Twitter 内存缓存系统分析论文阅读
背景
基于一个物理现实:内存操作比磁盘操作快若干个数量级。现代网站服务广泛使用了类似 redis ,memcached 的内存缓存系统。其思想很简单:尽管海量数据最终都需要落盘持久化,但如果能够将一些常用的数据在内存中缓存以供读请求直接获取,则不仅能够降低请求时延,还能够提升系统吞吐量,而且也能够减少底层数据管理系统比如关系型数据库的负载。
内存缓存系统的大规模商用激发了业界对其的研究,现有的研究主要集中在如何提高吞吐量,如何减少缓存缺失率等等。由于用户场景与缓存系统的性能息息相关,之前也出现了生产系统的分析,但其针对的用户场景过少。这就导致了理论和生产环境之间的一个巨大 gap,因此业界需要一个能够包含大量用户场景的内存缓存系统分析;此外,业界对内存缓存系统的前提假设都是写少读多,而且许多理论比如内存管理都是基于数据大小是恒定这一假设来做的,那么实际上线的生产环境也都是理论假设的这样吗?此外,一些看似不重要的特性,比如 TTL 受到了业界极少的关注,那么它对于生产系统的性能影响真的很小吗?带着这些问题,我们开始介绍这篇论文。
数据
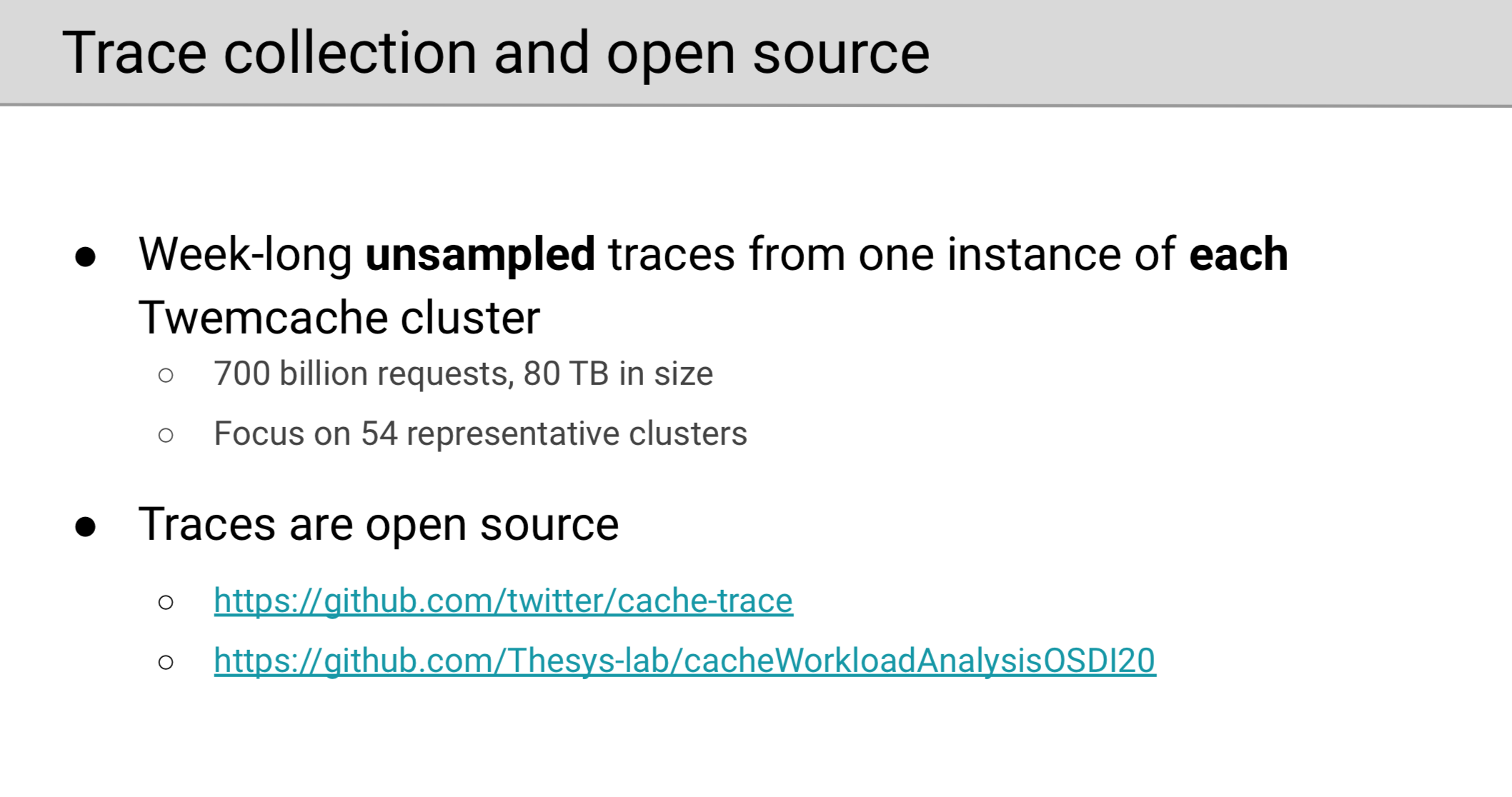
首先介绍数据情况,Twitter 内部的内存缓存集群都是单租户单层的容器化实例,这样的架构方便作者直接将集群的分析结果与商业逻辑对应,更能够反映现象的真实原因。可以看到,Twitter 的内存缓存集群很大。

为了保证分析不受采样方法的影响,作者未取样的收集了两段区间为一周的集群请求全量元信息,在 80TB 的数据基础上做了详细的分析。而且,作者也将数据适度脱敏后进行了开源,能够让任何人去继续分析。
缓存场景
Twitter 内部的内存缓存系统主要有三种应用场景:
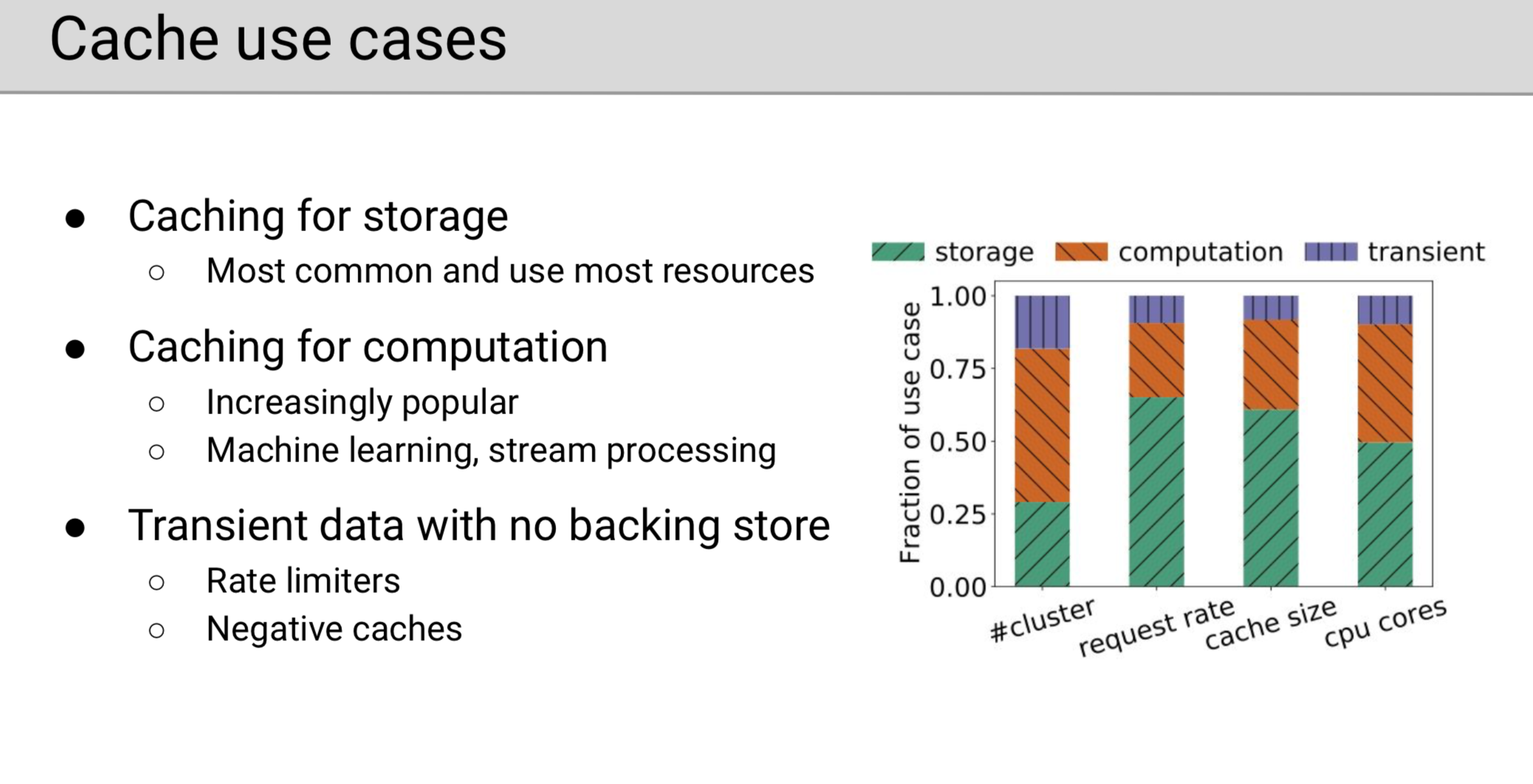
存储缓存
将一些在磁盘上的热点数据缓存在内存中,来减少底层涉及磁盘的数据系统比如关系型数据库的压力。
