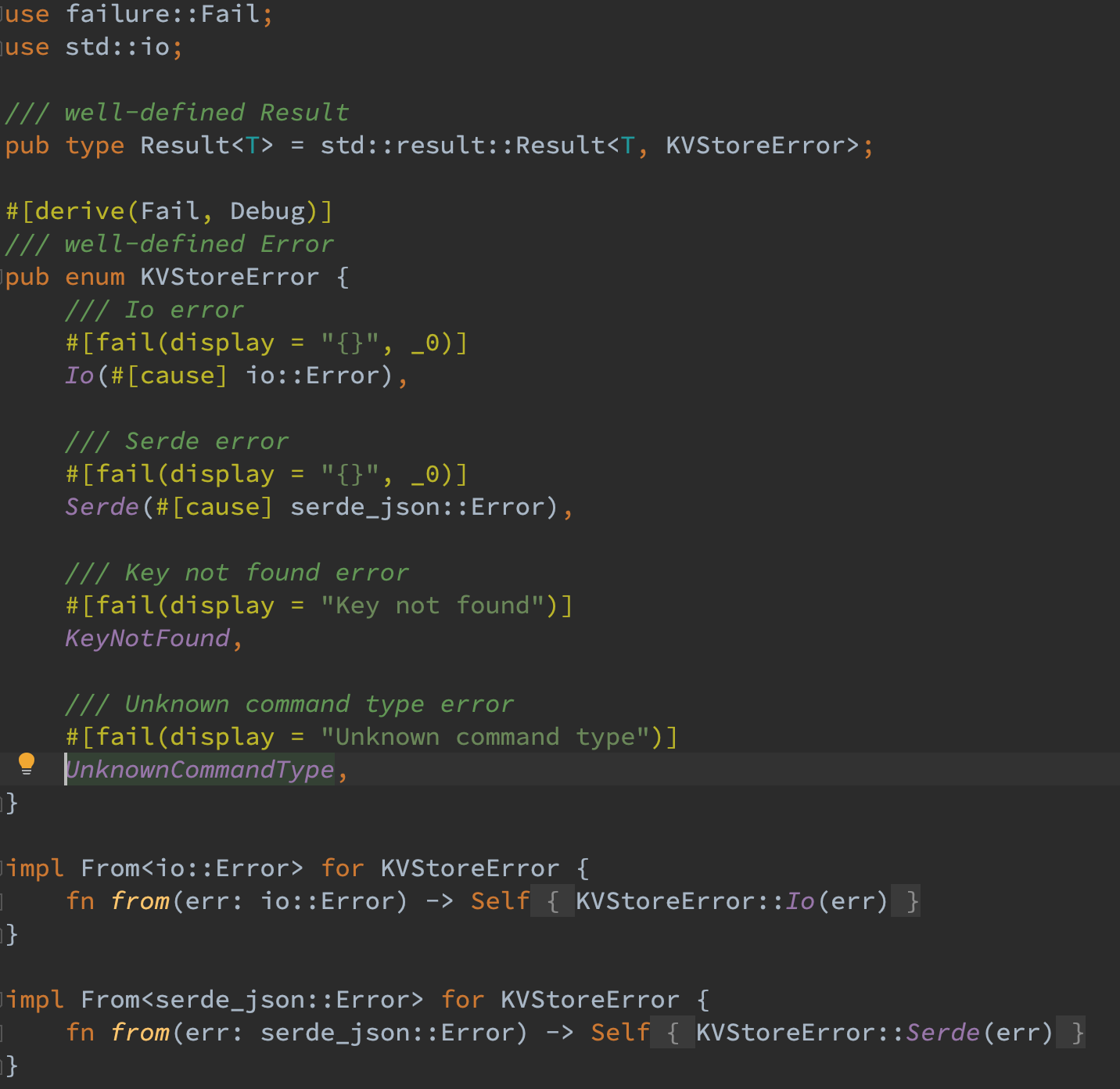
在阅读 failure crate 的 文档 之后,在本 project 中采用了第二种错误处理方式——自定义错误结构。通过定义 KVStoreError 结构体并使用 failure crate 提供的能力,可以很轻易地捕捉不同的错误并列举他们的表示,调用者也可以直接通过模式匹配的方式得到错误类型。
此外,通过为 io:Error 和 serde_json:Error 添加转换到 KVStoreError 的函数,在主逻辑中可以轻松的使用 ? 来向上传递错误,从而避免对 Result 类型的暴力 unwrap。
此外,还定义了 Result
包结构
对于包含一个 lib 包和一个 bin 包的 crate ,在 lib 包中,需要引用所有新增文件的文件名当做其模块名将其引入,此外还需要使用 pub use 语法来将 bin 包会用到的结构公开导出。
在 lib 包的任何文件里,都可以通过 crate:: 的方式来引入本 lib 库被公开导出的结构。
在 bin 包中,需要通过实际 crate 名:: 的方式来引入同名 lib 库被公开导出的结构。
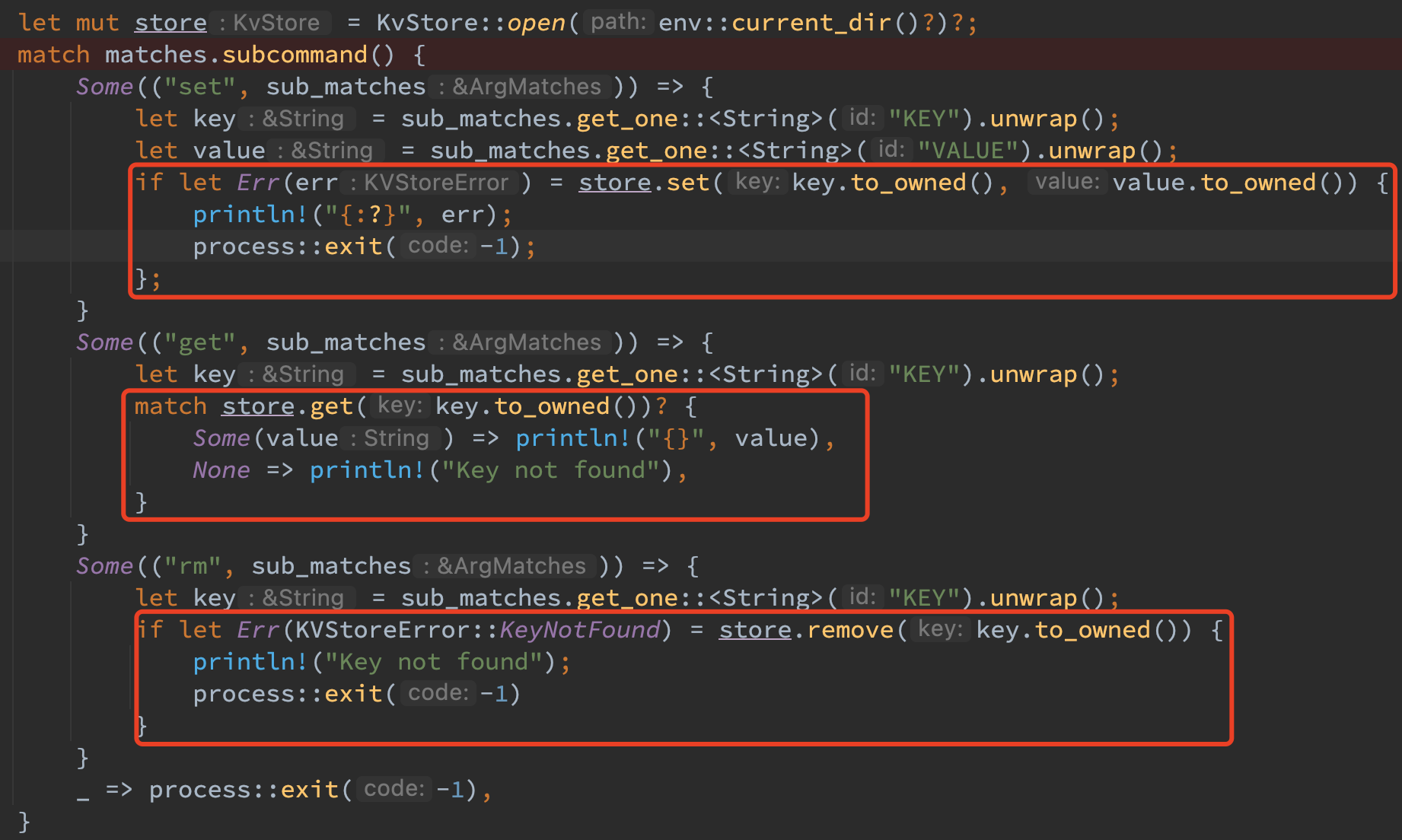
结果捕捉

结果捕捉中的正常/异常处理需要满足以上题意的要求,因而在 main 函数中原样实现了以上需求如下。
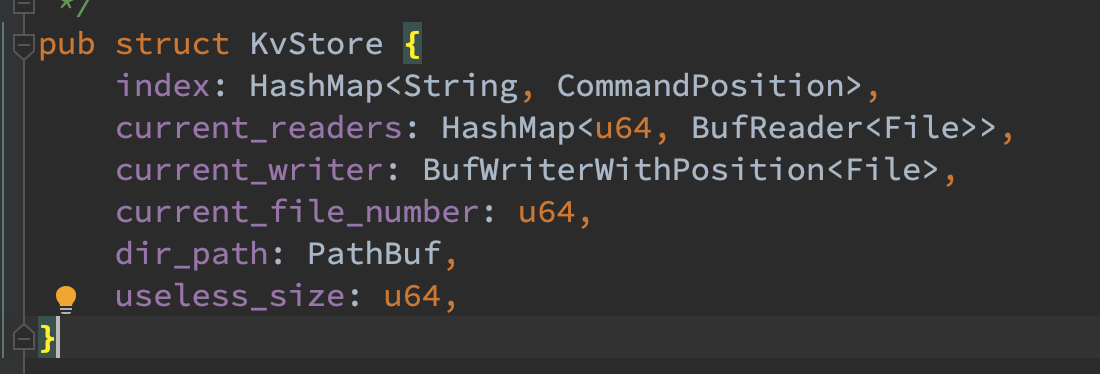
结构体
KvStore 结构体中各个变量含义如下:
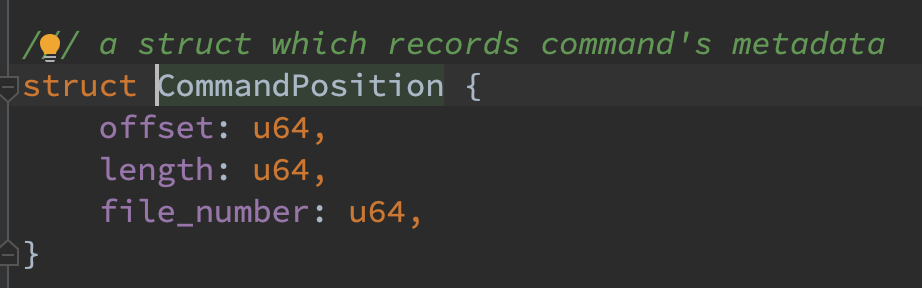
- Index :参照 bitcask 的模型,key 为 kv pair 的 key,value 并不存储对应的 value,而是存储该 value 在第 file_number 个文件的 offset 处,长度为 length。
- current_readers:对于所有已经存在的文件,KvStore 都缓存了一个 BufReader 来便于 seek 到对应的 offset 去 read。实际上也可以没有该结构体每次需要 reader 时新建即可,但复用 reader 可以一定程度上减少资源的损耗。
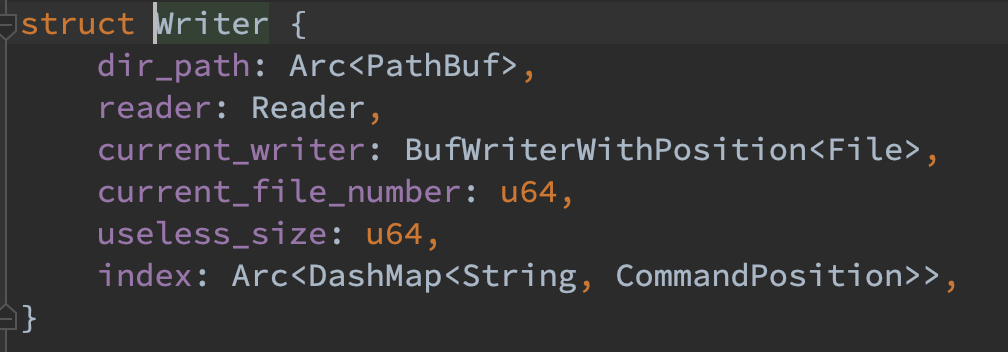
- current_writer:当前正在写入的 file,其每次写入只需要 append 即可,不需要 seek。新建一个 BufWriterWithPosition 结构体的原因是能够快速的获取当前写入的 offset,而不需要在通过 seek(SeekFrom::Current(0))(可能是系统调用) 的方式去获取。
- current_file_number:当前最大的 file_number,每次 compaction 之后会新增 1。每个数据文件都会附带一个 file_number,file_number 越大的文件越新,该 version 能够保证恢复时的正确性。
- dir_path:当前文件目录路径。
- useless_size:当前无用的数据总和。当改值大于某一个阈值时,会触发一次 compaction。

写流程
