Spark 论文阅读
背景
在 Apache Spark 广泛使用以前,业界主要使用 MapReduce 和 Dryad 这样的集群计算框架来对大数据进行分布式处理。这类计算框架,最大的优点旨在帮助程序员专注业务编程,而非花精力分发计算任务和实现程序容错。
MapReduce 虽然对利用集群中的计算资源做了各类抽象,但还没有实现对集群内存的抽象封装。这样对那些需要重复利用中间结果集的应用就很不友好,比如机器学习和图算法,PageRank, K-means 聚类以及逻辑回归等等。此外,MapReduce 也很难支持高效的交互式数据分析,因涉及大量的即席数据查询,为确保下一次数据集可以被重用,需要借助存储物化结果集,这引发大量写入实体磁盘的操作,导致执行时间拉长。
意识到这个问题的存在,学者们做了大量尝试,比如 Pregel,它把大量中间数据缓存起来,专为图计算封装了框架;HaLoop 则提供了实现迭代算法的 MapReduce 接口。但这些仅仅对个案有帮助,回到通用的计算上来,毫无优势。比如最常见的数据分析,装载多样化多源头数据,展开即席查询等等。
综上,MapReduce 的局限可以总结为:
- 编程模型的表达能力有限,仅靠 MapReduce 难以实现部分算法。
- 对分布式内存资源的使用方式有限,使得其难以满足迭代式分析场景和交互式分析场景,比如迭代式机器学习算法及图算法,交互式数据挖掘等。
Spark RDD 作为一个分布式内存资源抽象便致力于解决 Hadoop MapReduce 的上述问题:
- 通过对分布式集群的内存资源进行抽象,允许程序高效复用已有的中间结果。
- 提供比 MapReduce 更灵活的编程模型,兼容更多的高级算法。
RDD
RDD(Resilient Distributed Dataset,弹性分布式数据集)本质上是一种只读、分片的记录集合,只能由所支持的数据源或是由其他 RDD 经过一定的转换(Transformation)来产生。通过由用户构建 RDD 间组成的产生关系图,每个 RDD 都能记录到自己是如何由还位于持久化存储中的源数据计算得出的,即其血统(Lineage)。
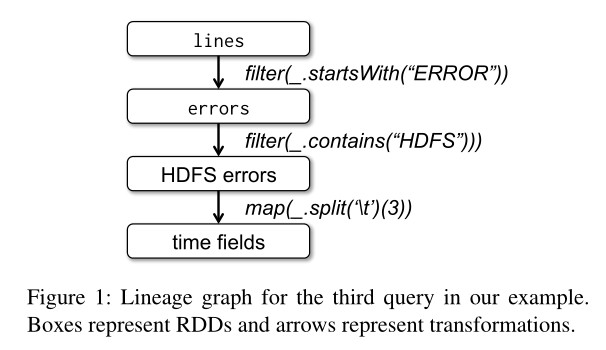
Spark 为 RDD 提供了 Transformation 和 Action 两种操作,前者可以从其他数据源读入数据生成 RDD 或利用已有的 RDD 生成新的只读 RDD。后者可对 RDD 进行计算操作并把一个结果值返回给客户端,或是将 RDD 里的数据写出到外部存储。
![]()