计算缓存
缓存一些计算结果或预结算结果。随着 BI 时代的到来,许多公司都会利用机器学习的方法做用户画像或者是实时流推荐。这些算法的每次计算很难在秒级以下,而且用户的画像也一般不会在几小时内发生变化,因此企业一般会每计算一次用户的画像就将其设置一个几分钟或几小时的 TTL 存储到缓存中,这样既能够大幅度减少计算资源的消耗也能够保持 BI 逻辑,这种使用方式正在逐渐流行。
瞬态数据缓存
有一些数据是不需要持久化的,只存在于内存缓存中。比如限速场景会把用户的请求存储到缓存中进行统计,一旦超速即开始限速,过期后隐形删除这些统计日志即可。
数据分析
写多读少场景广泛存在
如下图所示,这是一个有关写请求占总请求比率的集群比例概率分布图。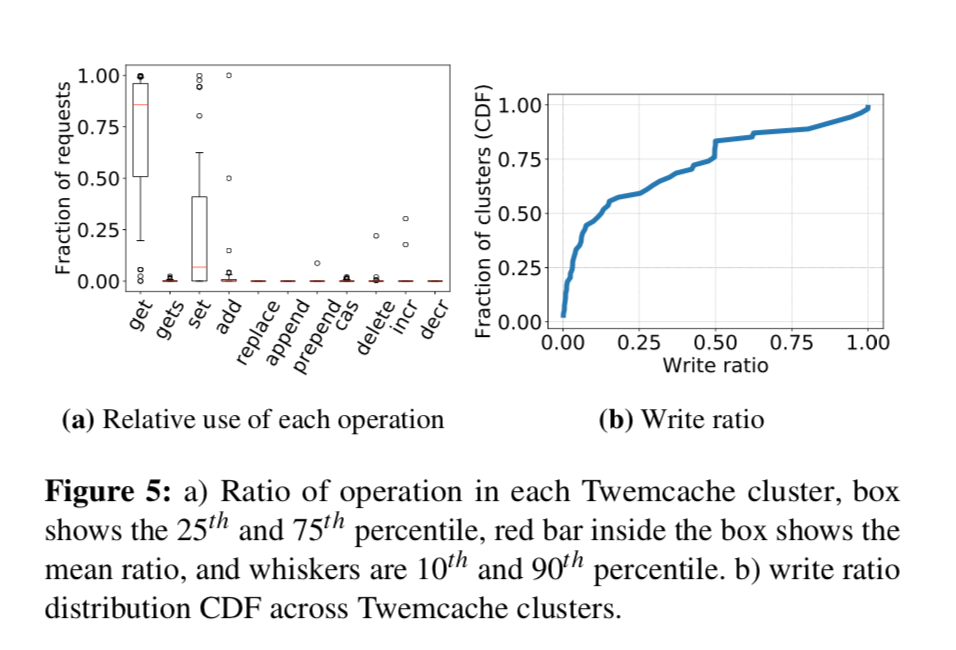
作者将比率大于 30% 的集群定义为写多读少负载,可以看到 twitter 内部至少 35 % 的集群都是写多读少的负载,这打破了业界对于内存缓存系统的前提假设,也展示了生产和理论之间的 gap。