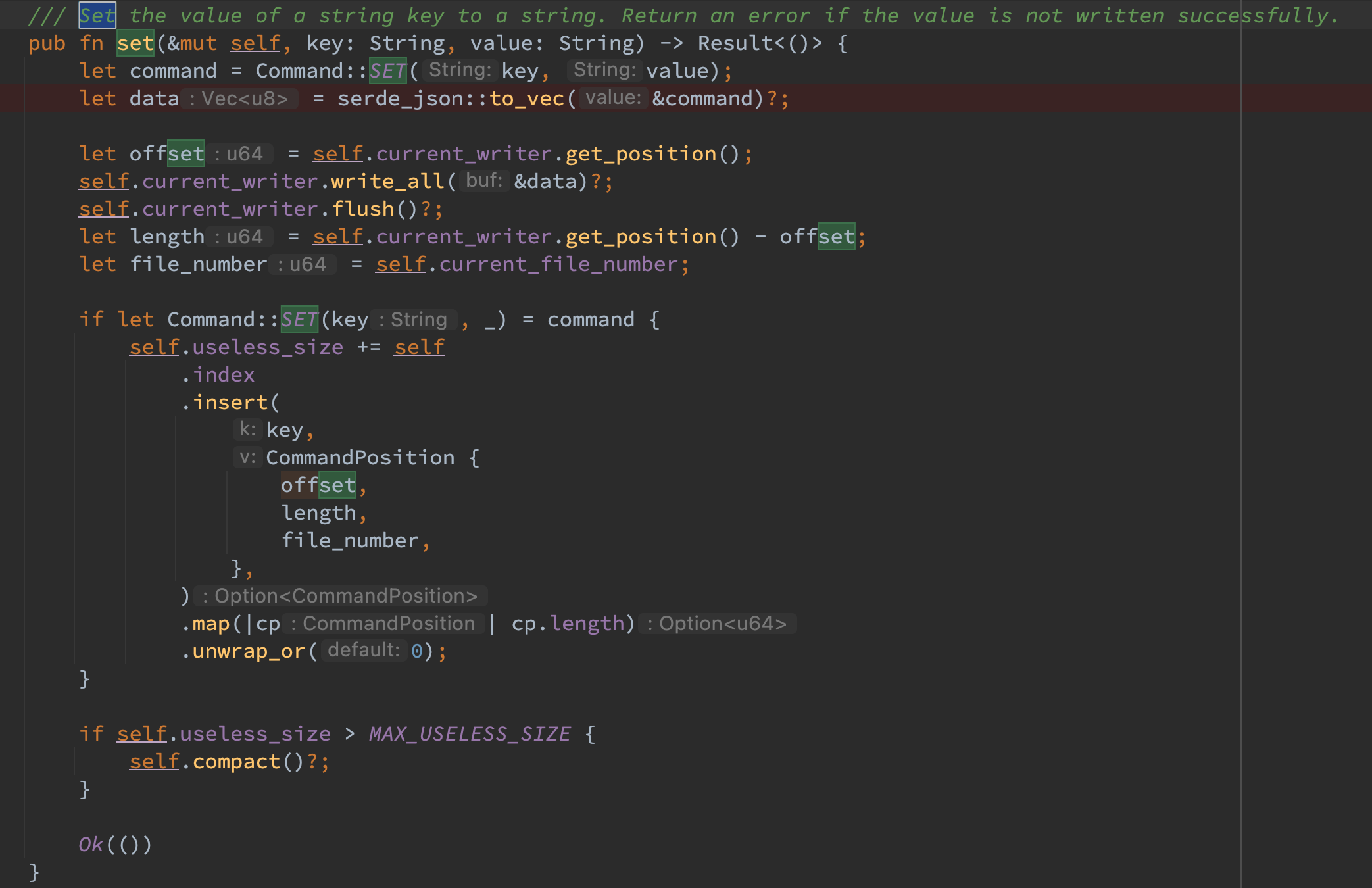
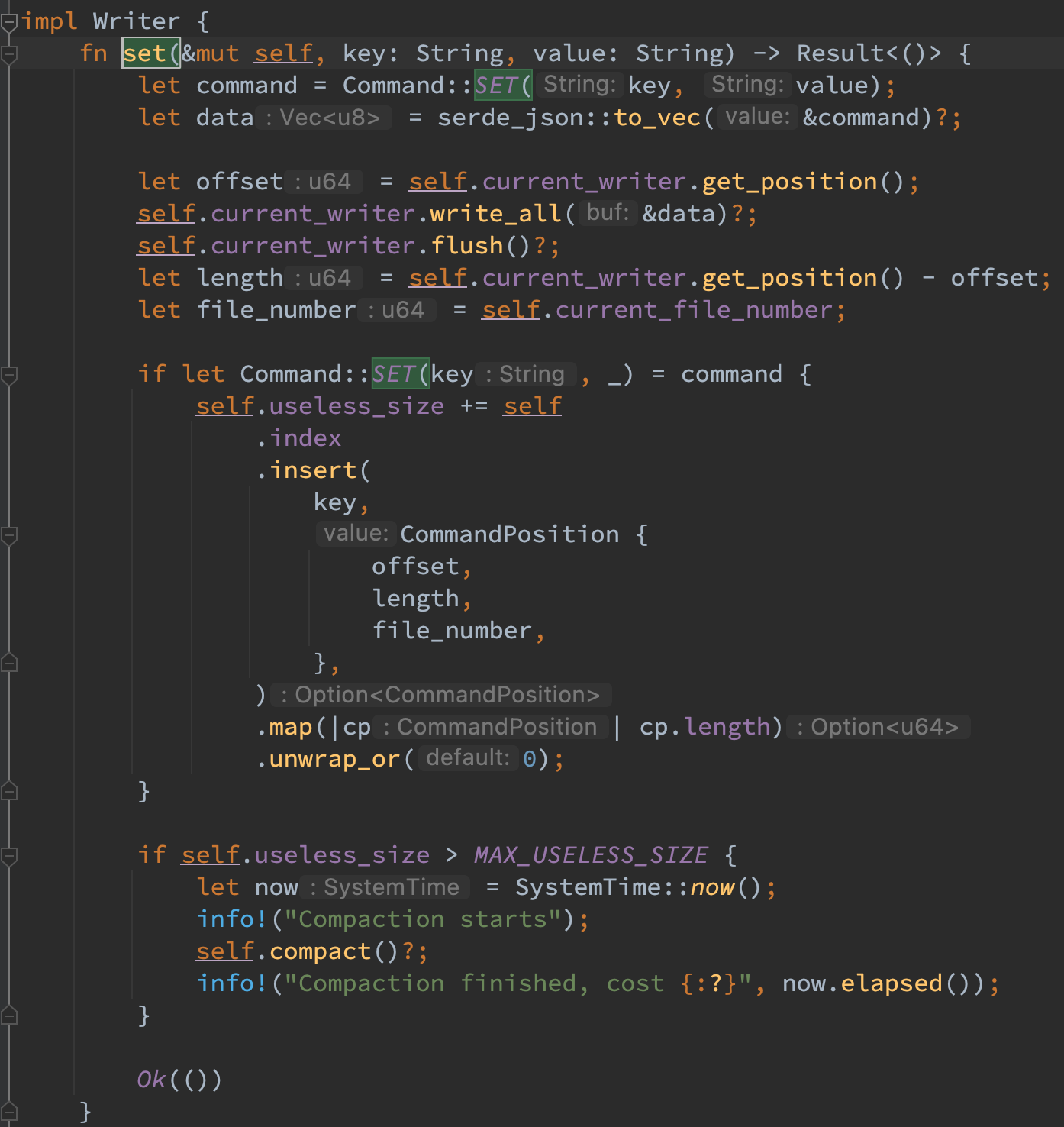
使用 serde_json 将 set 命令序列化,接着再写入到 current_writer 中,然后在 index map 中维护该 key 的索引。注意如果某 key 之前已在 KvStore 中存在,则 insert 函数会返回该 key 的旧 value,此时需要维护 useless_size。最后判断如果 useless_size 超过某一个阈值,则进行一次 compact。
需要注意许多返回 Result
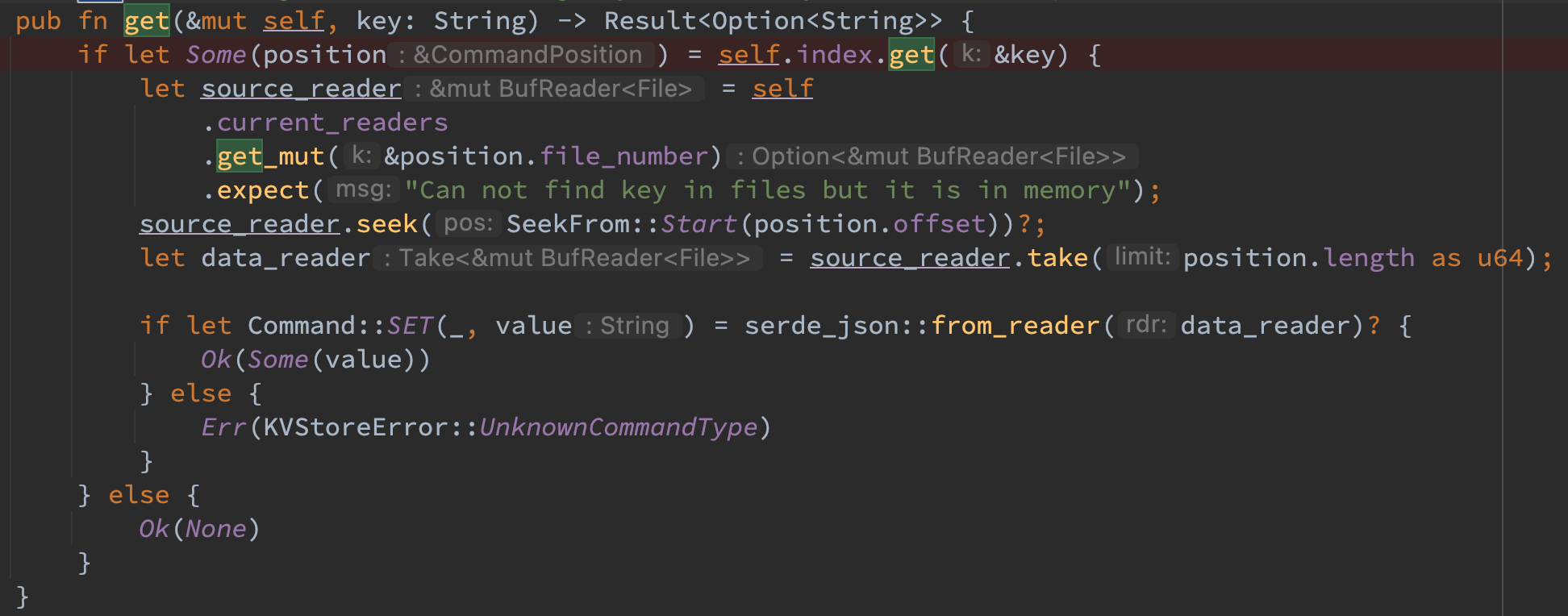
读流程
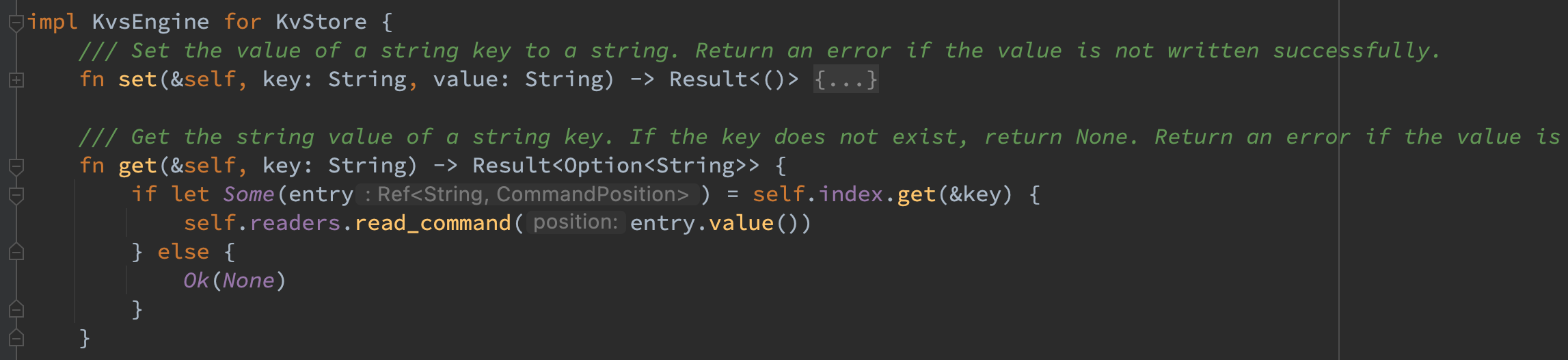
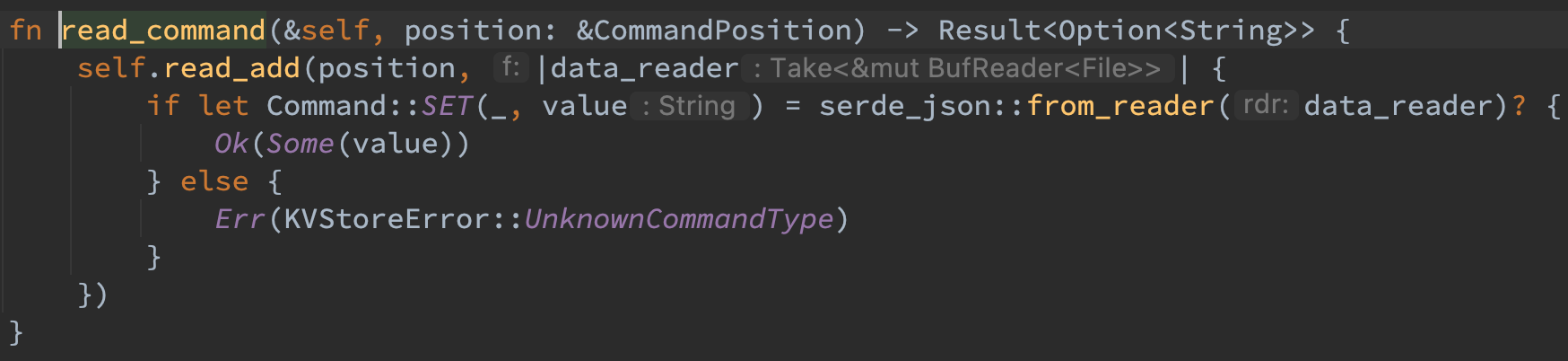
首先在 index 中获取该 key 的索引,如果不存在则说明该 key 不存在直接返回即可,否则根据索引中的 file_number 在 current_readers 中拿到对应的 reader,seek 到对应的 offset 并读取长度为 length 的数据。如果存在则返回 value,否则说明遇到了异常,返回错误即可。
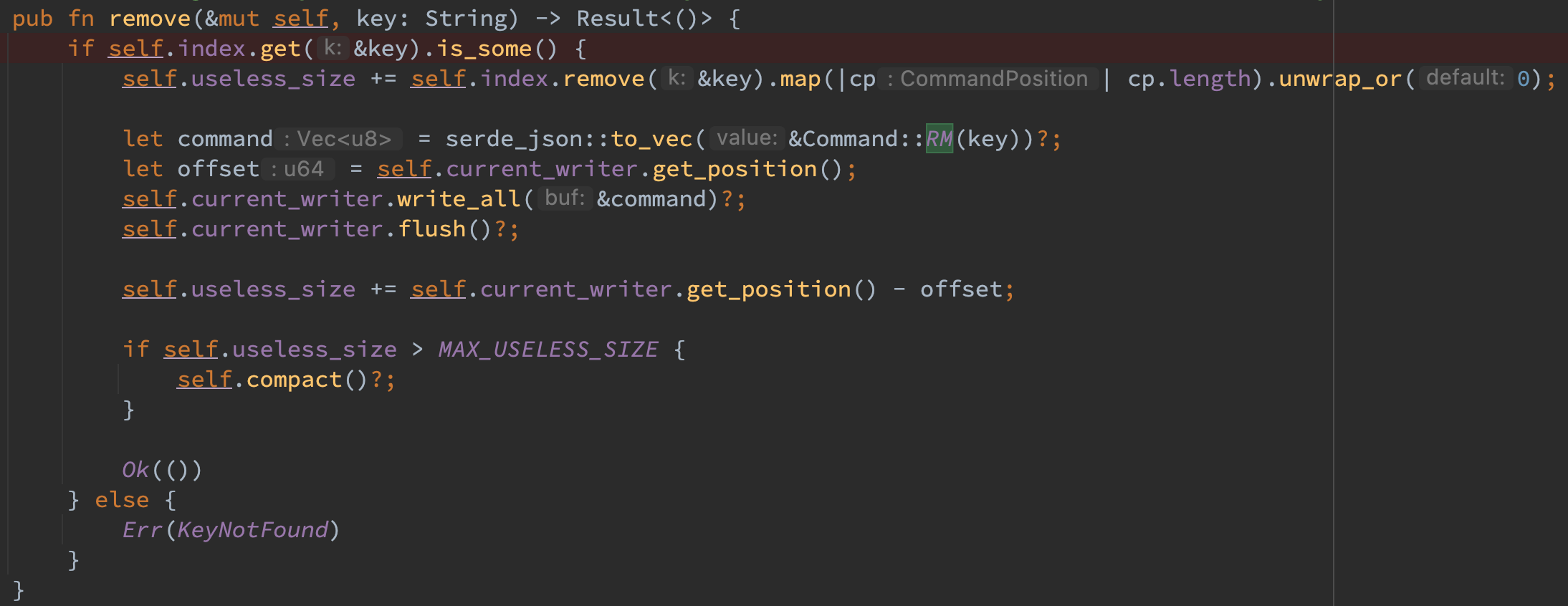
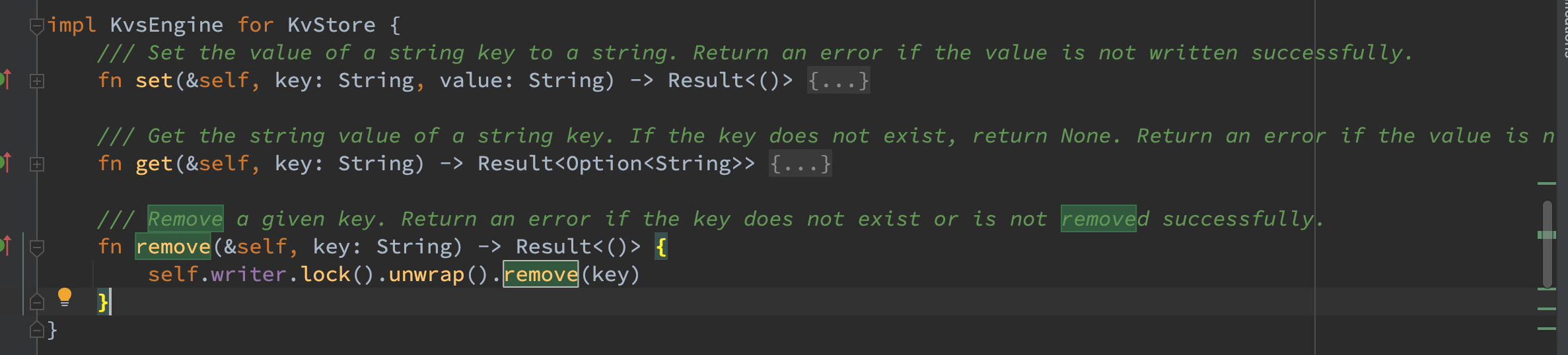
删除流程
首先在 index 中获取该 key 的索引,如果不存在则说明该 key 不存在返回 ErrNotFound 错误即可,否则移除该索引,接着将 rm 命令序列化并写入到 current_writer 中以保证该 key 能够被确定性删除。注意对于能够找到对应 key 的 rm 命令,useless_size 不仅需要增加 rm 命令本身的长度,还需要增加之前 set 命令的长度,因为此时他们俩都已经可以被一起回收。 最后判断如果 useless_size 超过某一个阈值,则进行一次 compact。
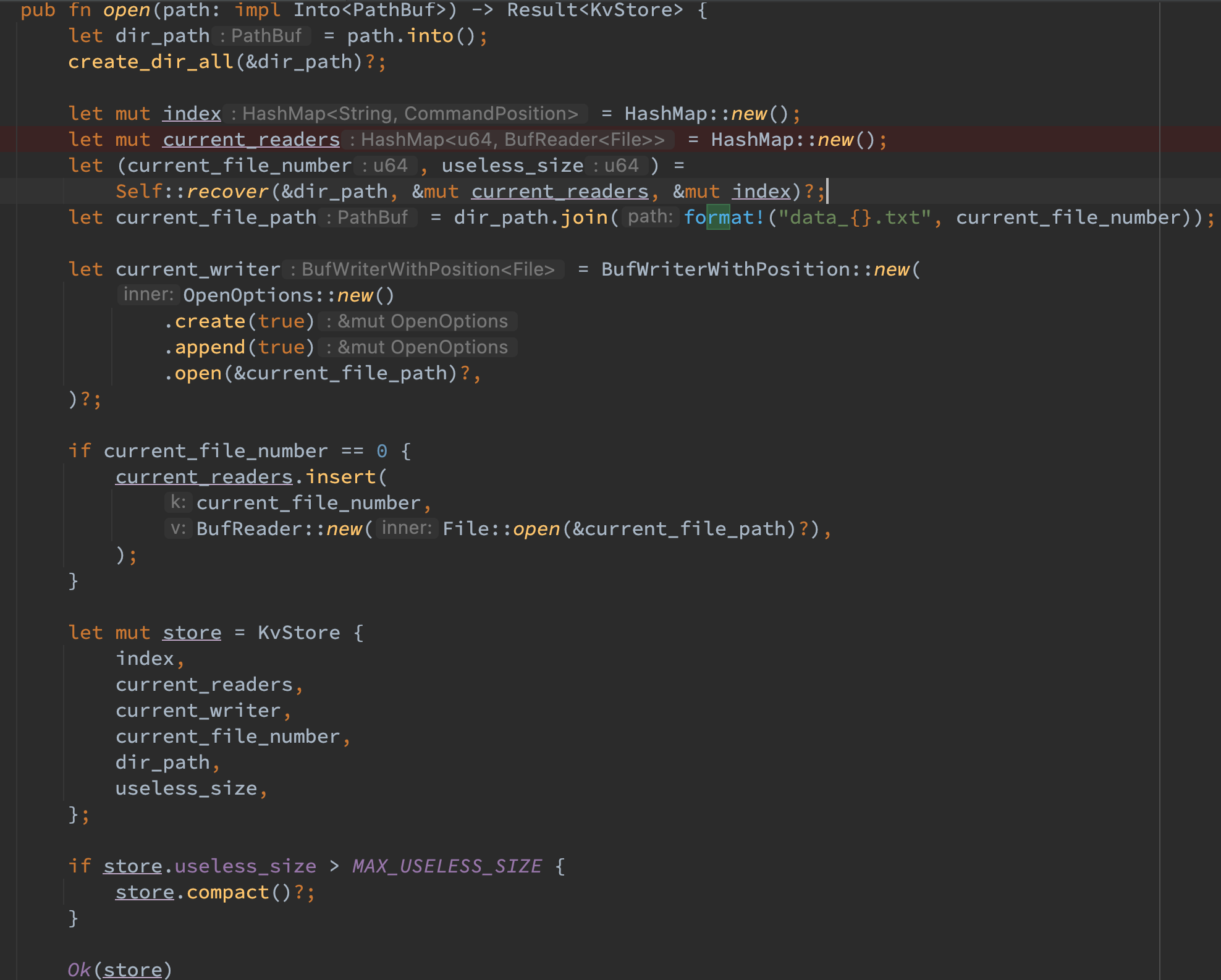
重启流程
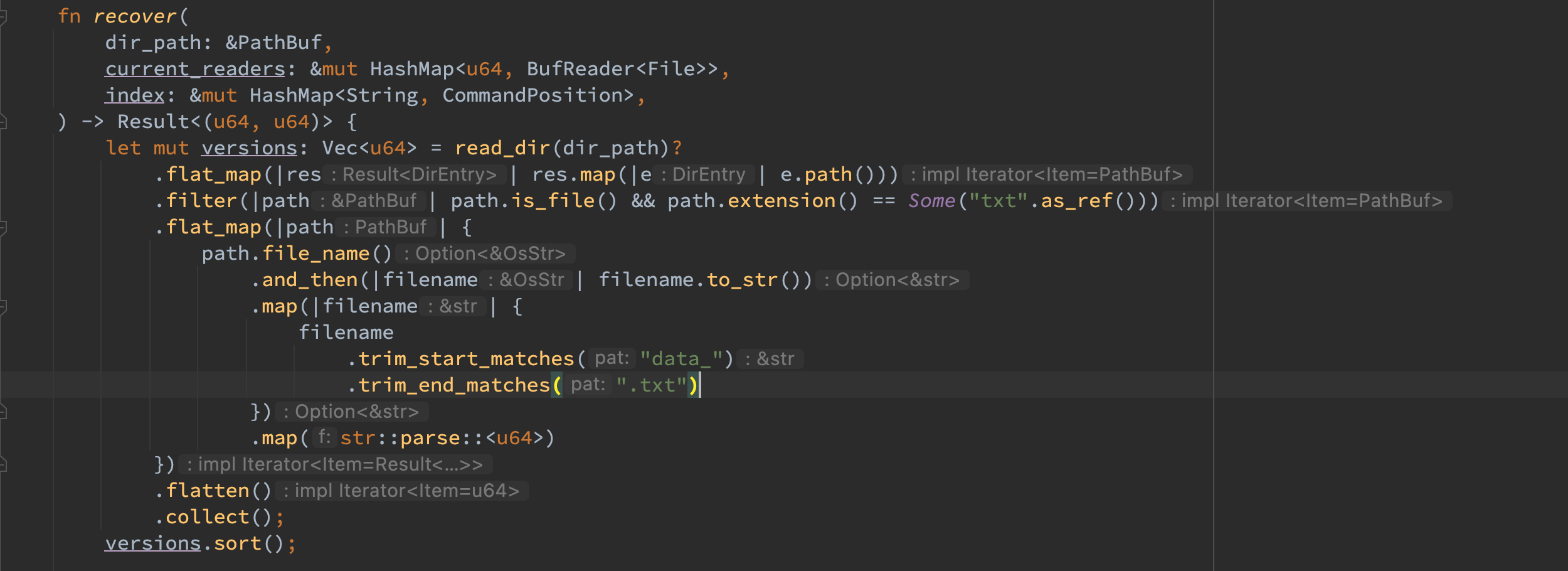
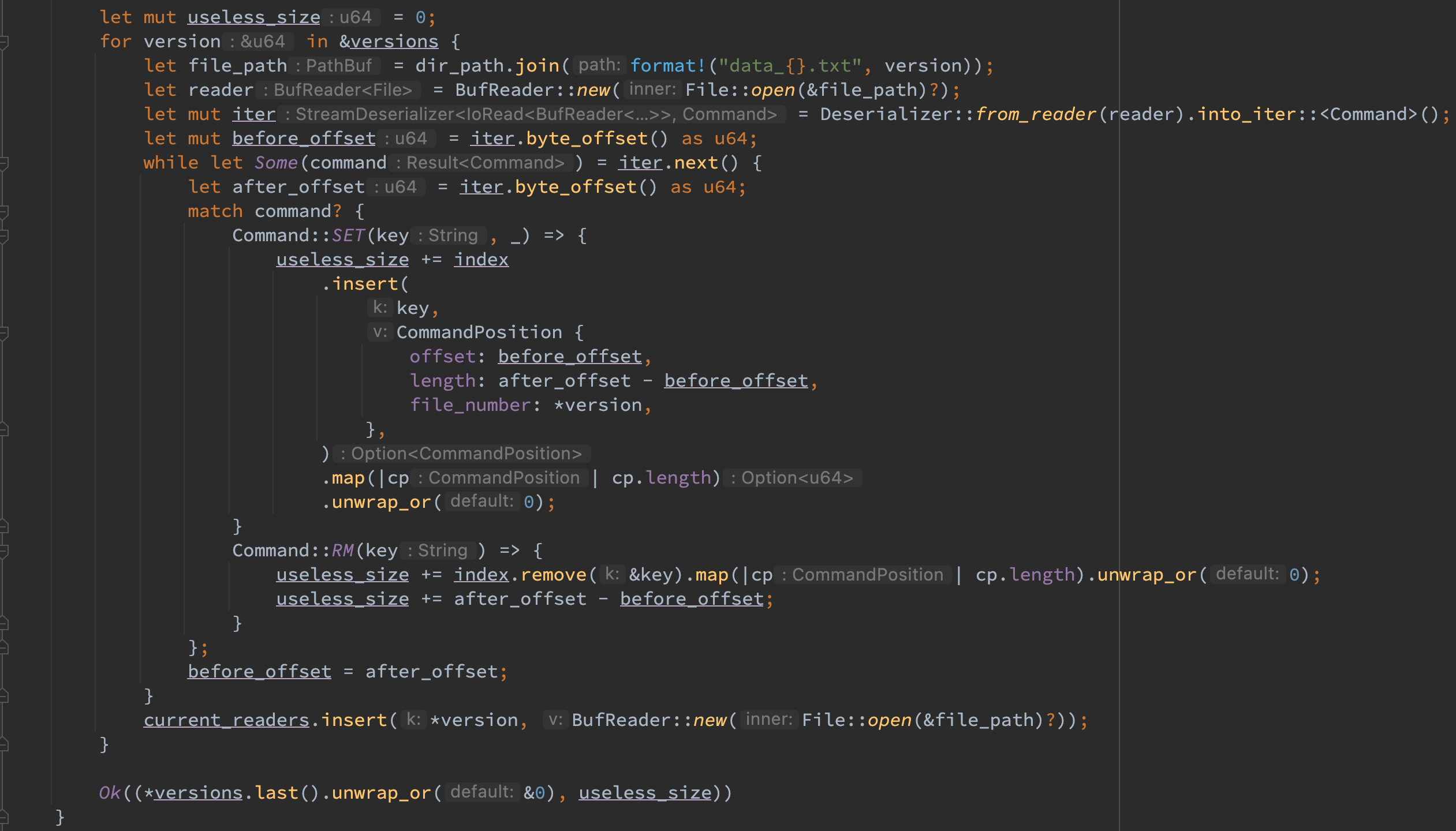
重启时首先初始化若干重要结构,最重要的是调用 recover 函数,该函数将遍历当前所有的文件,不仅将索引维护到 index 结构中,还会将 reader 维护到 current_readers 结构中,最后返回(当前最大的文件版本,当前所有文件的 useless_size),接着利用 current_file_number 构建当前最大文件的 writer,需要注意由于 bitcask 模型是 append_only 的机制,所以在构建 writer 时需要使用 OpenOptions 来使得 append 属性为 true,这样重启后直接 append 即可。最后根据 use_less 判断是否需要 compact,最后返回即可。
对于 Recover 函数,其需要读取数据目录中的所有文件,按照 file_number 从小到大的顺序去按序 apply 从而保证重启的正确性。