Transformation 与 Action 的区别还在于,对 RDD 进行 Transformation 并不会触发计算:Transformation 方法所产生的 RDD 对象只会记录住该 RDD 所依赖的 RDD 以及计算产生该 RDD 的数据的方式;只有在用户进行 Action 操作时,Spark 才会调度 RDD 计算任务,依次为各个 RDD 计算数据,这是 RDD 典型的惰性计算。
分布式共享内存模型对比
相比于 RDD 只能通过粗粒度的”转换”来创建(或是说写入数据),分布式共享内存(Distributed Shared Memory,DSM)是另一种分布式系统常用的分布式内存抽象模型:应用在使用分布式共享内存时可以在一个全局可见的地址空间中进行随机的读写操作。类似的系统包括了一些常见的分布式内存数据库(如 Redis、Memcached)。其最大的优点在于写一次,多机同步。集群中的所有计算机节点,在同一内存位置存储了同一份数据。弊端也很明显,一旦数据损坏,所有数据都要重新还原或重做;同步导致的延迟会很高,因为系统要保障数据的完整性,这在分布式数据库中常见。
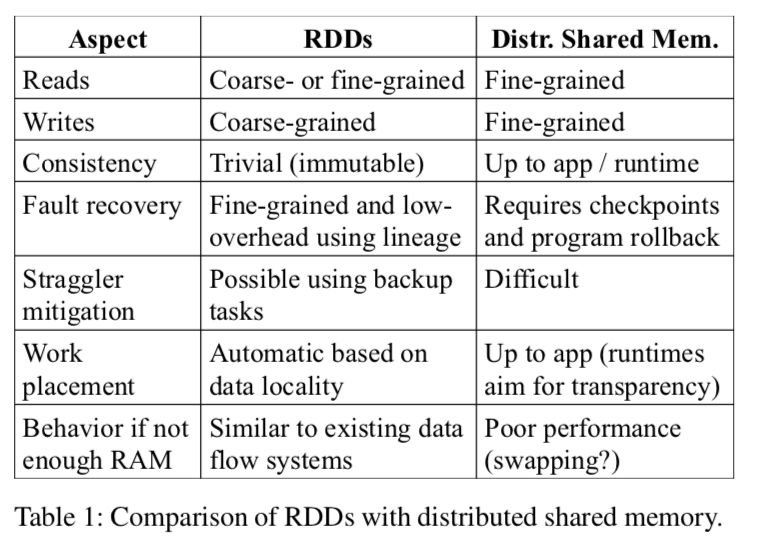
RDD 产生的方式限制了其只适用于那些只会进行批量数据写入的应用程序,但却使得 RDD 可以使用更为高效的高可用机制。RDD 与 DSM 的区别在于,前者是粗放式写入,通过转换函数生成,而后者在内存任意位置均可写入。RDD 不能很好地支持大批量随机写入,却可以很好的支持批量写入和分区容错。前面也说道,血统依赖是 RDD 容错的利器,丢失分区可重生。
RDD 的第二大优势在于,备份节点可以迅速的被唤起,去代替那些缓慢节点执行任务。即在缓慢节点执行任务的同时,备份节点同时也执行相同的任务,哪个节点快就用那个节点的结果。而 DSM 则会被备份节点干扰,引起大家同时缓慢,因为共享内存之间会同步状态,互相干扰。
RDD 还有两大优化点:基于数据存储分发任务和溢出缓存至硬盘。在大量写入的操作中,比如生成 RDD,会选择离数据最近的节点开始任务;而在只读操作中,大量数据没法存入内存时,会自动存到硬盘上而不是报错停止执行。
计算调度
前面我们提到,RDD 在物理形式上是分片的,其完整数据被分散在集群内若干机器的内存上。当用户通过 Transformation 创建出新的 RDD 后,新的 RDD 与原本的 RDD 便形成了依赖关系。根据用户所选 Transformation 操作的不同,RDD 间的依赖关系可以被分为两种:
- 窄依赖(Narrow Dependency):父 RDD 的每个分片至多被子 RDD 中的一个分片所依赖
- 宽依赖(Wide Dependency):父 RDD 中的分片可能被子 RDD 中的多个分片所依赖
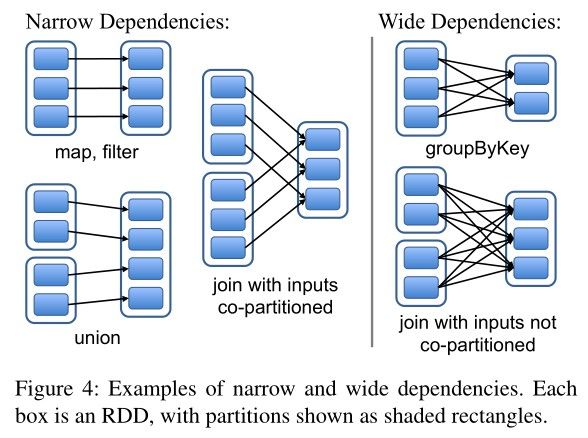