对于写多读少场景,长尾效应,扩展性受限都成了问题,而这一块却几乎没有学者研究过,因此作者为业界指明了一条研究方向:即写多读少场景内存缓存系统的优化。
对象大小
下图是集群中有关对象大小的若干集群比例概率分布图。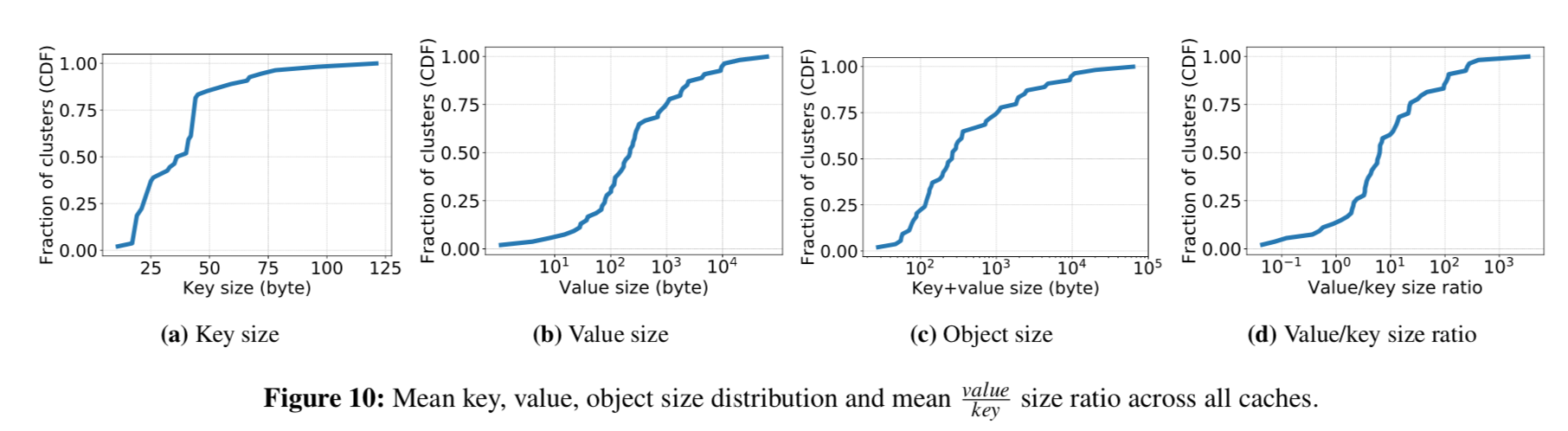
元数据大小
从前三张子图中可以看到,大部分对象数据都很小,那相比之下,原本被忽视的元数据消耗就非常大了,比如 memcached 中每个对象的元数据就有 56 字节。现有的研究大多数都是通过增加元数据来提高缓存命中率的。而实际上对于小对象场景来说,最小化元数据的大小能够增大缓存个数,也是一条提升性能的方向。
key 大小
在上图的第四张子图中可以观察到,对于 60 % 的 workload,key 和 value 的大小都在一个数量级,这很让人惊异。