对于排序,不能直接对文件名排序,因为这样的排序是按照字母编码而不是按照 file_number 大小。因此需要先将所有的 file_number 解析出来再对数字进行排序,之后再利用这些数字索引文件名即可。需要注意这里利用了许多文件操作的链式调用,需要查很多文档。
在获取到排序好的 versions 之后,可以按序读取文件并将其维护到 index 和 current_readers 中去,注意在该过程中也要注意维护 useless_size。此外得益于 serde_json 的 from_reader().into_iter() 接口,可以按照迭代器的方式去读取 command,而不用关注何时到了末尾,应该读多少字节才可以解析出一个 command,这极大的简化了读取流程。
合并流程
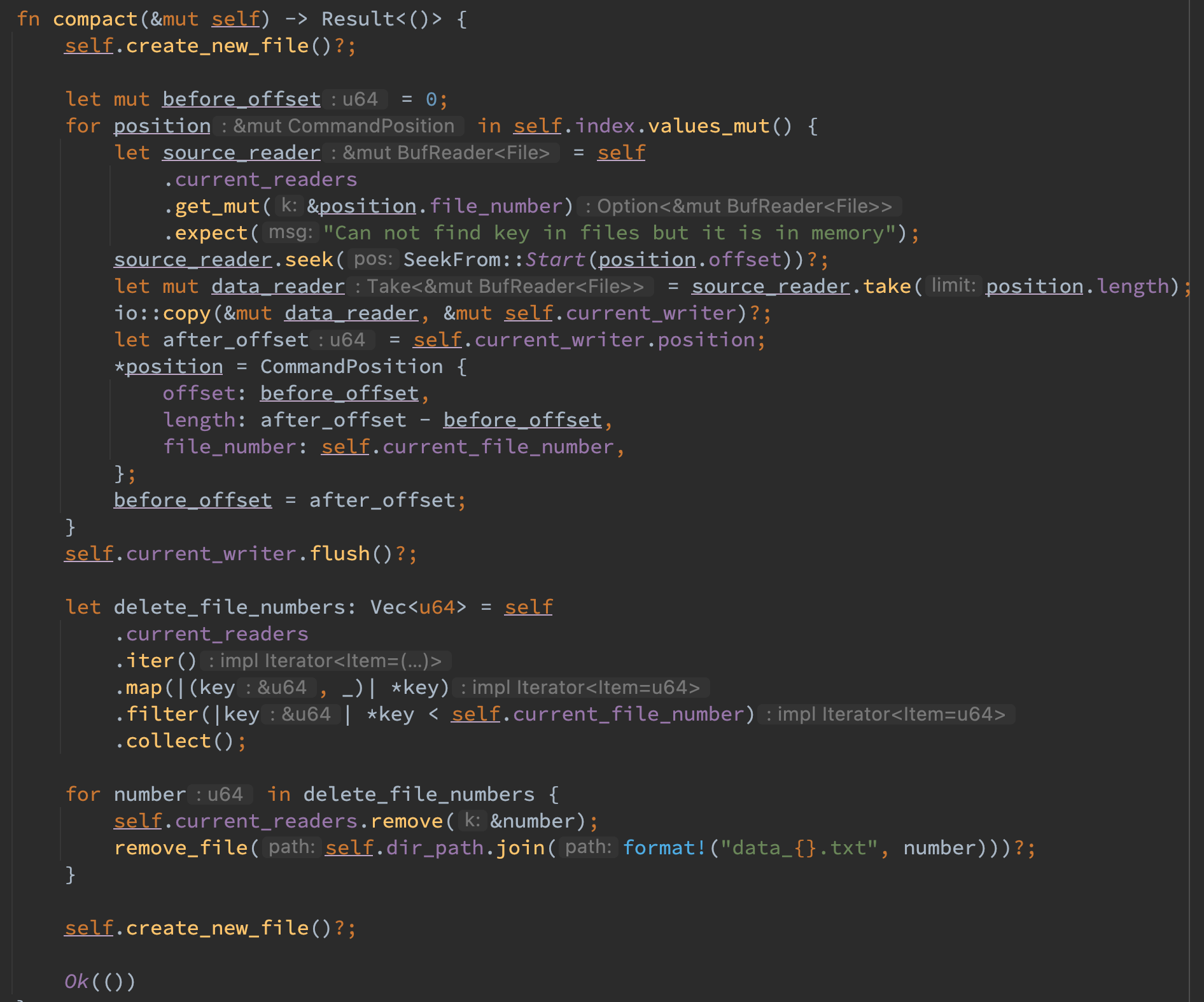
当前的合并流程采用了暴力的全部合并策略,同时将合并放在了客户端可感知延迟的执行流程中。
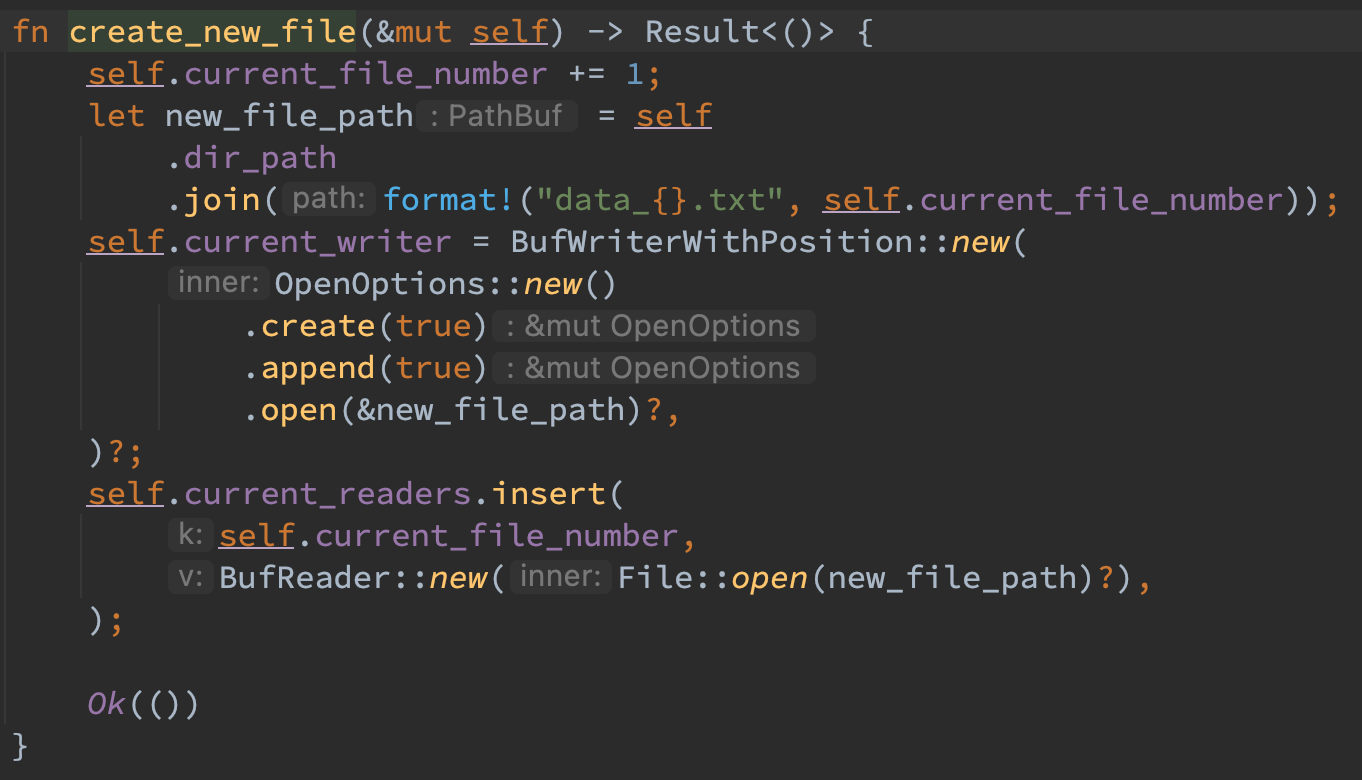
当 useless_size 大于某个阈值时,会触发一次合并,此时会增加 file_number 并将 index 中所有的数据都写入到当前新建的文件中,同时更新内存中的索引。接着再删除老文件和对应的 reader,最后再新建一个文件承载之后的写入即可。
需要注意按照这个流程即使在合并的写文件过程中出现了重启也不会出现正确性问题。如果新文件的所有数据尚未 flush 成功,老文件并不会被删除,那么只要重启时会按照 file_number 从小到大的顺序进行重放,数据便不会丢失。
Rust Project 3: Synchronous client-server networking
本 project 过关代码可参考该 commit。
命令行解析
在本 project 中,命令行分为了客户端 kvs-client 和服务端 kvs-server 两处,因此需要分别进行解析。
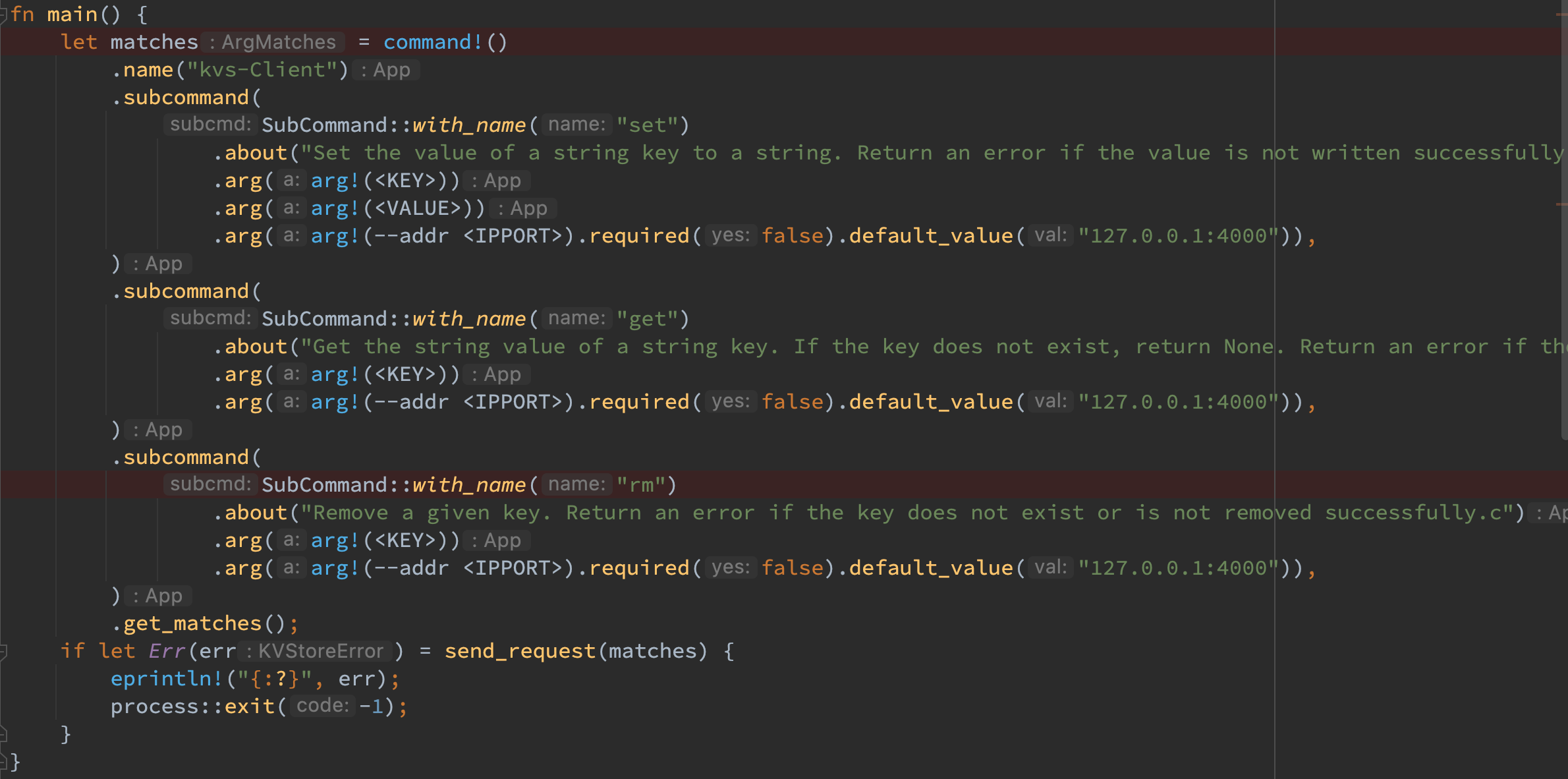
对于 kvs-client,基本继承了 project2 的命令行解析工具,仅仅增加了 addr 的解析。此外也按照题意将正常输出打印在了 stdout 中,将错误输出打印在了 stderr 中并以非 0 值结束进程
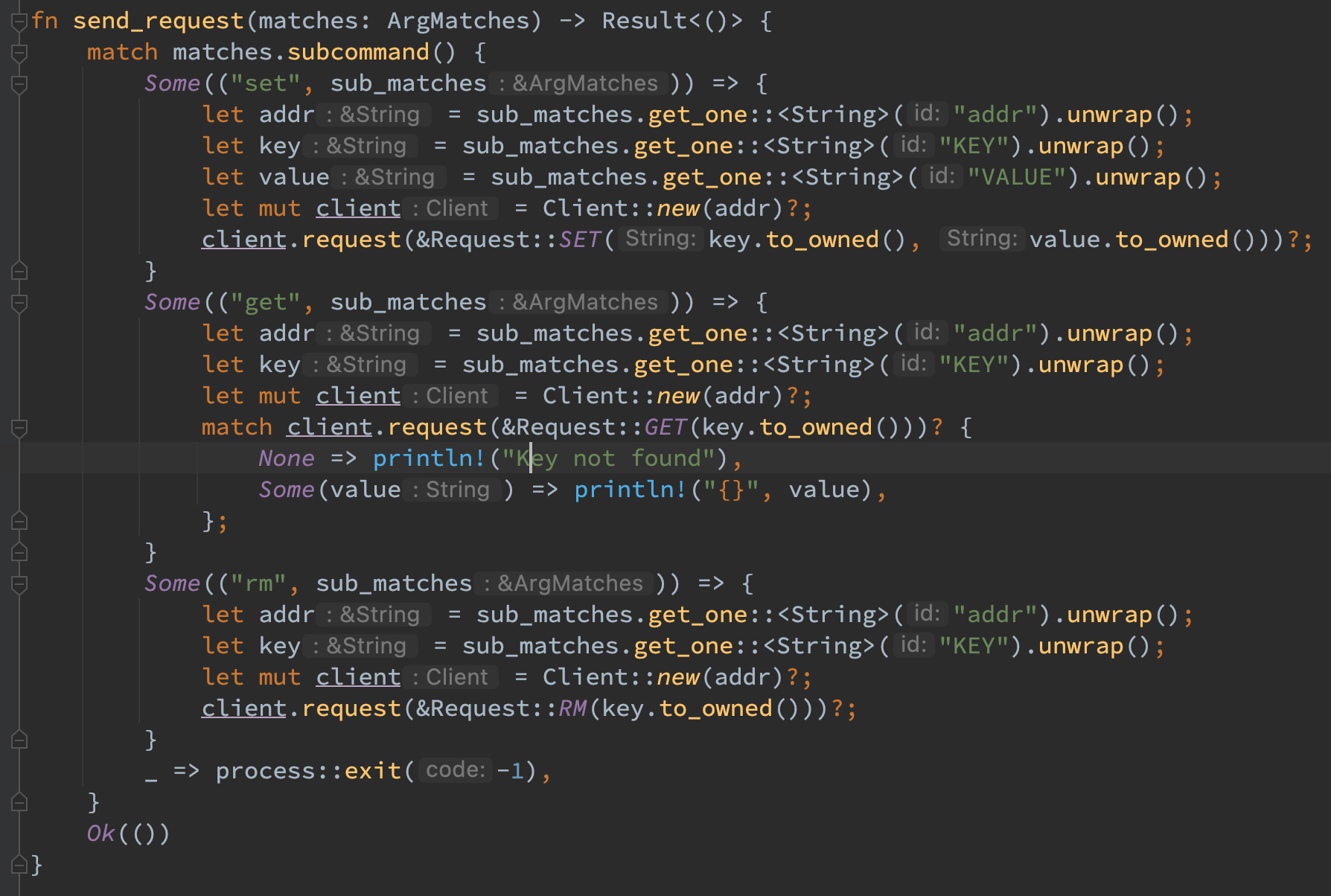
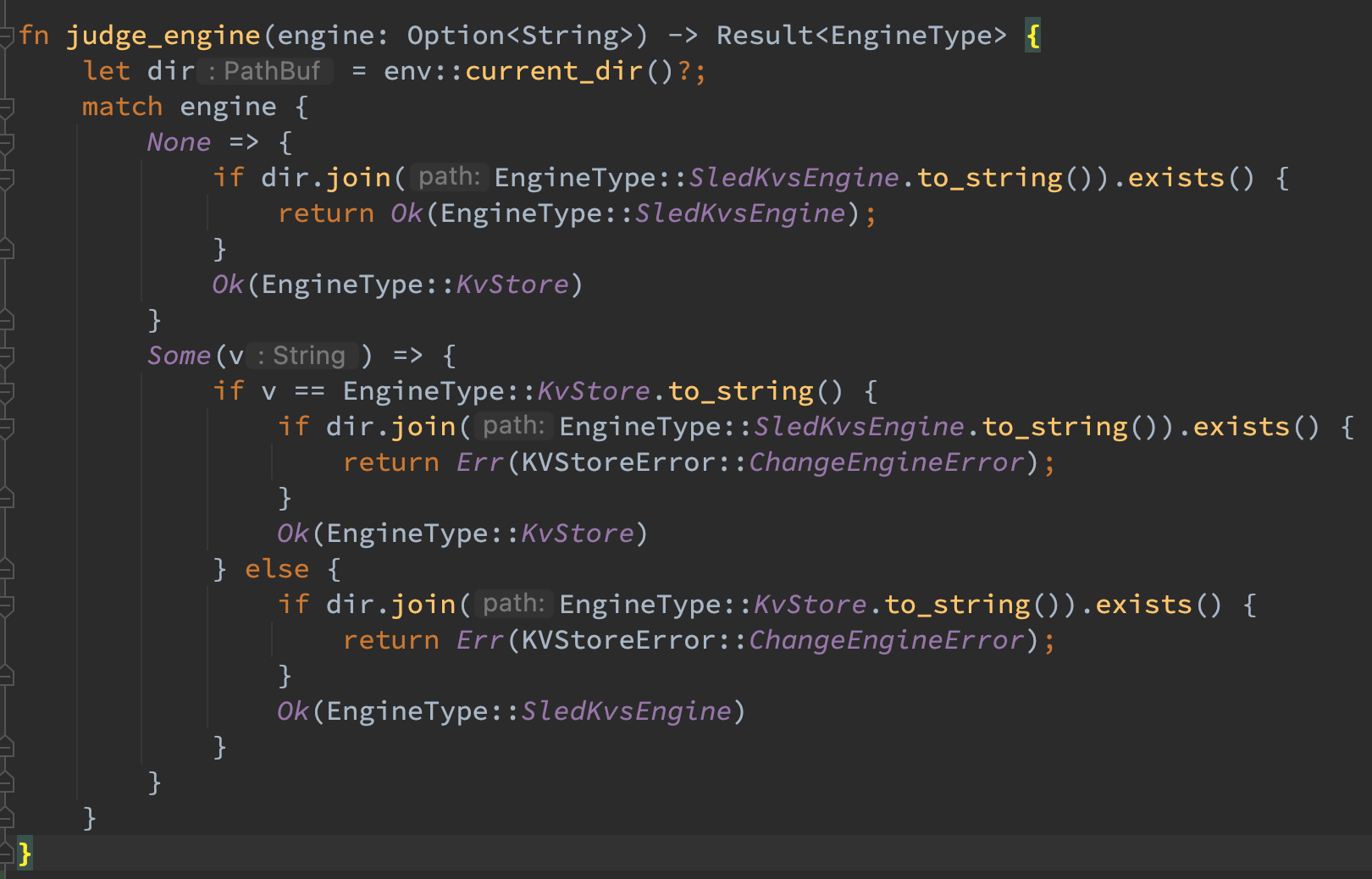
对于 kvs-server,则是按照题意重新写了参数解析器,并对于 engine 增加了只能 2 选 1 的约束。同时还利用 judge_engine 函数实现了引擎选择的判断:对于第一次启动,按照用户参数来启动对应的引擎,如未指定则使用 kvs;对于之后的启动,必须按照之前的引擎启动,若与用户参数冲突则报错。在参数无问题之后打出对应的关键配置既可。

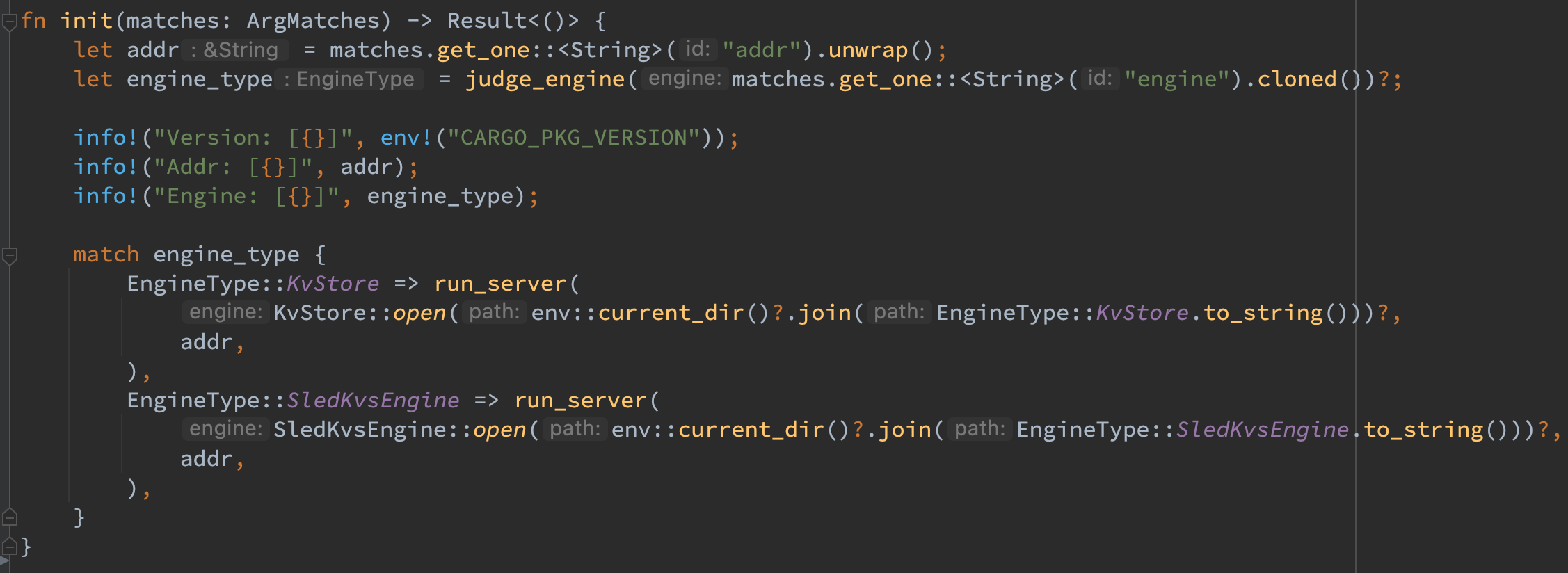

日志打印
在本 project 中对日志采用了集成轻量的 env_logger,参照 文档 仅仅需要在进程启动时指定日志的最低级别即可。