通过将窄依赖从宽依赖中区分出来,Spark 便可以针对 RDD 窄依赖进行一定的优化。首先,窄依赖使得位于该依赖链上的 RDD 计算操作可以被安排到同一个集群节点上流水线进行;其次,在节点失效需要恢复 RDD 时,Spark 只需要恢复父 RDD 中的对应分片即可,恢复父分片时还能将不同父分片的恢复任务调度到不同的节点上并发进行。
总的来说,一个 RDD 由以下几部分组成:
- 其分片集合
- 其父 RDD 集合
- 计算产生该 RDD 的方式
- 描述该 RDD 所包含数据的模式、分片方式、存储位置偏好等信息的元数据
在用户调用 Action 方法触发 RDD 计算时,Spark 会按照定义好的 RDD 依赖关系绘制出完整的 RDD 血统依赖,并根据图中各节点间依赖关系的不同对计算过程进行切分:
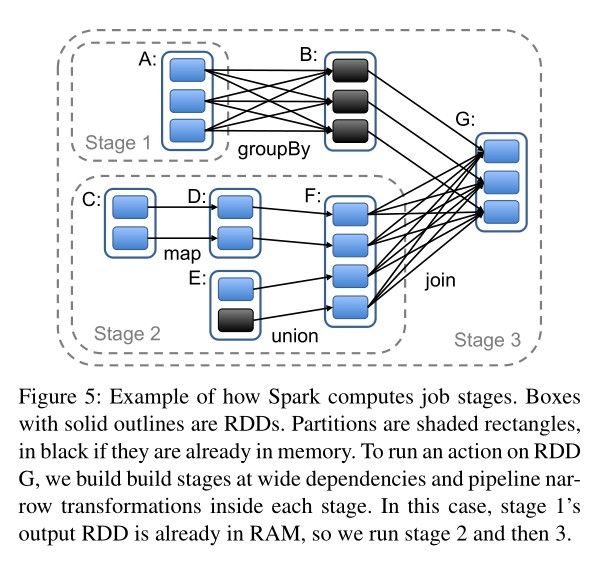
简单来说,Spark 会把尽可能多的可以流水线执行的窄依赖 Transformation 放到同一个 Job Stage 中,而 Job Stage 之间则要求集群对数据进行 Shuffle。Job Stage 划分完毕后,Spark 便会为每个 Partition 生成计算任务(Task)并调度到集群节点上运行。
在调度 Task 时,Spark 也会考虑计算该 Partition 所需的数据的位置:例如,如果 RDD 是从 HDFS 中读出数据,那么 Partition 的计算就会尽可能被分配到持有对应 HDFS Block 的节点上;或者,如果 Spark 已经将父 RDD 持有在内存中,子 Partition 的计算也会被尽可能分配到持有对应父 Partition 的节点上。对于不同 Job Stage 之间的 Data Shuffle,目前 Spark 采取与 MapReduce 相同的策略,会把中间结果持久化到节点的本地存储中,以简化失效恢复的过程。
当 Task 所在的节点失效时,只要该 Task 所属 Job Stage 的父 Job Stage 数据仍可用,Spark 只要将该 Task 调度到另一个节点上重新运行即可。如果父 Job Stage 的数据也已经不可用了,那么 Spark 就会重新提交一个计算父 Job Stage 数据的 Task,以完成恢复。有趣的是,从论文来看,Spark 当时还没有考虑调度模块本身的高可用,不过调度模块持有的状态只有 RDD 的血统图和 Task 分配情况,通过状态备份的方式实现高可用也是十分直观的。
内存管理
Spark 为 RDD 提供了三种存储格式:
- 内存中反序列化的 Java 对象;
- 内存中序列化的 Java 对象;