命令传输
本 project 直接使用了 tcp 级别的网络接口来传输命令,因而会有黏包的问题需要处理。
一般的解决方案是在流上发送每段数据前先写入长度,再写入真实的数据;这样在流上读数据时便可以先读长度,再读对应长度的数据后解除阻塞返回了。
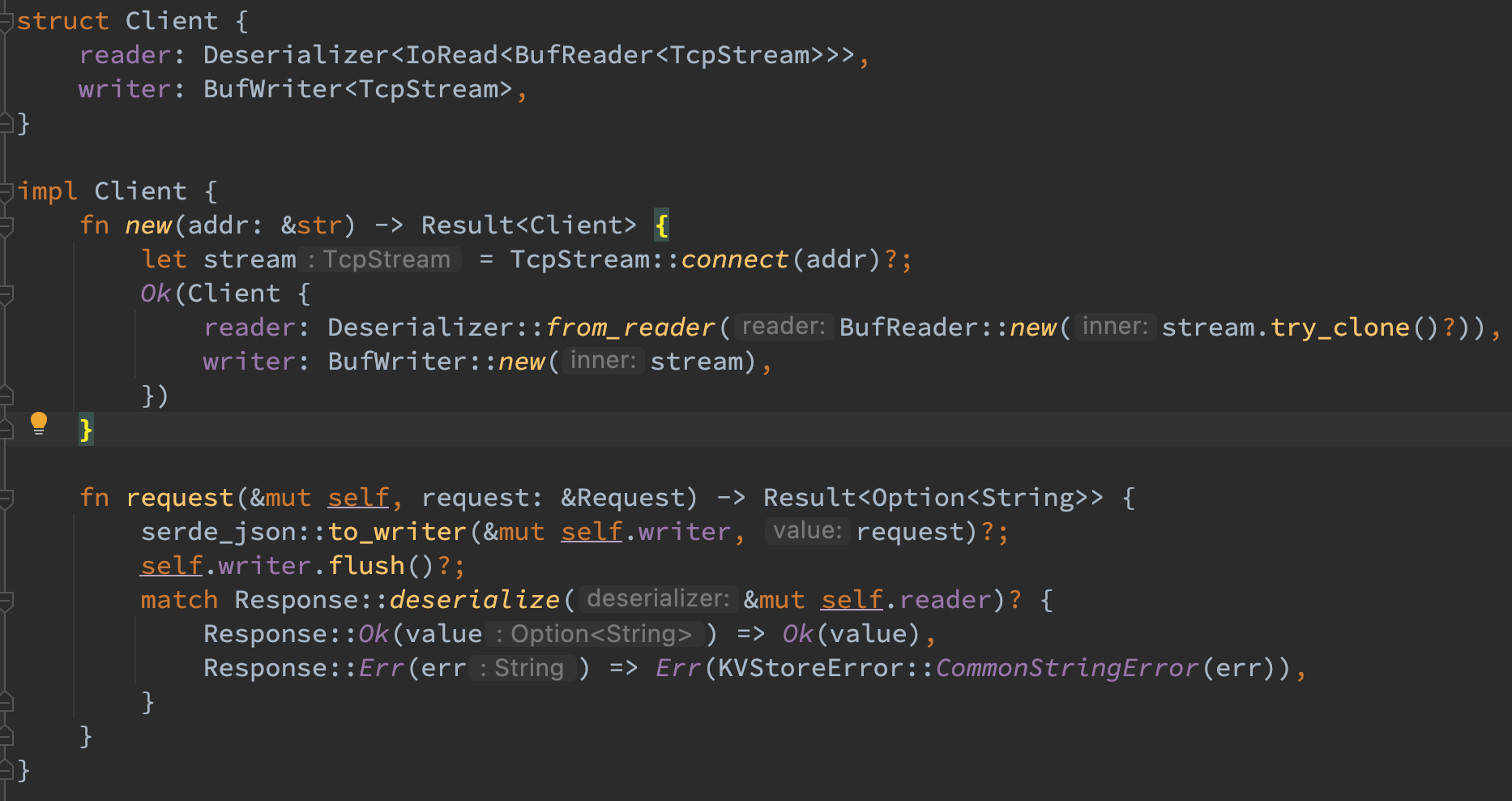
这样的思路可以自己手写,也可以使用 serde 现成的 reader/writer 接口去实现。因而在客户端构建了一个 Client 结构体对 socket 进行了简单的包装。对于 request,使用了一个 BufWriter 的装饰器配以每次写完数据后的 flush 来降低系统调用的开销啊,其在内部已经能够做到先写入长度再写入数据。对于 response,则是参照重启恢复时的逻辑使用 Deserializer 接口构建 reader,并指定对应的反序列化类型以达到先读长度再读数据的问题。这样便可以利用 serde 帮助解决黏包问题。
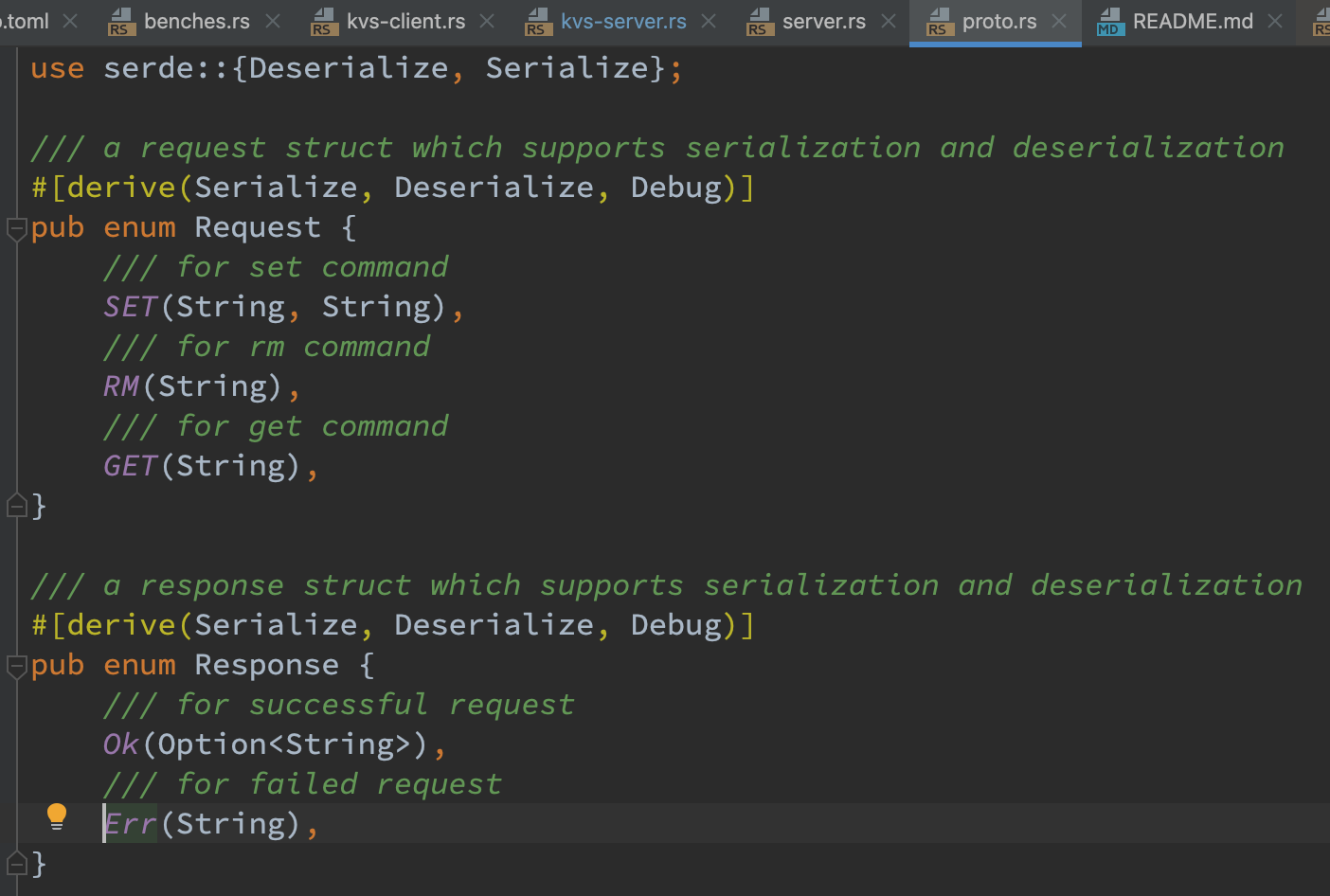
对于服务端,获取 request 和发送 response 的流程和客户端类似。
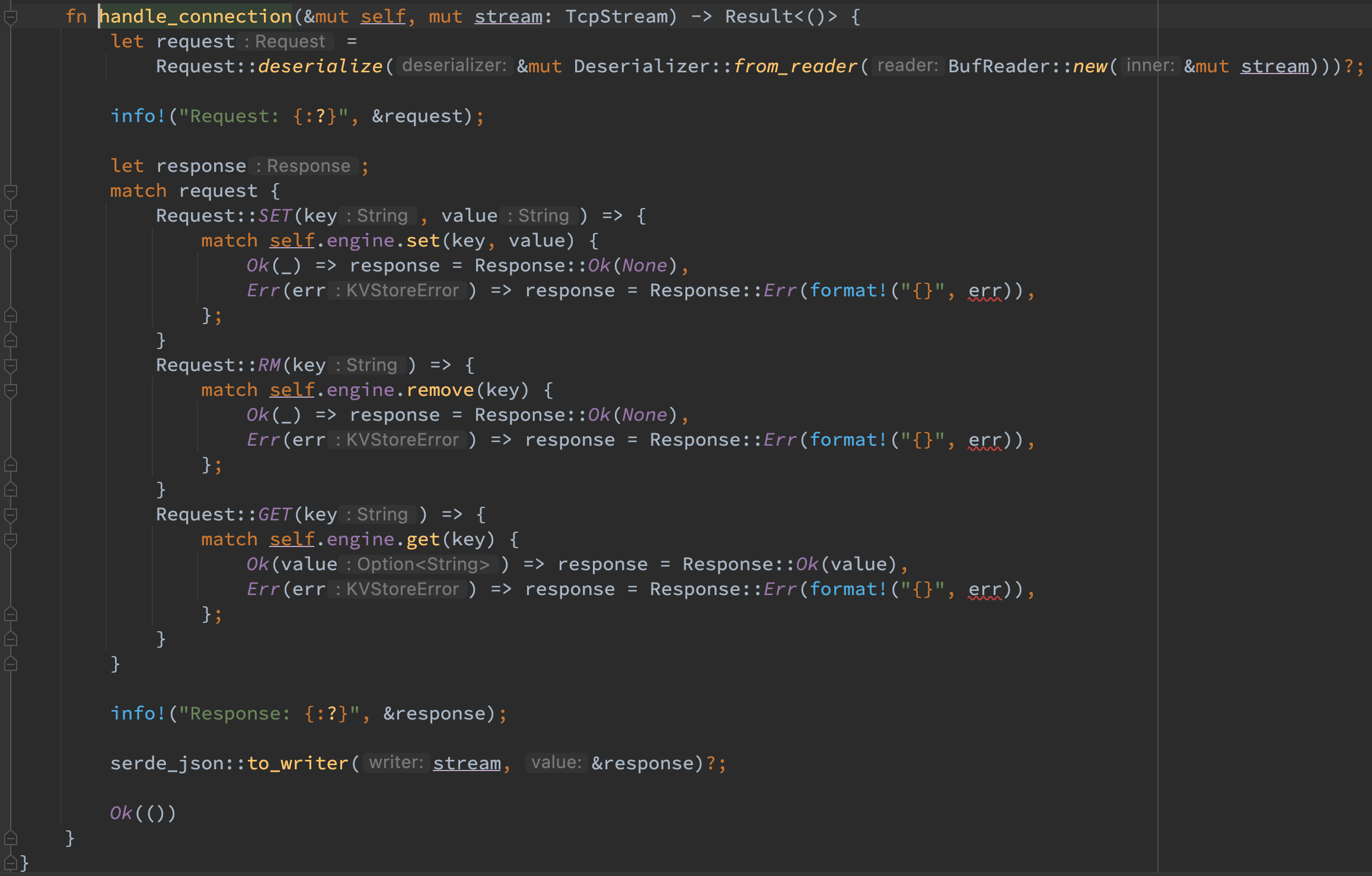
可扩展存储引擎
为了扩展存储引擎的多种实现,抽象出来了统一的 trait 接口 KvsEngine 以对上暴露 trait 的抽象而隐藏具体的实现细节。这样 kvs-server 在启动时便可以以 trait 的方式去访问 engine,而不需要在意其内部的实现细节。
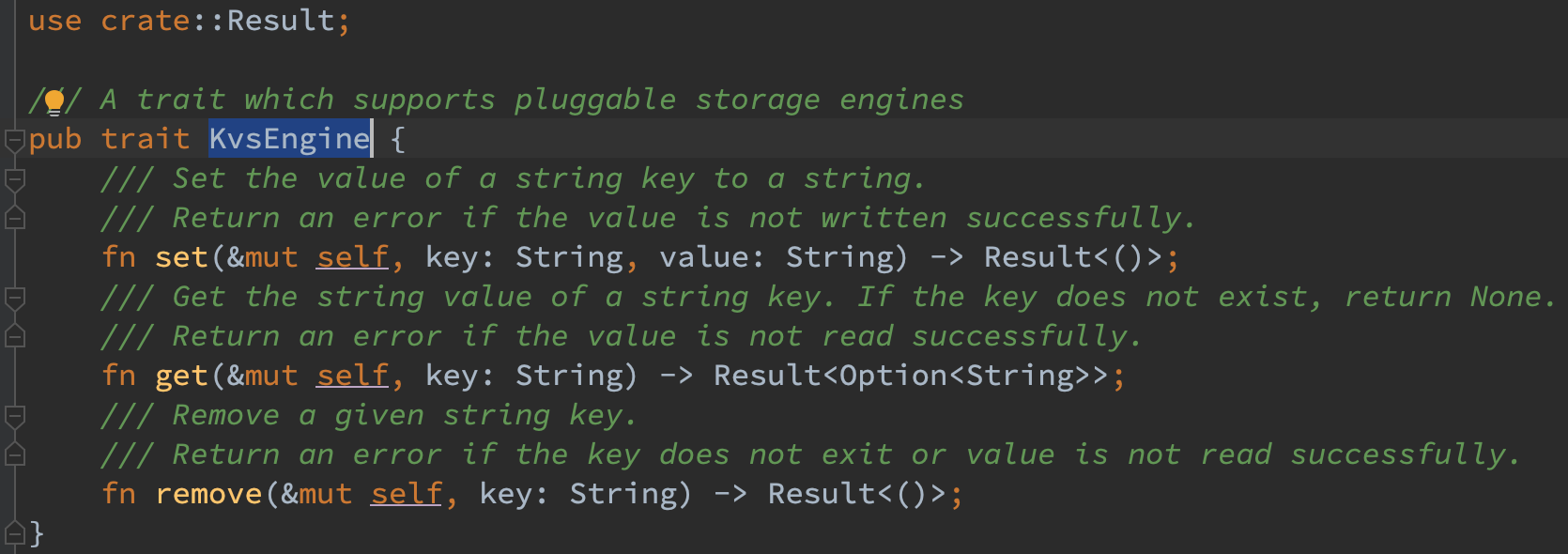

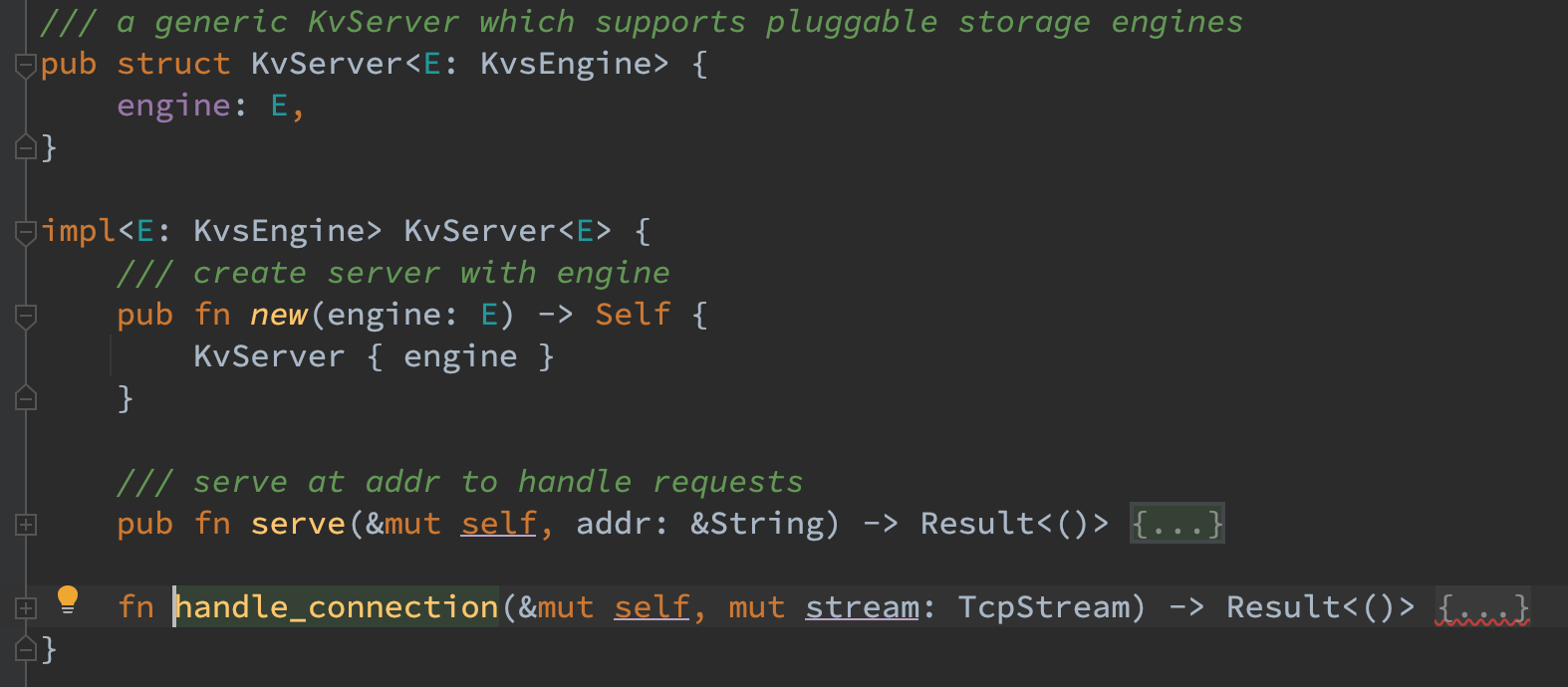
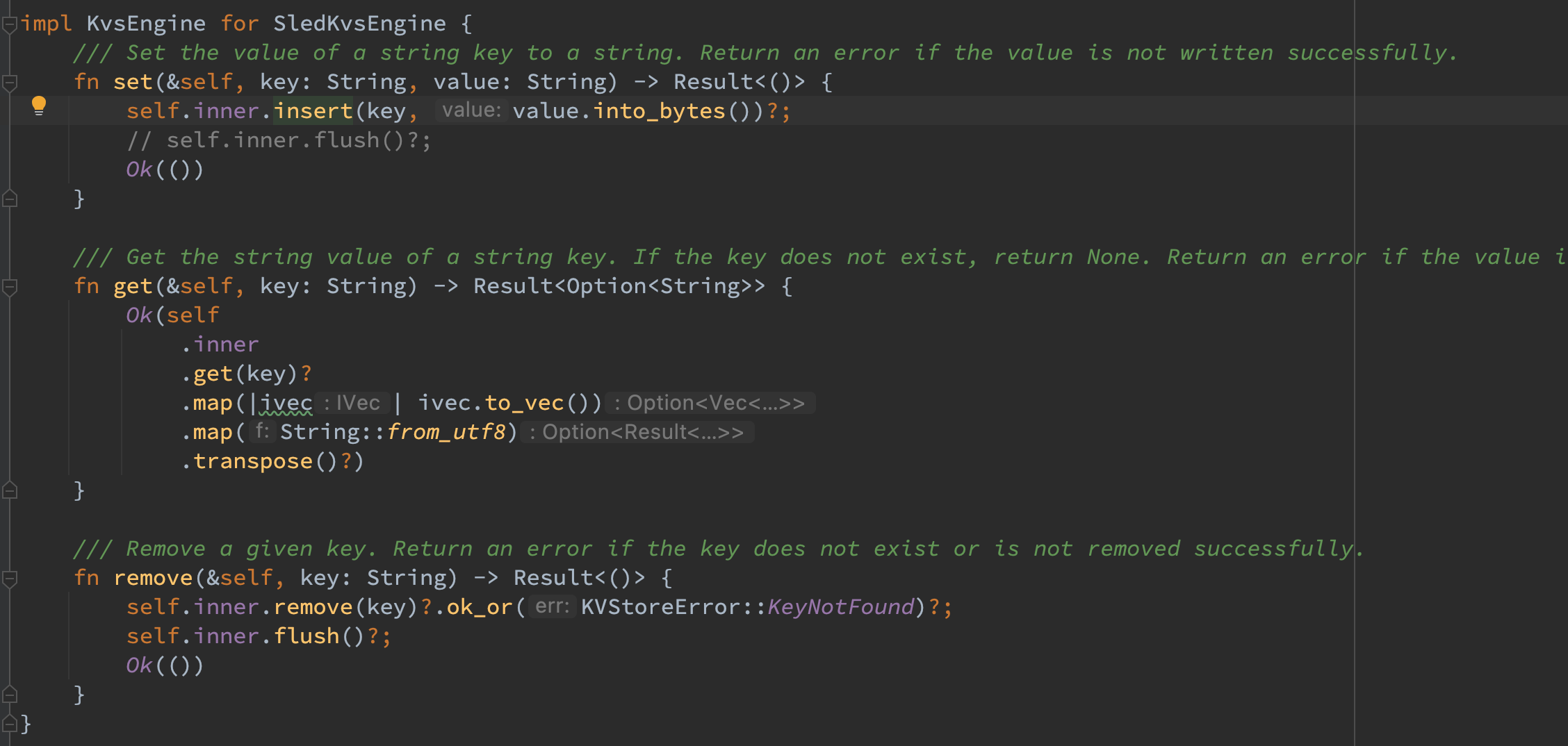
对于 KvStore,将其 set/get/remove 这三个方法抽象到了 KvsEngine 的实现中。

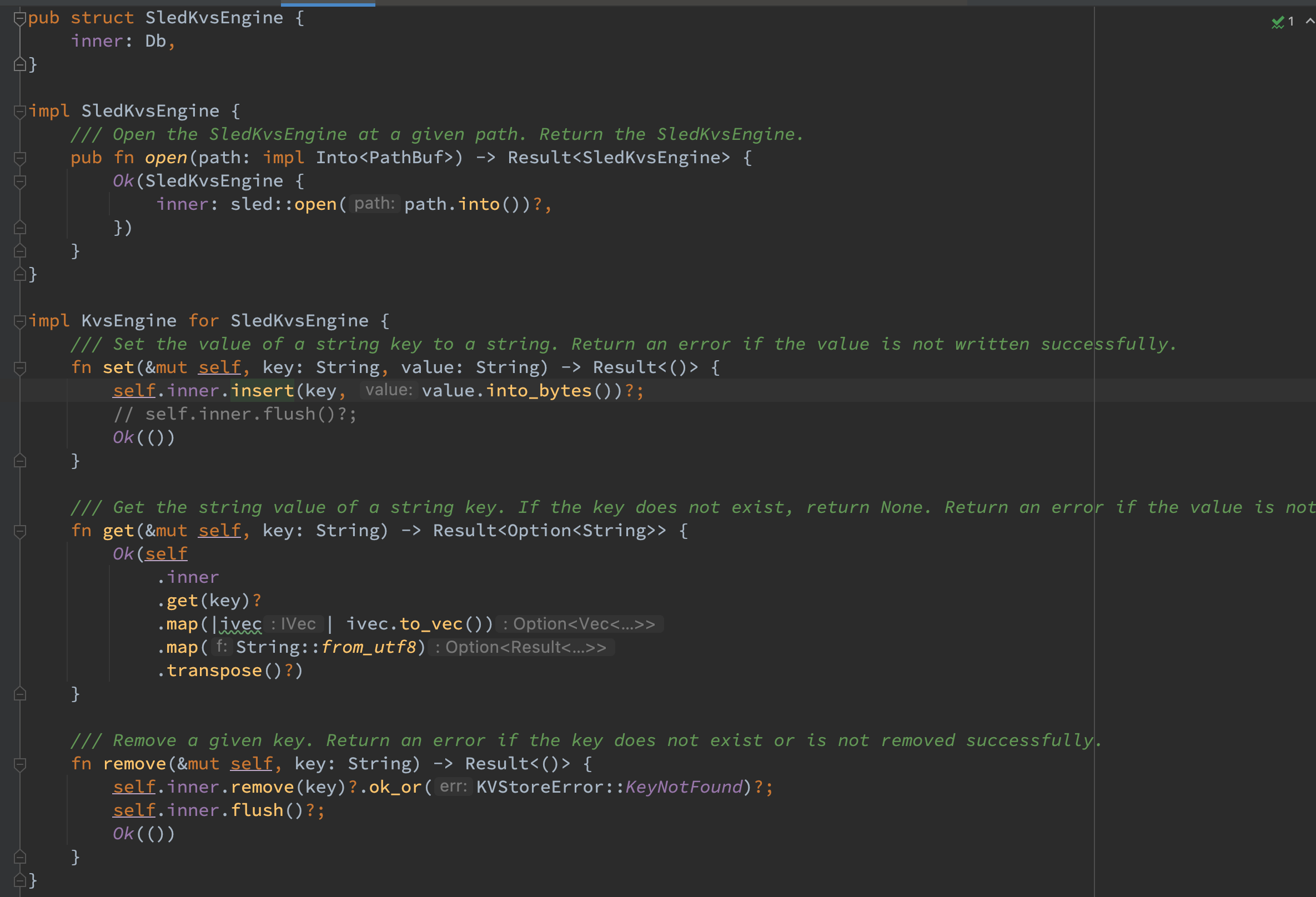
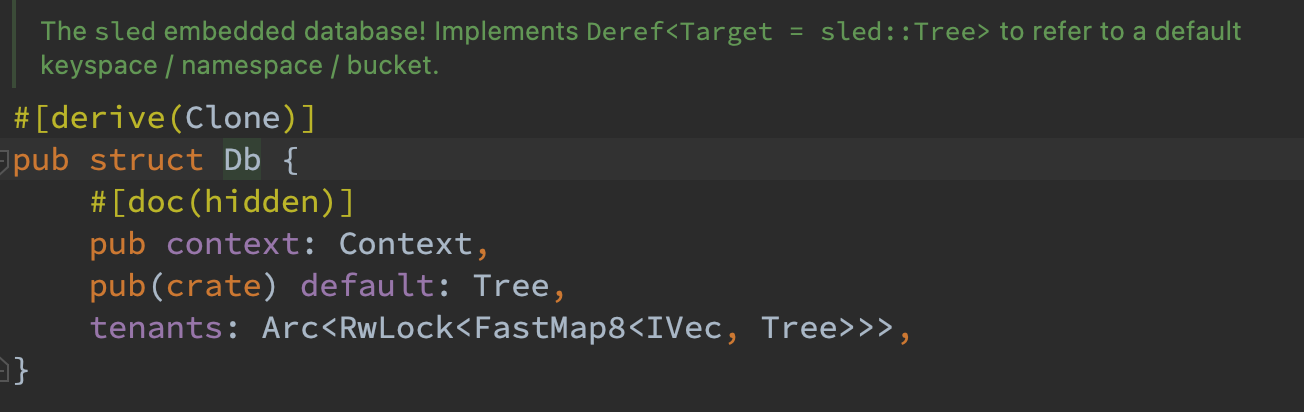
对于 Sled,同样实现了 KvsEngine 的三个方法。需要注意其默认接口的语义和格式与 KvsEngine 不一致,因而需要增加对应的转换。
此外在 set 时注释掉对应的 flush 操作是由于增加上之后性能过于慢,无法在之后的 bench 阶段跑出结果。
性能测试
参照 Project3 文档 中的介绍创建了 benches/benches 文件并参照 criterion 的 用户手册 开始构建性能测试。
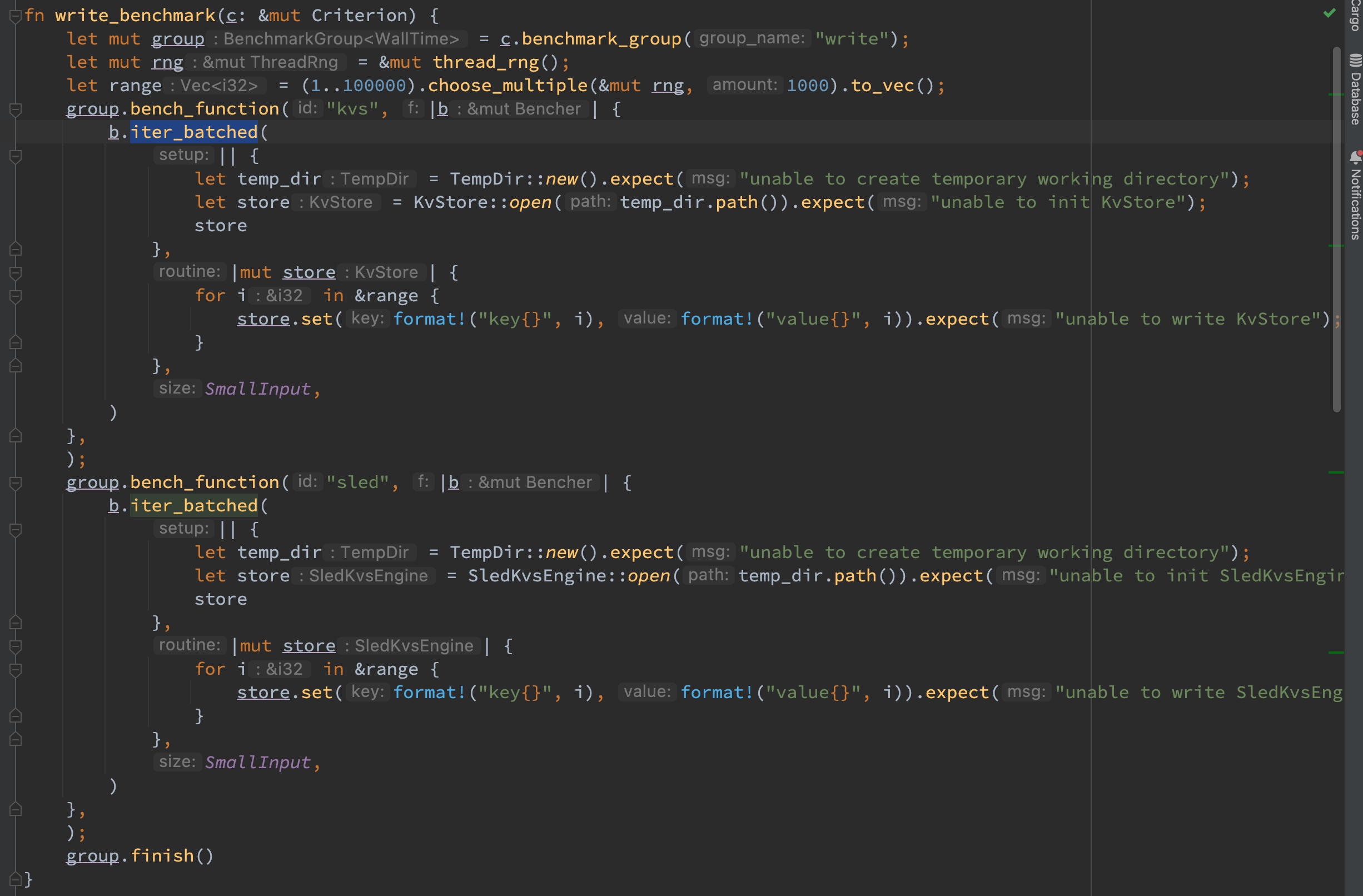
对于性能测试中的三个问题:
- 如何精准测量想要测量的时间,而不包括初始化和清理的时间:参照 criterion 计时迭代的文档 选择了 iter_batched 接口来精准测量读写的时间,初始化的清理的时间并不会被包括在内。
- 尽管使用了 rand,如何使得每次迭代都确定性:这里通过在迭代之前利用 rand 的 choose_multiple 函数创建好对应的写入数据,使得每次迭代的操作数都具有相同的集合。
- 在读 benchmark 中,如何保证选到的读集合是写集合的子集:这里采用了同样的方法,读集合是在写集合的集成上去随机选择,从而保证了读取必然能够读到。

最终性能对比如下:尽管已经去掉了 sled 每次写入时的 flush 操作来减少其随机 IO,在单线程客户端的情况下,sled 引擎的写延时大概是自写 bitcask 引擎写延时的 20 倍;sled 引擎的读延时大概是自写 bitcask 引擎读延时的 800 倍。
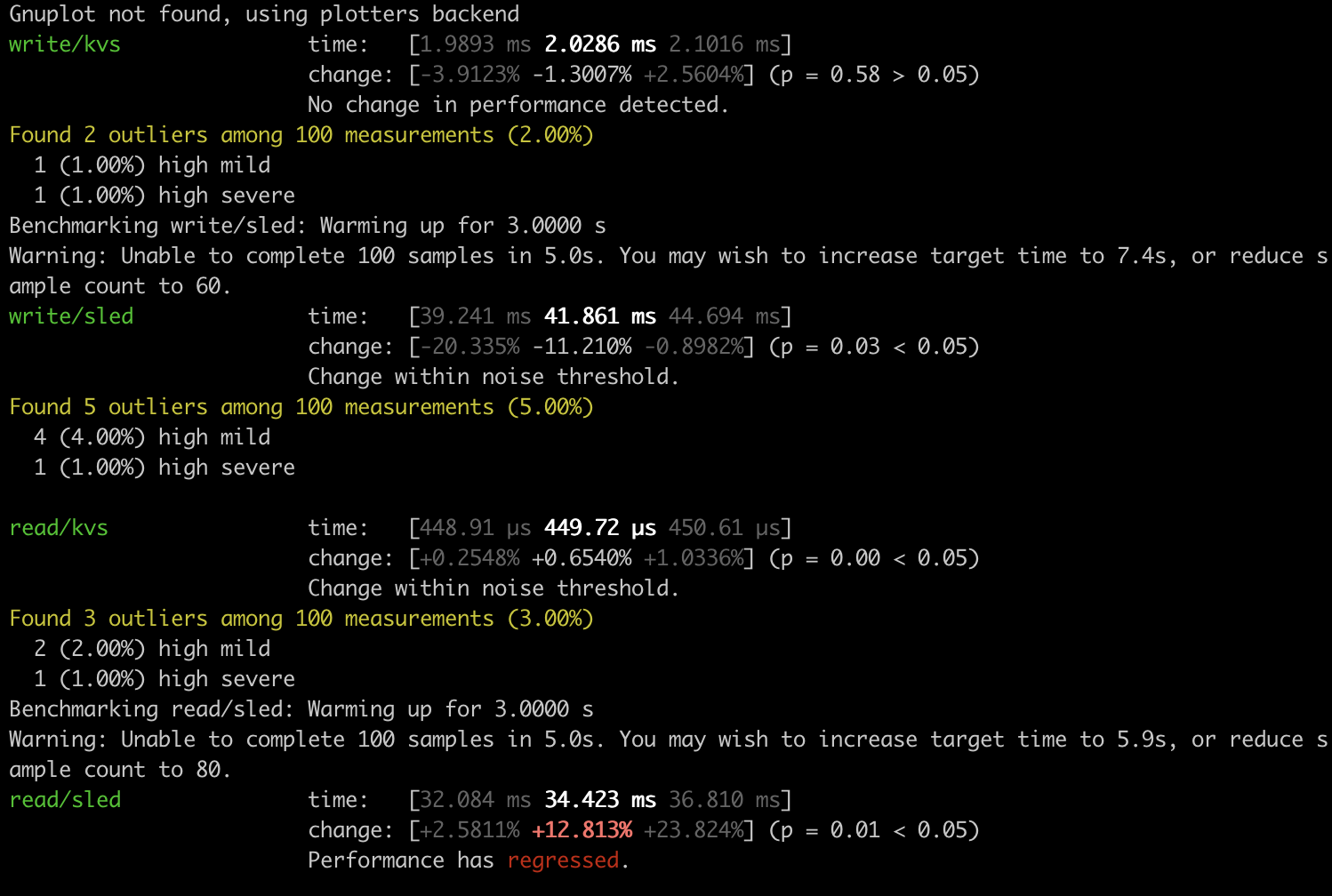
个人猜测产生如此悬殊对比的原因有可能是:
- Sled 专为多线程无锁设计,在单线程下无法体现其性能优势。
- Sled 本质上是一种树状结构,其相比 hash 结构能够提供高效的范围查询,也能够在海量数据场景与磁盘结合起来提供稳定的读延时,因而在小数据量的单点查询场景相比 hash 结构并不占优势。
- 当前自写 bitcask 模型还没有引入并发处理的开销,而 sled 是并发安全的,如此对比并不公平。
本来想用一些 profile 工具测量一下 sled 的火焰图查找一下原因,由于本人的电脑芯片是 M1Pro,许多 profile 工具类如 perf 安装还不是很方便。在参照 pprof-rs 的文档 为 criterion 配置之后依然无法打出火焰图,猜测可能跟环境有关系,便没有进一步再研究了,之后有机会在 Linux 下再进行 profile 吧。
Rust Project 4: Concurrency and parallelism
本 project 过关代码可参考该 commit。
线程池
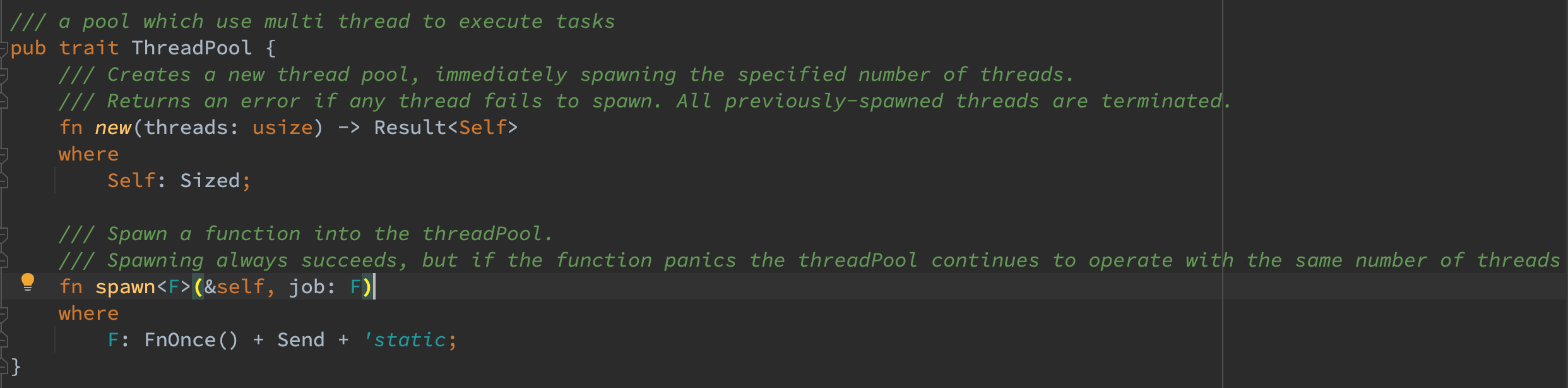
为了多线程需要抽象出线程池的概念,ThreadPool trait 定义如下:spawn 函数中的闭包 F 不仅需要满足 FnOnce() 的 bound 来满足近执行一次的语义,还要实现 Send + ‘static 的 bound 来实现线程安全的发送接收和足够长的生命周期。
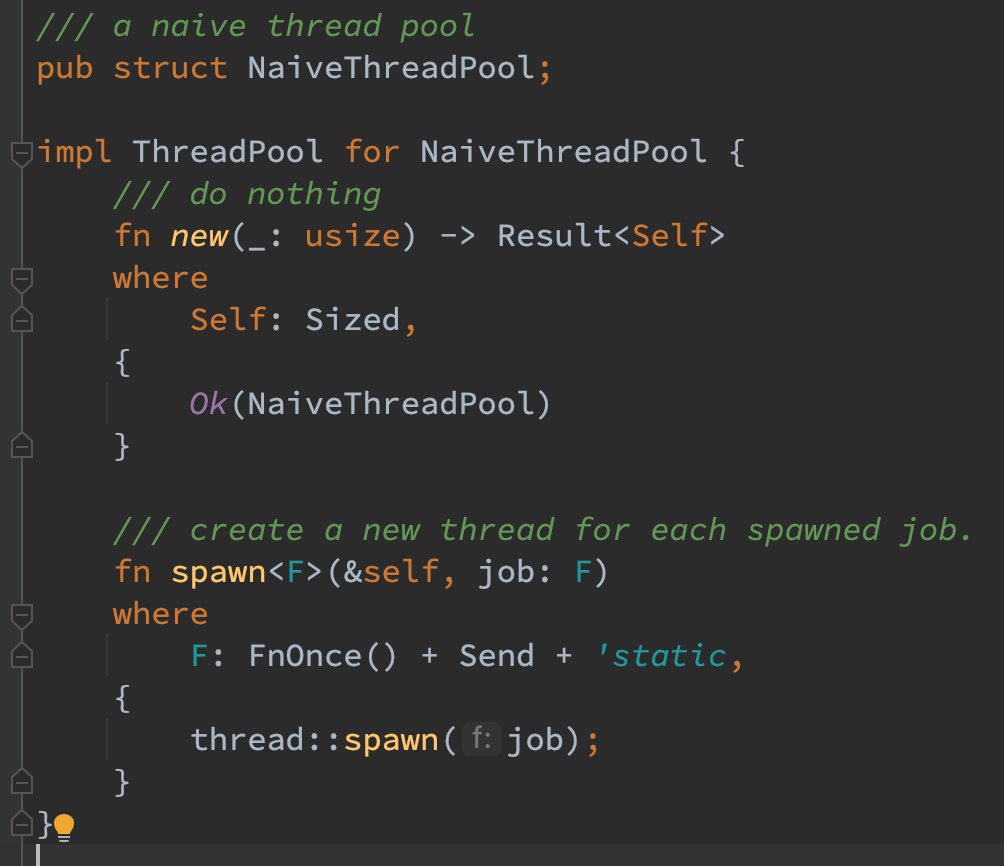
对于最简单的 NaiveThreadPool,仅仅需要在 spawn 的时候创建一个线程让其执行即可。
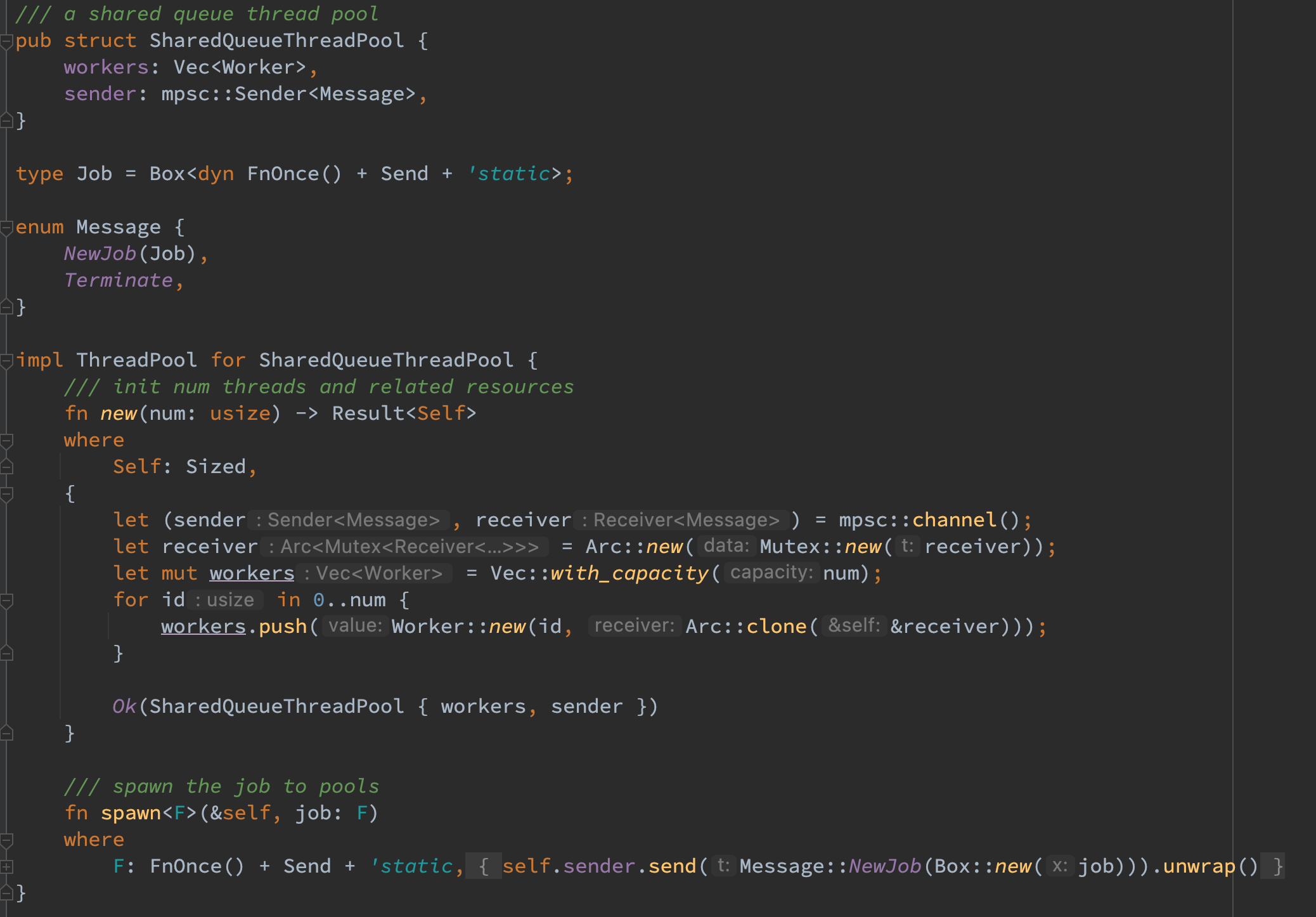
对于共享队列的 ThreadPool,参照 RustBook 中的 举例 即可实现。大体思路是用 channel 做通信,让多个子线程竞争 job 去执行即可。需要注意以下三点:
- std 库自带的 channel 是 MPSC 类型,因而可以支持并发写但不支持并发读。因而要想实现多个子 thread 对 channel 的监听便需要用 Arc
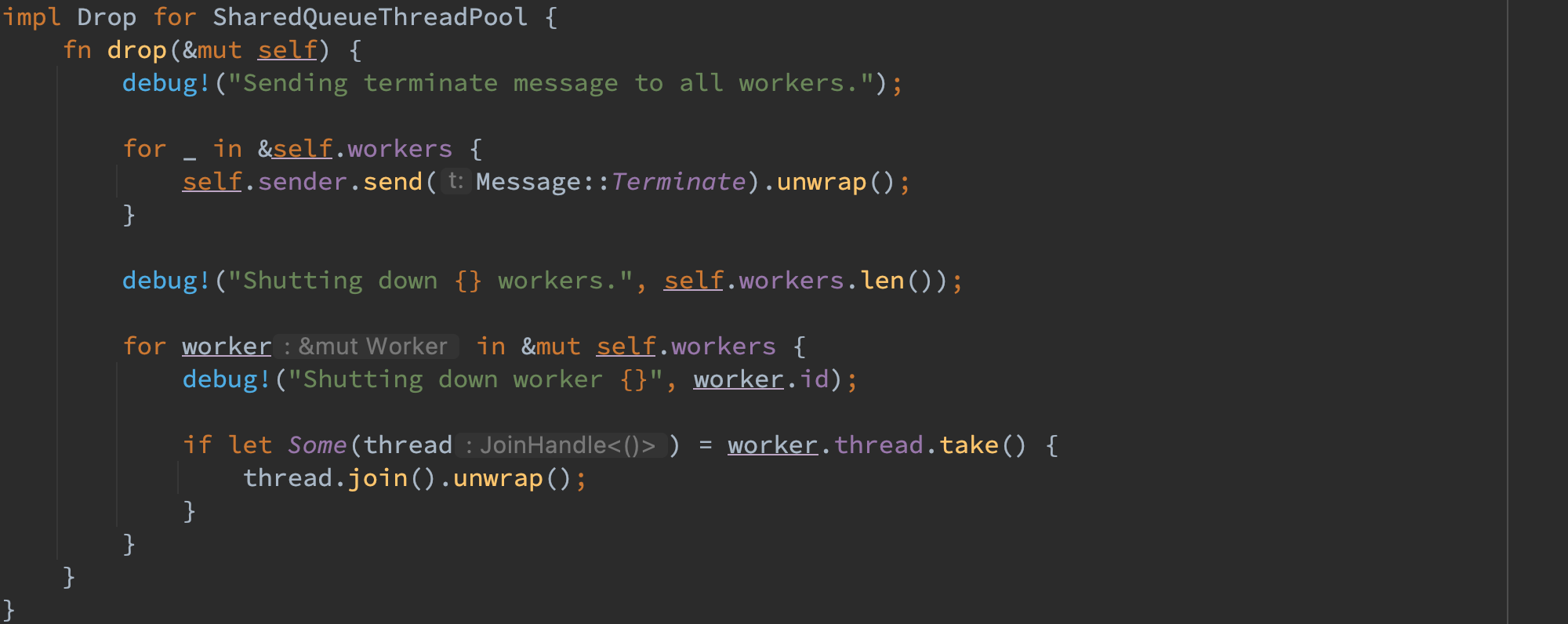
- 为了优雅停机,对于 Job 又包装了一层枚举和 Terminate 类型来支持子 thread 的优雅退出,此外还需要利用 Box 将闭包 F 放在堆上来支持线程安全的传递闭包。
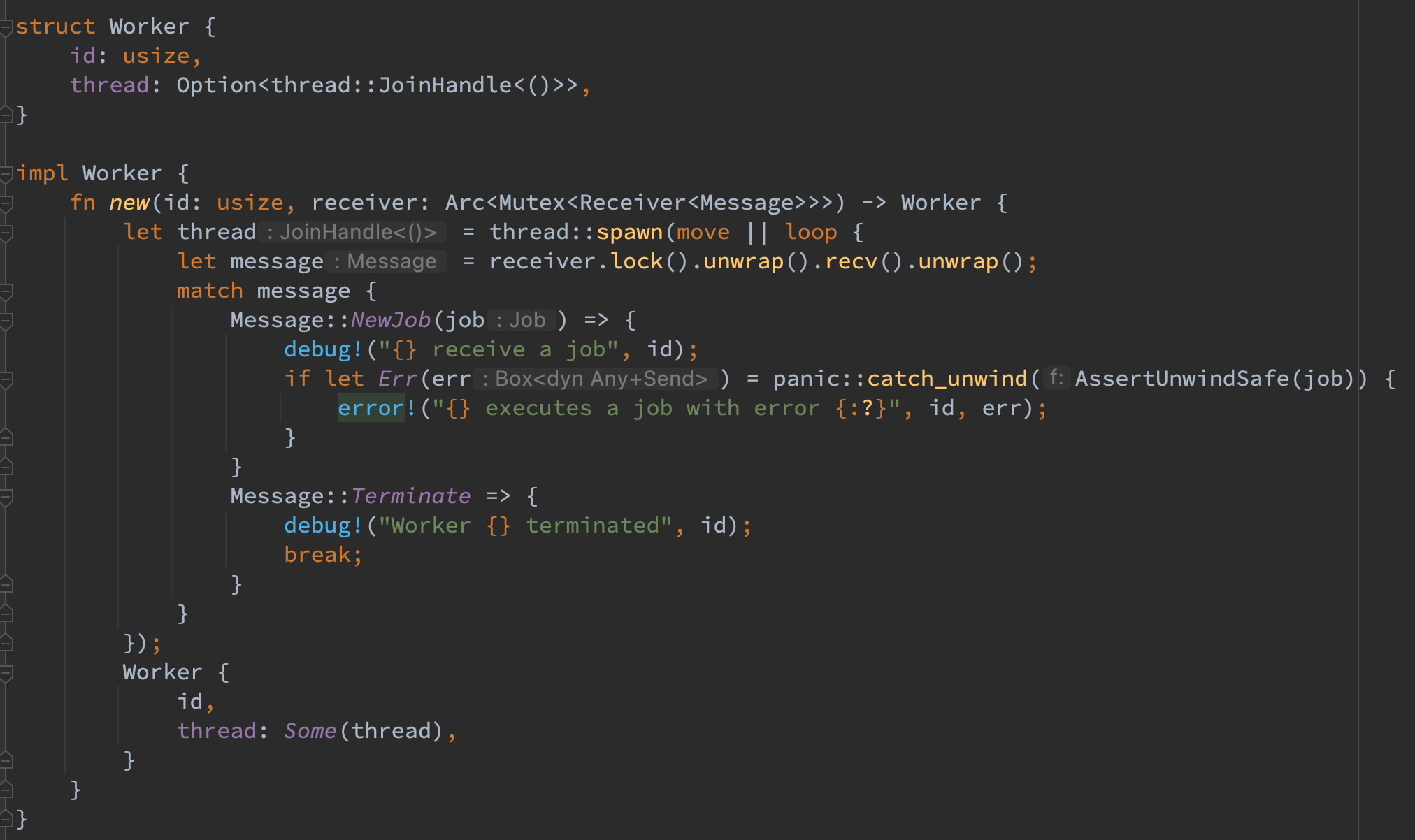