- 硬盘存储
访问速度从快到慢,即第一种方式最快,无需任何转换就可以被自由访问。最后一种最慢,因每次使用,需从硬盘抽取数据,有不必要的 IO 开销。
当内存吃紧,新建的 RDD 分区没有足够内存存储时,Spark 会采用回收分区方式,以给新分区提供空间。回收机制采用的是常规 LRU(Least Recently Used)算法,即最近最少使用的算法。这套回收机制很有用,至少目前来说是。但权值机制也很有用,比如设定 RDD 的权限等级,控制 RDD 分区被回收的可能性。
容错
前面已经提到,Spark 可以利用血统依赖来恢复出现故障的 RDD,这样即可不用对中间结果做持久化。然而,在部分长链场景下,做 checkpoint 来持久化也是有必要的。这是因为如果血统依赖足够长,在故障之后,RDD 的恢复需要经历相当多的步骤,会导致时间过多的消耗,此时如果有 checkpoint 即可减少较多的时间消耗。
Spark 将 checkpoint 的决策留给了用户。实现 checkpoint 的 API 是 persist 的 replicate 开关,即:1
rdd.persist(REPLICATE)
通过定期将数据暂存至稳定的存储设备,可以保证在性能不大幅度下降的情况下优化 RDD 失效后的过长重算。
评测
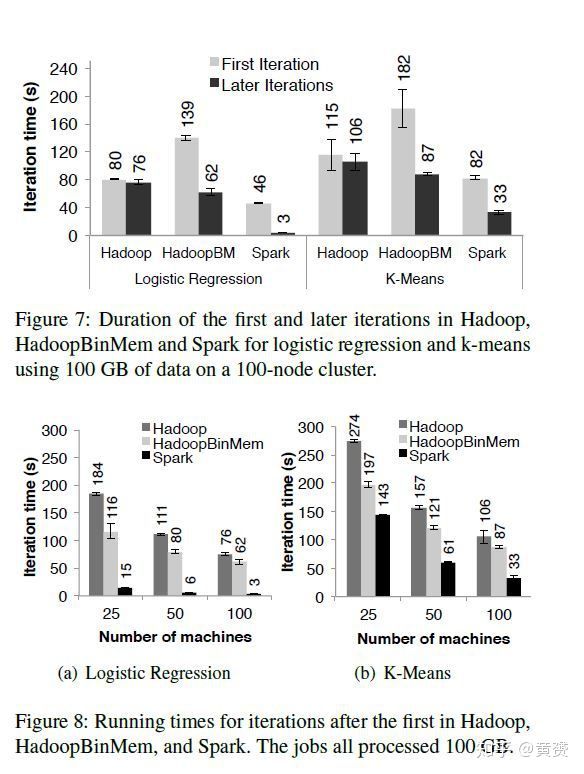
Spark 在性能方面表现出众,对标物是 Hadoop,以下是基于 Amazon EC2 做出的 4 组对比数据:
- 在图运算和迭代机器学习方面,优先 Hadoop 20 倍速度。性能的提高得益于无需硬盘 I/O,且在内存中的 Java 对象计算,没有序列化和反序列化的开销。
- 性能与扩展性都很好。单测一张分析报表,就比 Hadoop 提高了 40 倍性能
- 当有节点故障时,Spark 能自动恢复已丢失的分区
- 查询 1TB 的数据,延迟仅在 5-7 秒。
总结
总的来说,Spark RDD 的亮点在于如下两点:
- 通过对分布式集群的内存资源进行抽象,允许程序高效复用已有的中间结果且保证高可用性。
- 提供比 MapReduce 更灵活的编程模型,兼容更多的高级算法。
比起类似于分布式内存数据库的那种分布式共享内存模型,Spark RDD 巧妙地利用了其不可变和血统依赖的特性实现了对分布式内存资源的抽象,很好地支持了批处理程序的使用场景,同时大大简化了节点失效后的数据恢复过程。
同时,我们也应该意识到,Spark 是对 MapReduce 的一种补充而不是替代:将那些能够已有的能够很好契合 MapReduce 模型的计算作业迁移到 Spark 上不会收获太多的好处(例如普通的 ETL 作业)。