- 由于单元测试中传入的闭包可能会 panic 但不想看到线程池中的线程减少,一种方案是检测到线程 panic 退出之后新增新的线程,另一种方式则是捕获可能得 panic。例如在 Java 中可以使用 try catch 捕捉一个 throwable 的错误,在 go 中可以 defer recover 一个 panic。在 rust 中类似的语法是 catch_unwind,因而在执行真正的 job 闭包时,会使用 panic::catch_unwind(AssertUnwindSafe(job)) 的方式来确保该线程不会由于执行闭包而 panic。
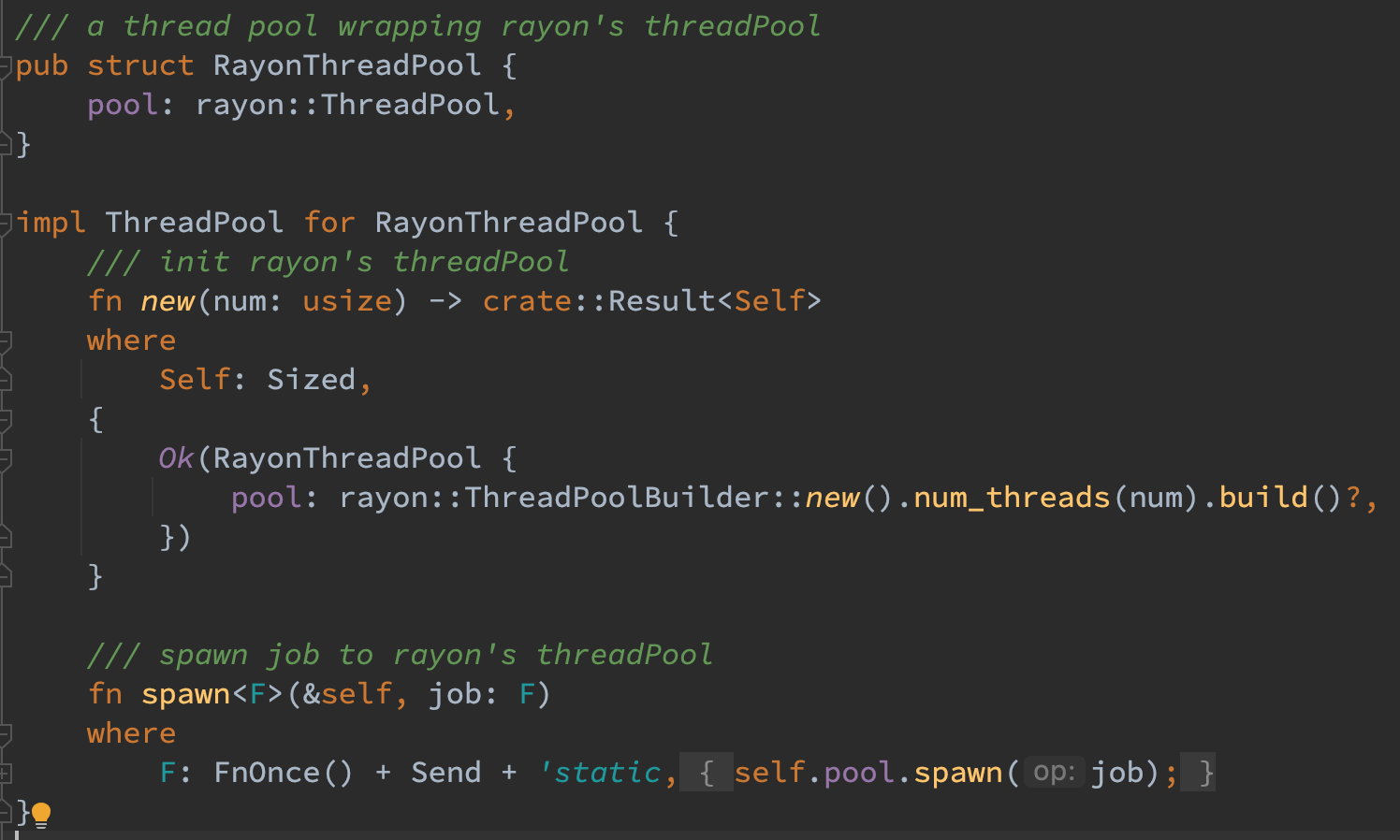
对于 RayonThreadPool,直接参考官网的样例初始化对应的 pool 并直接 spawn 给其即可。
多线程服务端
在 KvServer 初始化时使用了一个线程池来管理不同 tcp 连接的读写,这样便可以使得并发的请求能够在多核 CPU 的服务端并行执行而不是并发执行。
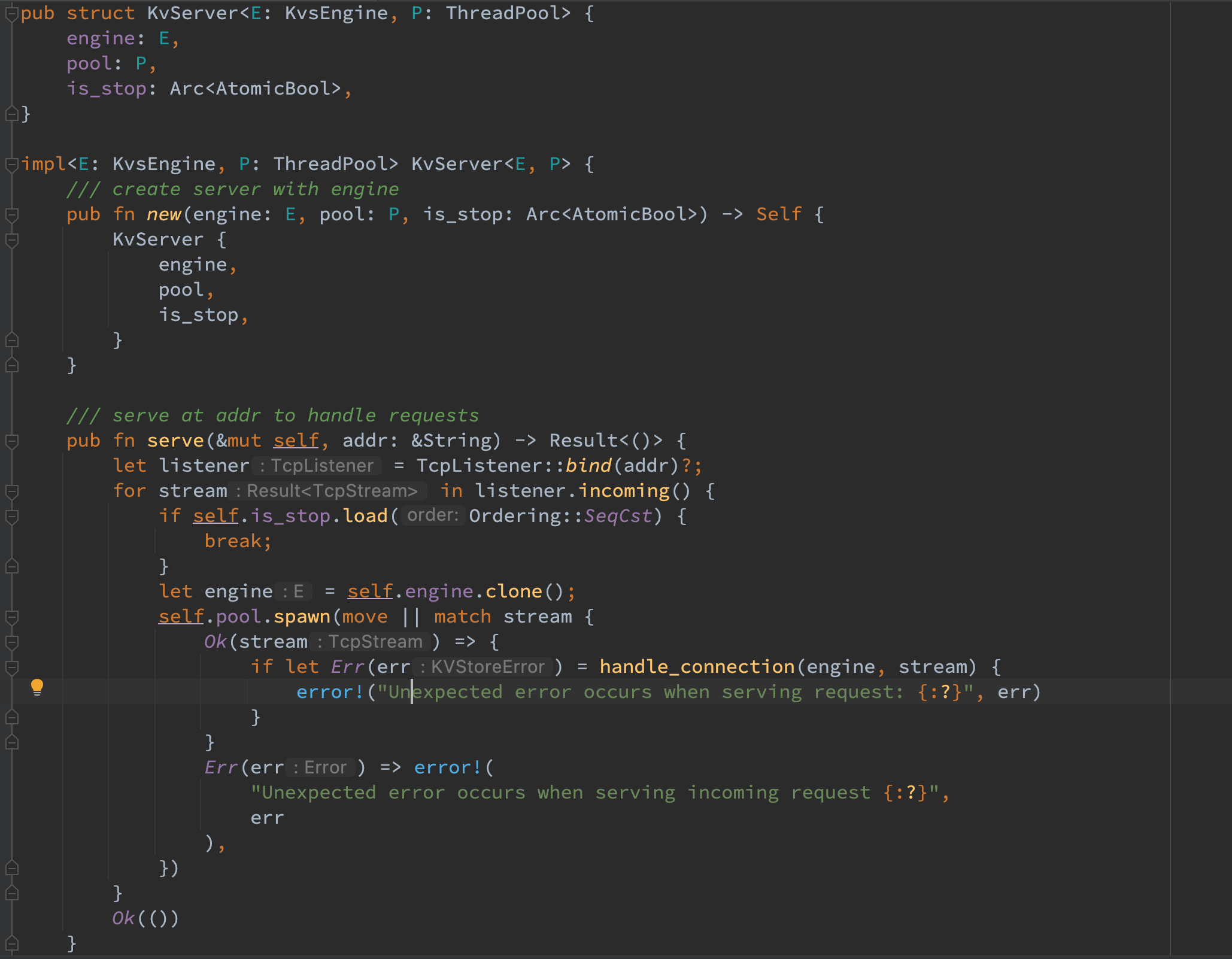
注意在 KvServer 中还维护了一个 is_stop 的原子变量,该变量的作用是能够便于当前线程结束阻塞等待进而退出。之所以阻塞的原因是由于 tcplistener 的 incoming() 函数是阻塞的,因而一旦进入 serve 函数当前线程就阻塞了。在之后的性能测试中可能一个线程内想在启动 server 后开始迭代测试并最后关闭 server 并进行下一轮测试:此时如果是同步的写法就无法执行 serve 之后的函数,如果新建一个线程则无法在迭代测试之后通知该线程结束,因而加入了该原子变量之后不仅可以异步启动 server 从而在当前线程进行性能测试,又能够在当前线程的测试结束后以新建一个空 client 的方式关闭 server 以便下一轮测试不会再出现 address already in use 的错误。
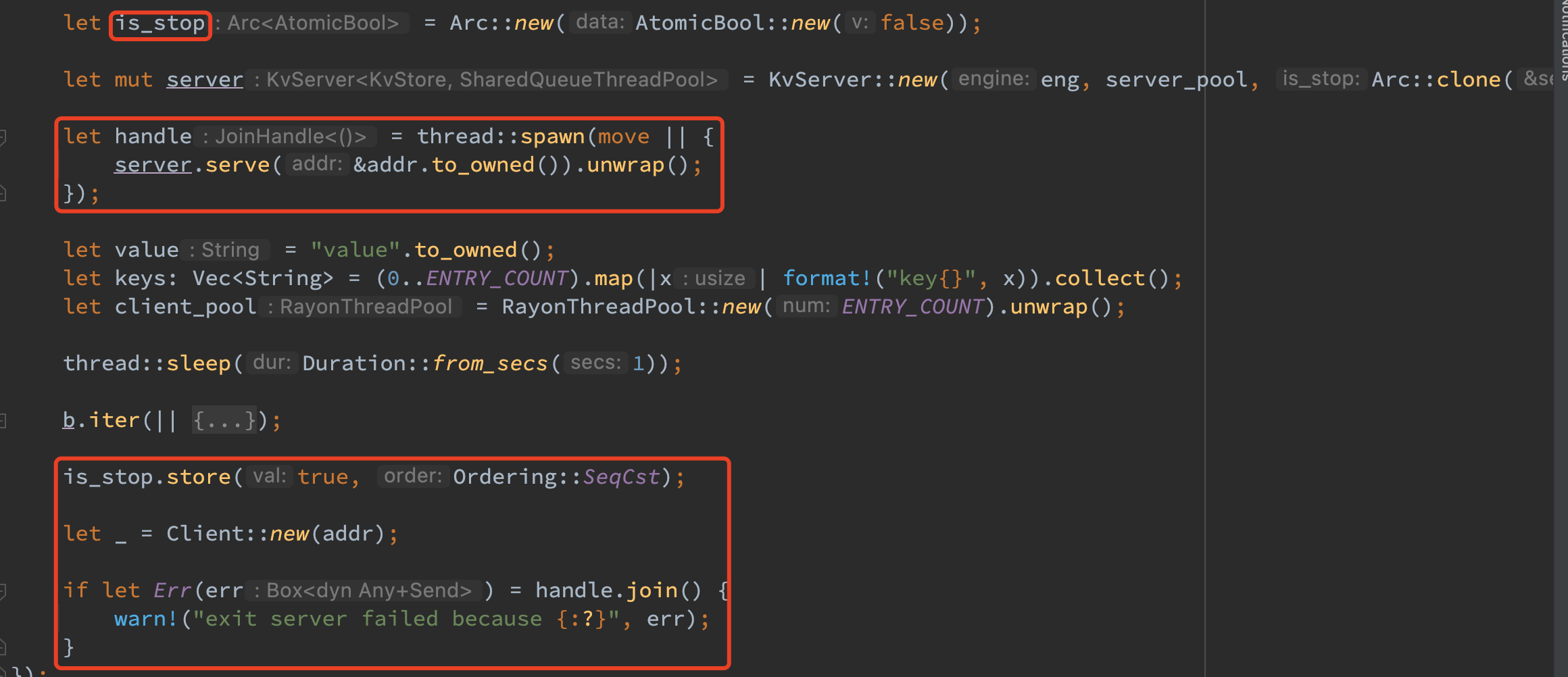
KvsEngine 线程安全
KvsEngine trait 需要满足 Clone + Send + ‘static 的 bound,同时三个对应的接口也可以去掉 &mut,因为变量的所有权和可变性已经转移到了智能指针中。
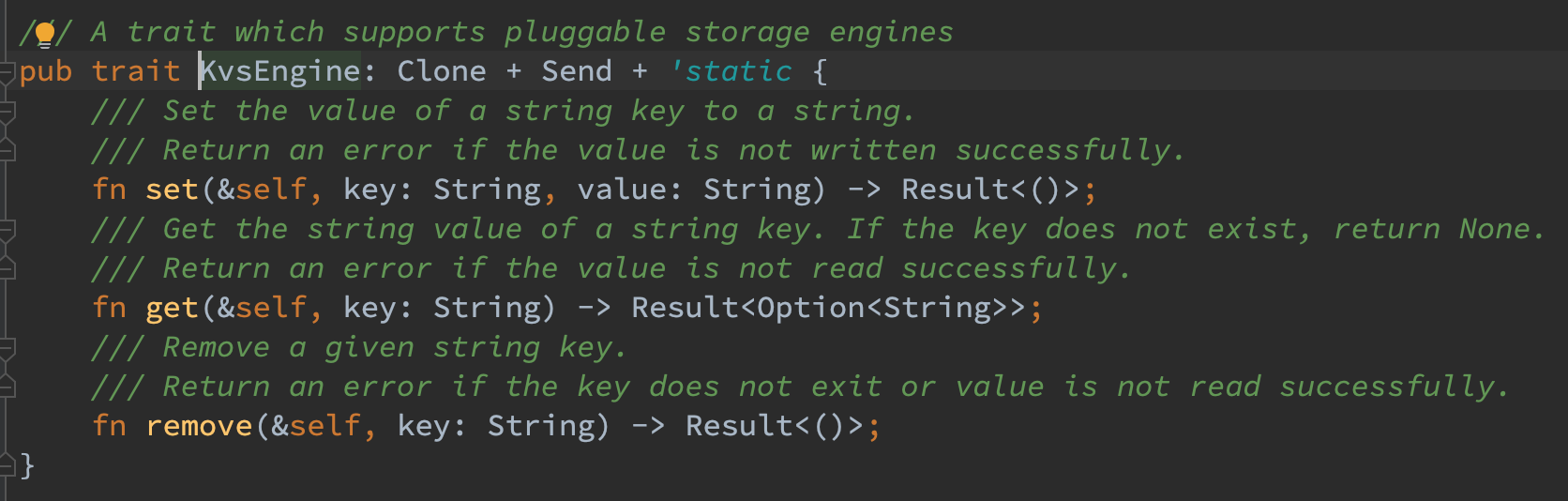
SledKvsEngine 线程安全
Sled 引擎本身支持并发读写,因而直接对结构体 derive(Clone) 即可,其 set/get/remove 函数仅需挪去 self 的 &mut 即可。
KvStore 线程安全
KvStore 的线程安全则需要对之前的结构体做大量的改造,改造之后的 KvStore 不仅支持读写请求互相不阻塞,甚至对同一 FileReader 的读请求也可以不在应用层阻塞。
- 对于 index 结构,将其转换为了并发安全的 DashMap 结构,同时又增加了 Arc 指针以便于在不同线程间共享。

- 对于 writer 结构,由于对同一文件的 append 操作从语义上来说便不支持并行,因而便通过 Arc
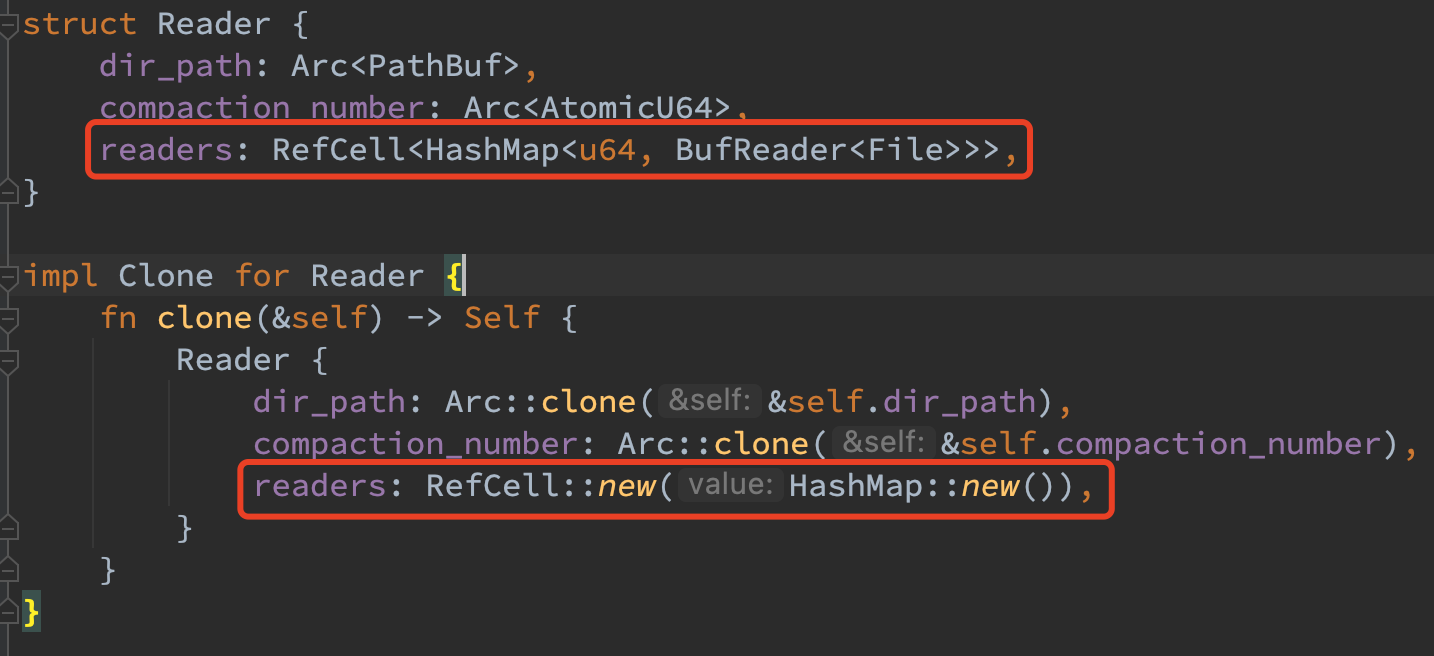
- 对于 readers 结构,我参照了部分 project4 样例的源码设计进行了无锁实现。注意其内部的 readers 在 clone 时并不是拷贝指针,而是初始化一个全新的 map,因而当多线程读同一个文件时,会创建多个 reader,这些 reader 可以在应用层对同一个文件执行并发的 IO 读请求。使用 RefCell 包装的原因是由于接口并未提供可变引用,如果还想保留对 map 的更改权限就需要用到 RefCell 了。
- 最容易想到的一种读请求并发控制方案是在上层做一定的串行以使得每个文件最多同时只有一个读请求在执行,从而减少磁盘的随机 IO。但实际上这样的设计并不一定有效果,一方面由于在文件系统中一个 file 的所有 data block 不一定完全在连续的 block 上,因而仅仅限制对一个文件不能并发读而不限制对多个文件不能并发读不一定能够起到减少随机 IO 的效果,另一方面 linux VFS 下的 IO 调度层本来就已经会对 IO 请求通过电梯算法等方式来做一些乱序处理来减少随机 IO,如果完全在上层做了串行反而会丢失部分可优化吞吐的空间。因而如果系统还没到完全掌握磁盘快中数据的分布来减少随机 IO 的地步,可以先尽可能的将读请求并行起来让底层去串行,而不是在上层就做好串行。
写流程
由于 append 的写请求语义上就不能并行,因而当前 KvsEngine 的 set 请求被全部串行了起来

删除流程
由于删除也需要顺序 append,因而其语义与 set 类似不能并行,因而当前 KvsEngine 的 remove 请求也被全部串行了起来
读流程
读流程语义理论上可以并行执行,因而首先在可并发读的 DashMap 中获取到索引,接着在当前线程内读取对应的 file_number 的 reader,如果当前线程不存在该 reader 则创建出对应的 reader 读取即可(使用了 entry API 来避免两次 hash)。
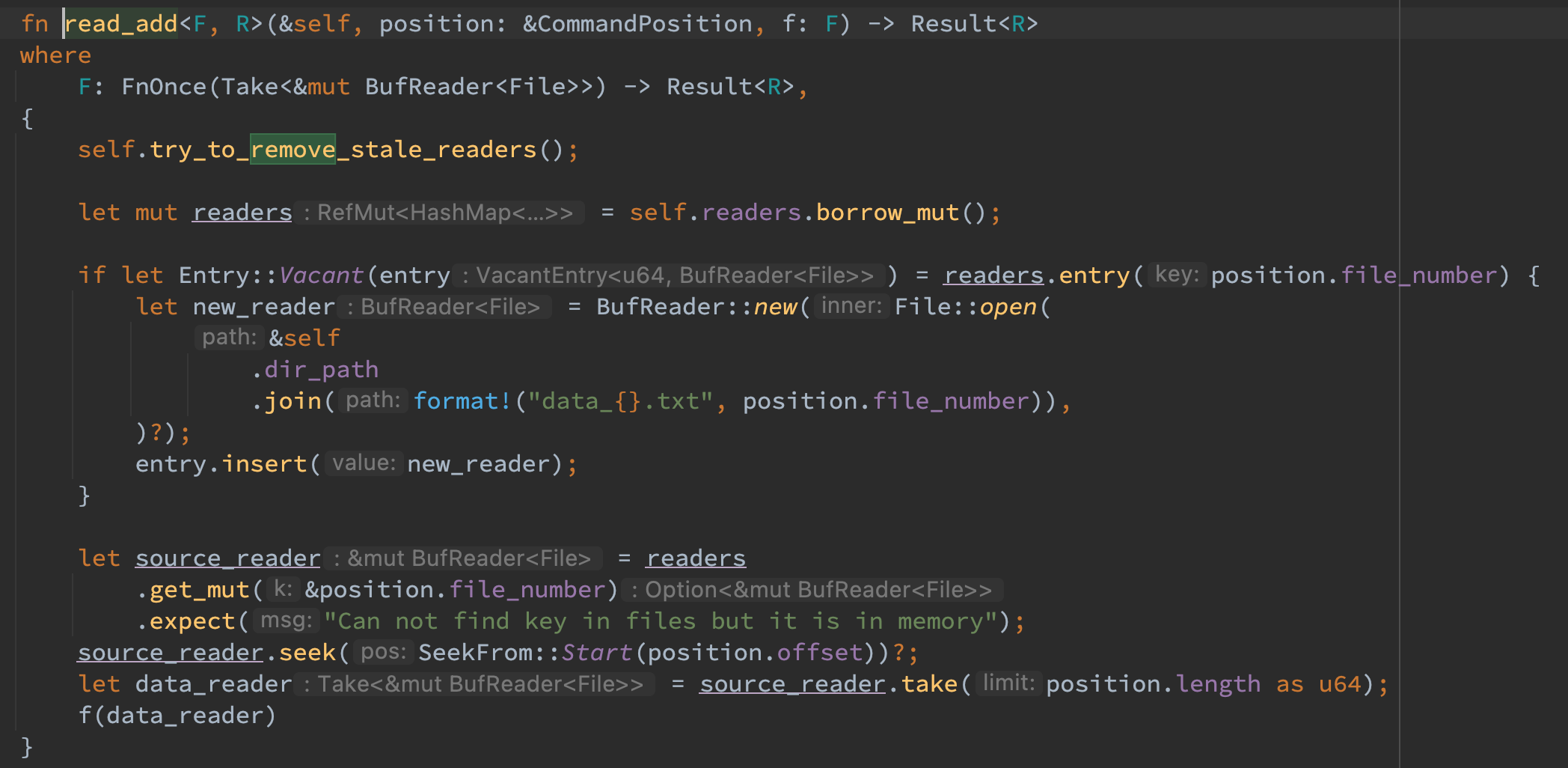
合并流程
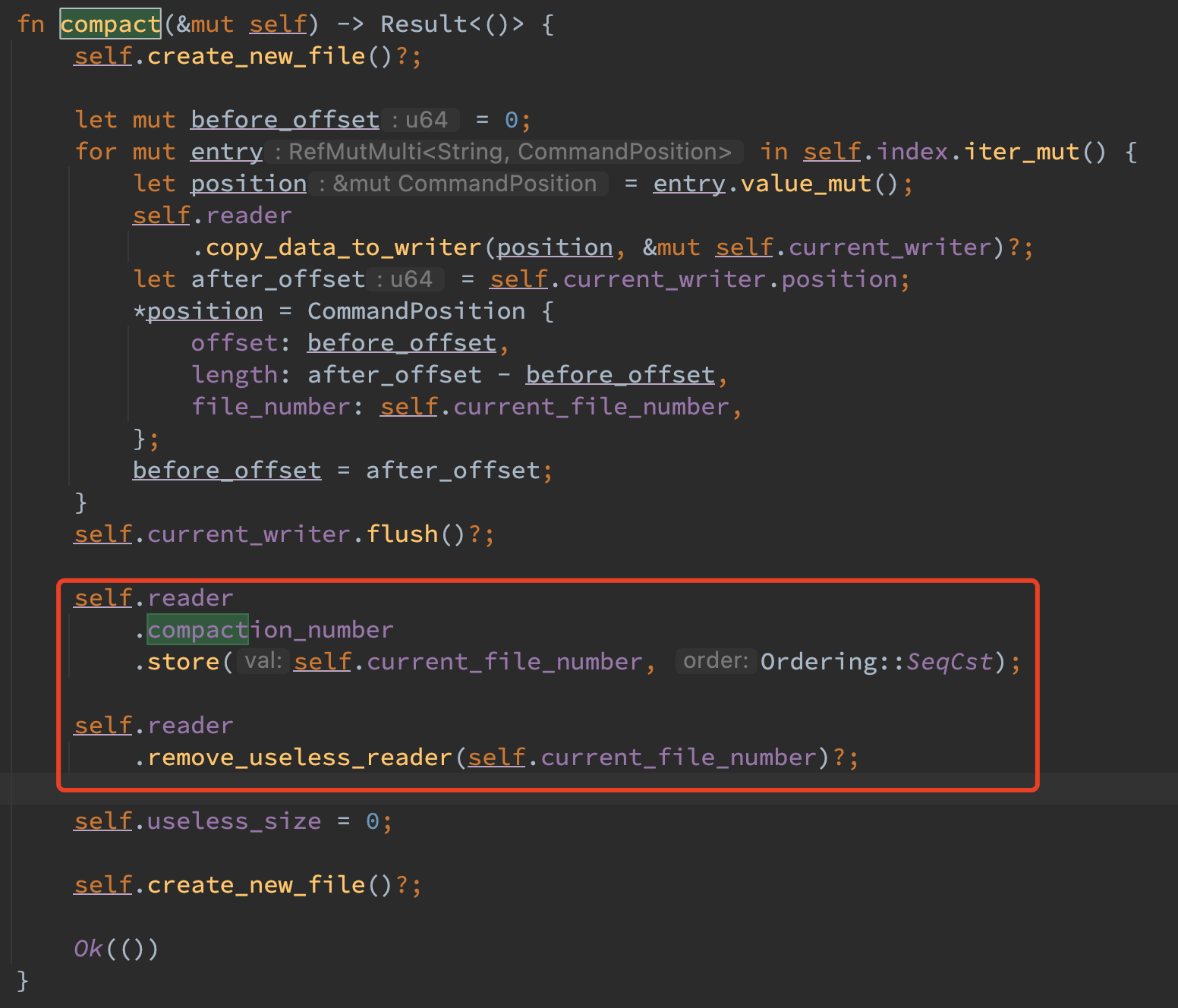
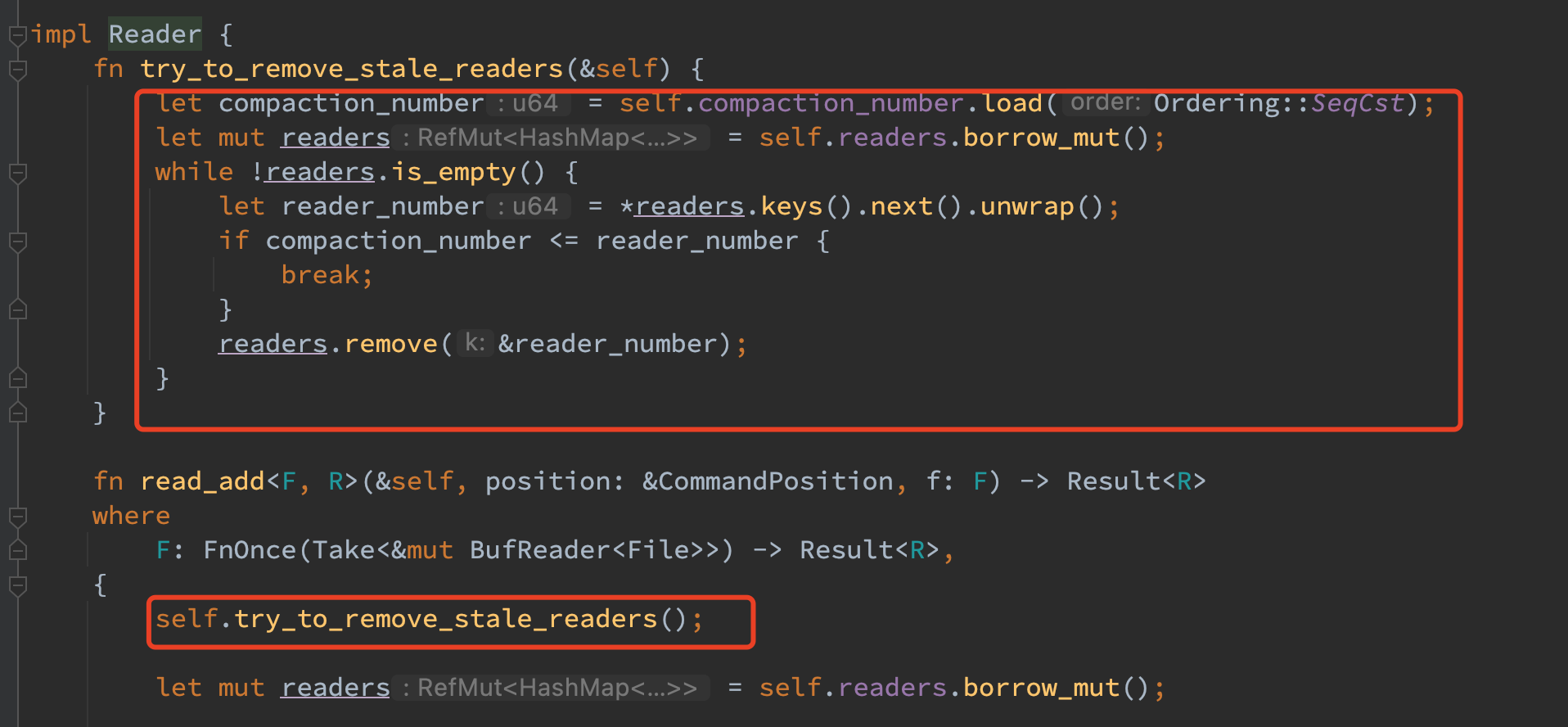
在实现无锁读之后,reader 的清理便不再能够串行起来了,因而需要一个多线程共享的原子变量来记录最新 compaction 之后的 file_number,小于这个 file_number 的文件和对应的 reader 便都可以删除了。
compact 流程会始终持有 writer 的写锁,因而此时并不存在并发安全问题,其在结束后会尝试删除掉过时的文件。不过该删除并不会影响其他读线程的 reader 句柄继续读去文件,这与 linux 文件系统的实现原理有关,直到任何线程都不存在指向该文件对应 inode 的句柄时便可以安全的释放该文件了。

对于 reader,在 compaction 中其执行的索引尽管可能文件已经被删除了,但由于其持有句柄因而始终能够读到数据,在 compaction 之后其执行的索引一定是更新的文件,因而老的 reader 便不会再被用到,如果这些老 reader 一直不被释放,则可能导致合并过后的老文件始终无法在文件系统被释放,最终导致磁盘变满。因此在每次查询时都可以判断一下该原子变量并尝试删除本线程的老 reader,这样便可以既实现 lock-less 的 reader 又满足 compaction 消息的无锁感知和对应的资源清理了。
性能测试
按照题意写出对应的六个 benchmark 即可,主要做了以下工作:
- 使用 Once 接口来确保在多个函数中 logger 仅被初始化一次,从而避免报错。

- 使用了 bench_with_input 接口来支持不同线程数的对比

- 使用了之前提到的方式来异步启动 server 并在一轮迭代结束后回收 server。
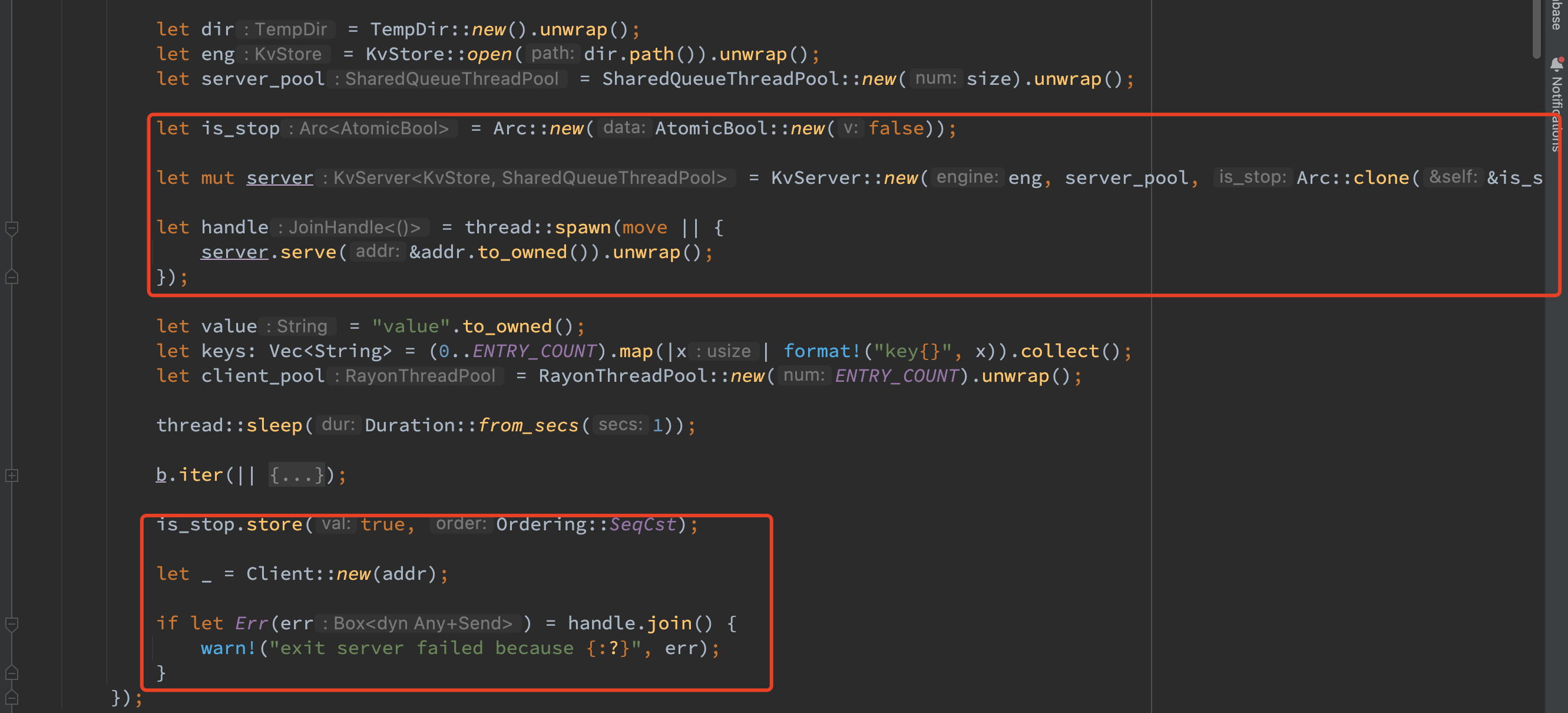
- 使用了 waitGroup 来实现客户端线程和迭代线程的同步。
- 减少 sample_size 来加快性能测试时间。

最终的测试结果如下:
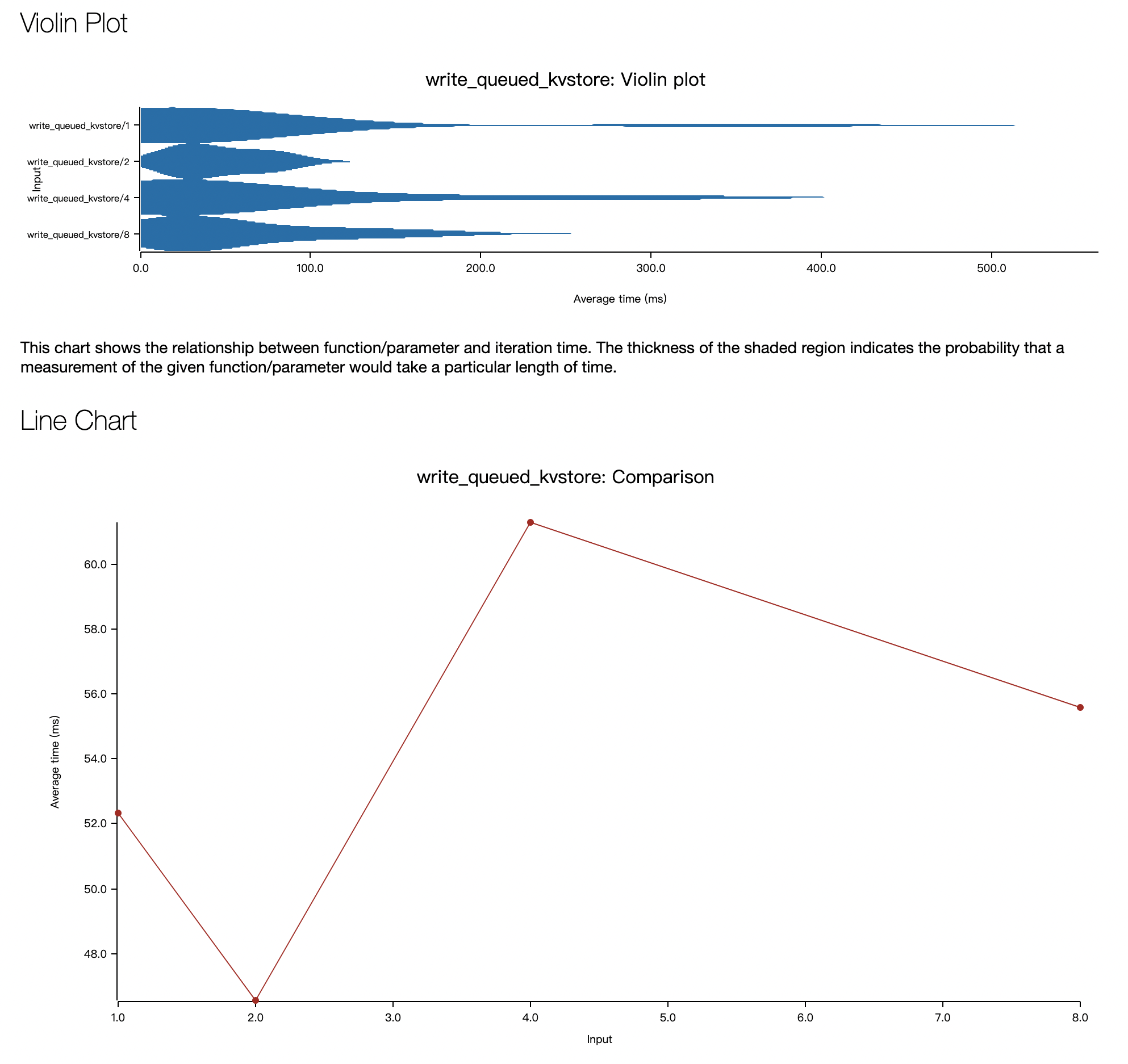
- write_queue_kvstore:随着线程数增大,延时先降再升,但变化幅度不大,尽管 read/write socket 可以并行起来了,但 set 还是必须得串行起来,与实现基本相符。
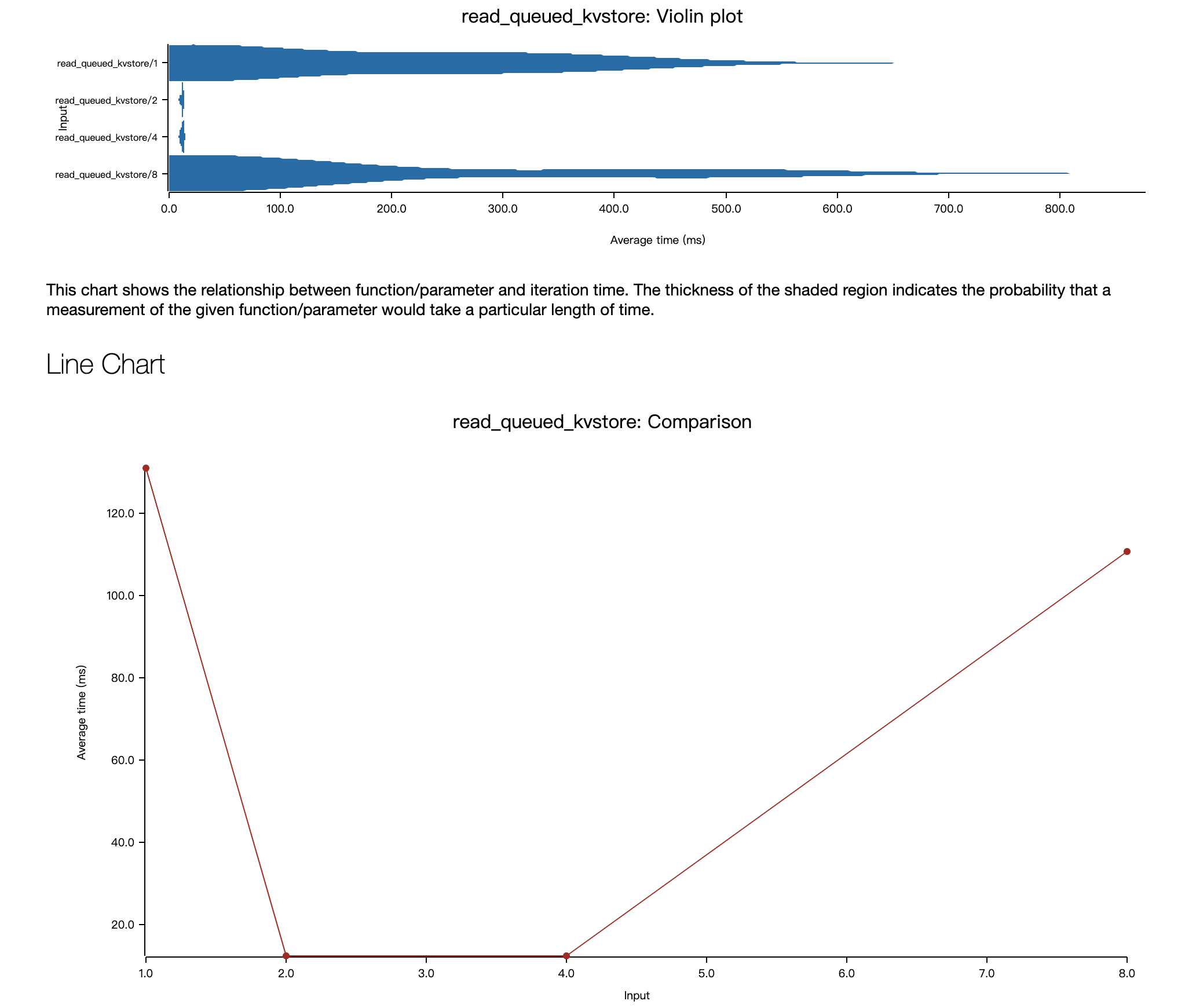
- read_queued_kvstore:随着线程数增大,延时先大幅度降低再大幅度升高,大幅度降低符合预期,因为不同的读请求现在可以串行起来,大幅度升高则不太符合预期,观察到了客户端建立连接 Timeout 的现象,不确定是否与本地的 Mac M1 Pro 环境有关。
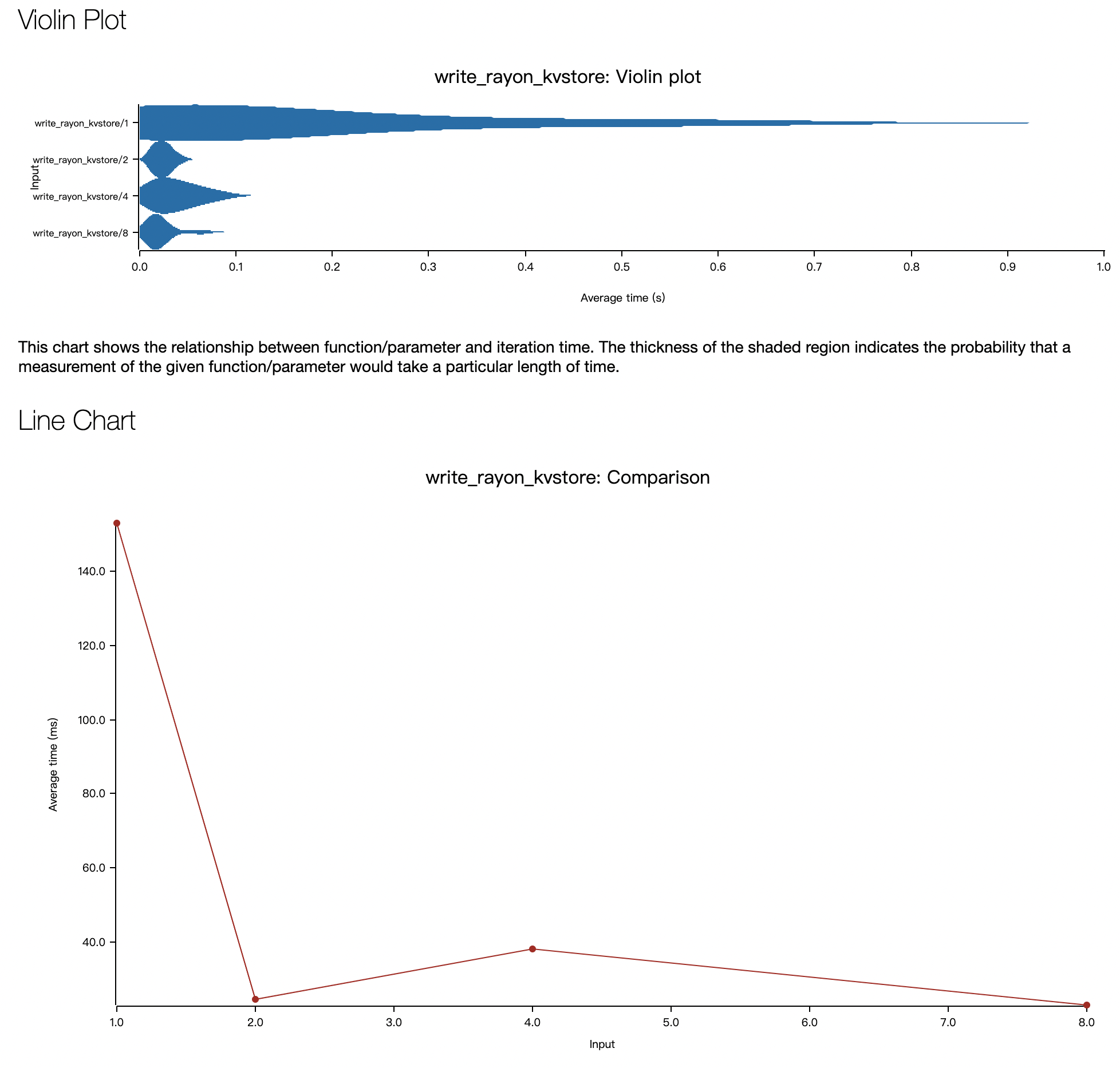
其他测试:
- write_rayon_kvstore
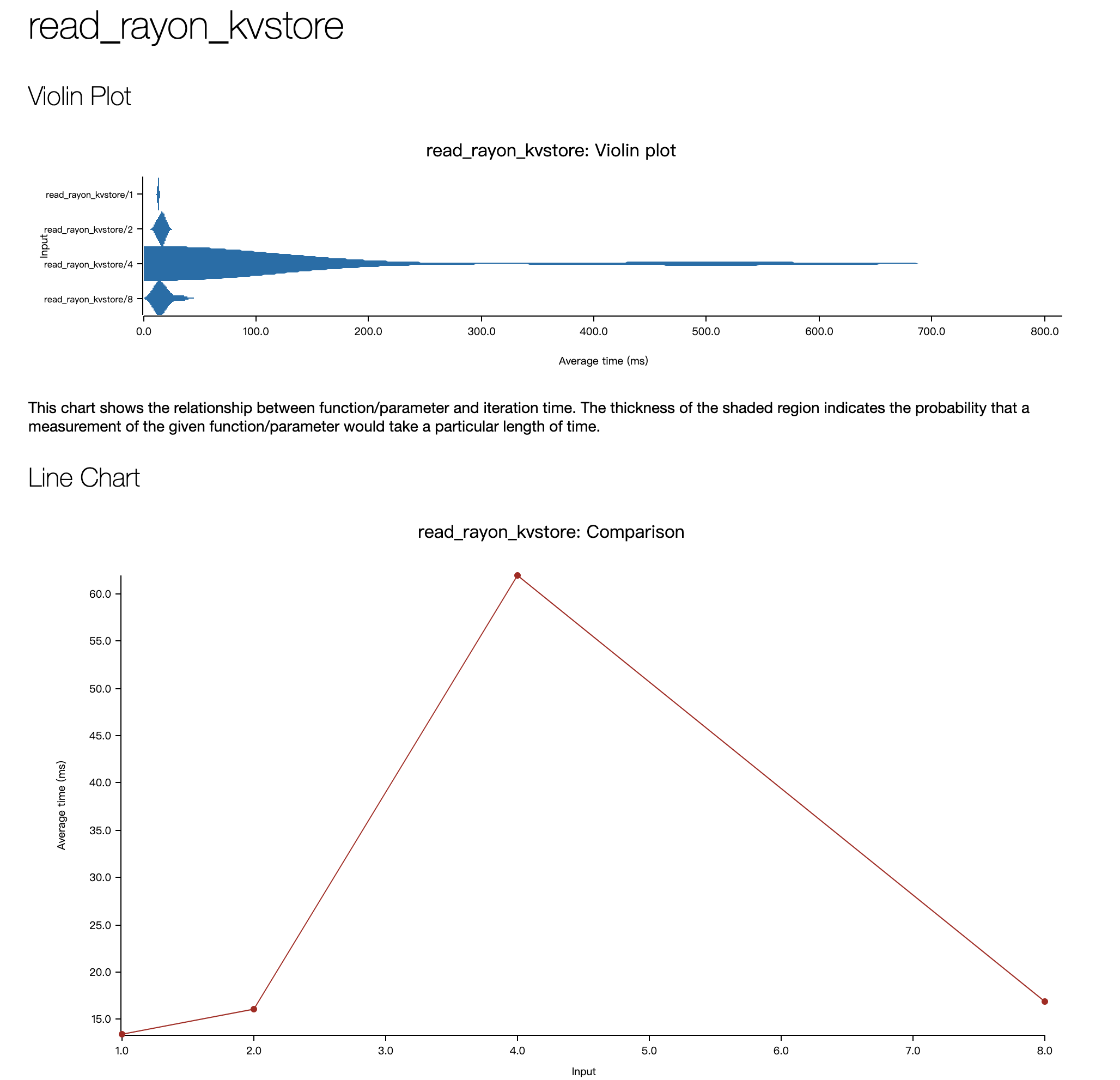
- read_rayon_kvstore
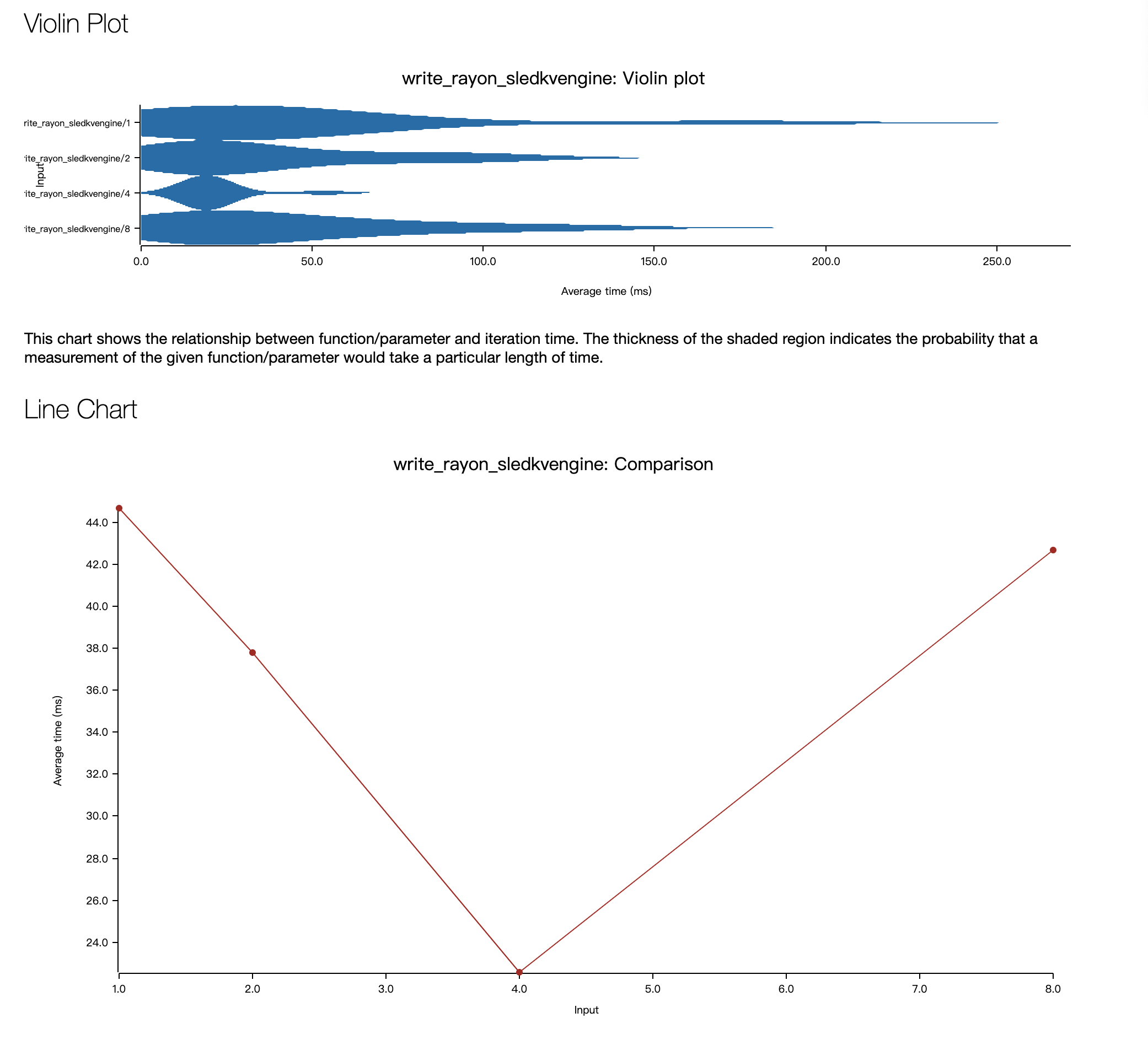
- write_rayon_sledkvengine
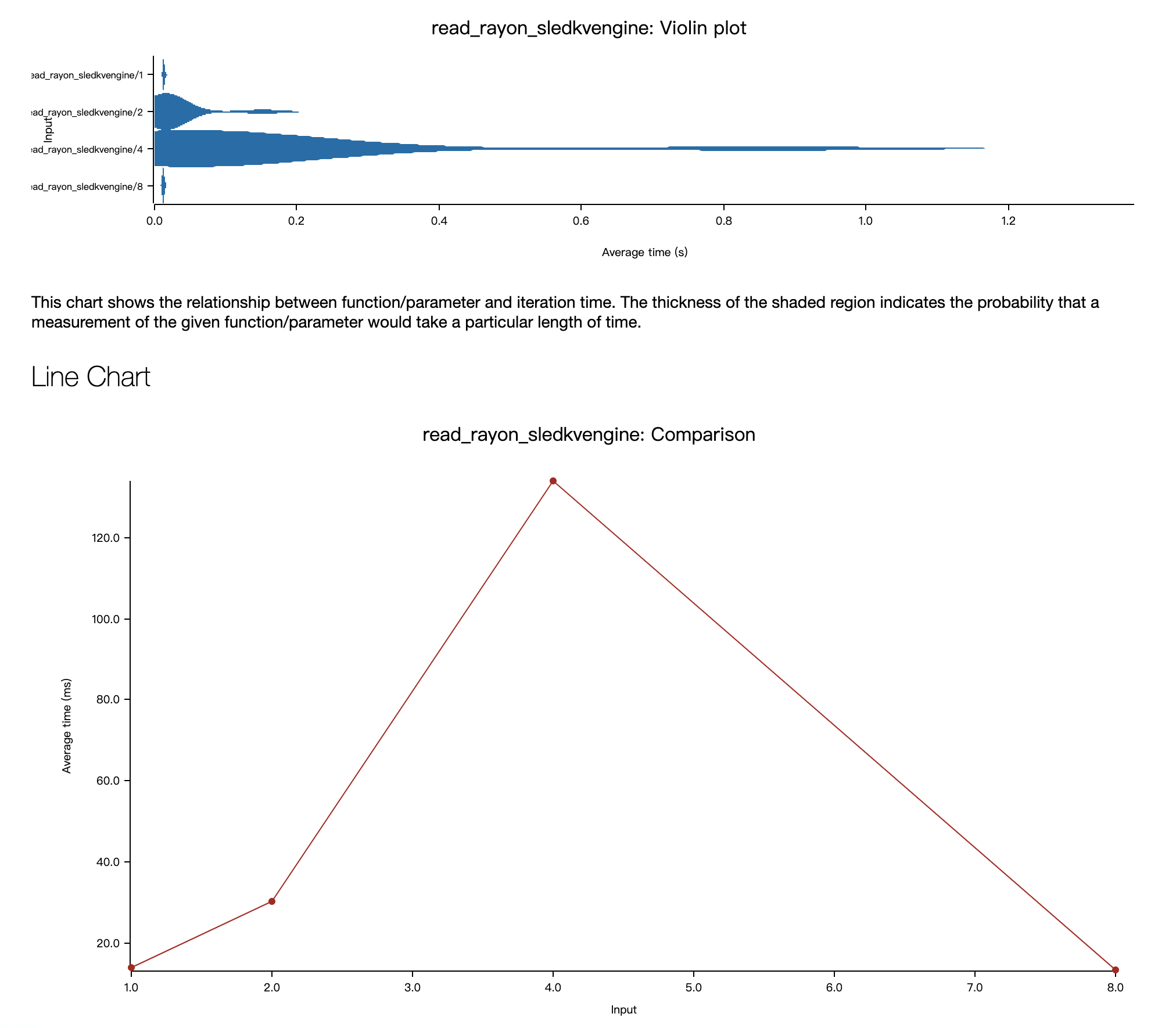
- read_rayon_sledkvengine
测试总结:
- 总体来看,不同的存储引擎,不同的线程池策略,随着服务端线程池的线程数增大,延时都能够在某点得到最小值,这说明并行能够在部分场景起到效果。
- 在 MacOS M1 Pro 的环境上测试性能不太稳定,还容易出现 timeout 的情况,因而便没有进行更详细分析,感觉要想真的对比出性能的差异,还是需要在 Linux 环境下配上稳定的 CPU,磁盘,网络的可观测性工具结合不同引擎和不同线程池的内部 metric 来分析原因。害,底层软件就是这么难测试。
总结
通过本 Rust Lab,总共写了大约 2000+ 行的 Rust 代码。从 Cargo 包管理到 Rust 的所有权机制,然后到错误管理和若干标准库三方库的使用,再到线程池和并发引擎的设计以及异步 Runtime 的学习,虽然在性能测试和对比部分做的并不完善,但这些内容已经涵盖了开发大型 Rust 项目的方方面面。
下一步计划开始从 TiKV 的小 issue 入手,进一步深入学习 Rust。