在观察了许多实际 key 后,作者发现很多业务使用了较为冗长的 key,比如把很长的多段命名空间都扔到了里面,这浪费了许多空间。由于直接让业务团队将 key 改小是不可行的,所以内存缓存系统也可以为 key 增加一个轻量级的压缩,这样也能够有效的增大缓存空间。这个工作实现起来很容易,但之前没有人观察到过这个现象,因此这也是作者的贡献。
对象大小的动态分布
当前,内存缓存系统大多假设对象随着时间的推移大小不变,然而在生产系统中,作者观察到大部分时间中,其对象大小的分布并不是恒定的。
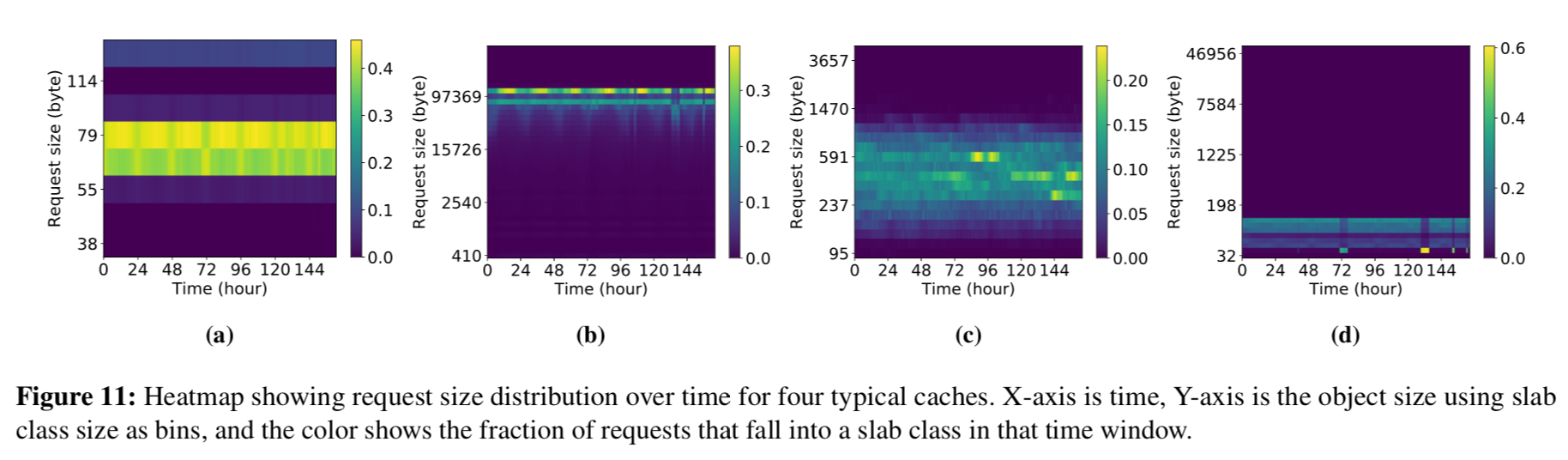
这个不恒定主要有两种表现形式:
第一种是周期性的变化,比如很多负载都具有白天对象更大的特征。如图所示,亮度发生变化代表分布发生了变化,很多亮度是有周期出现的。
第二种是临时的突变,过后即恢复。如图所示,存在个别无规律的亮点。
这些突变给缓存系统的内存管理带来了很多挑战,就如同操作系统的内部碎片和外部碎片一样。作者实际测试发现,现有缓存系统的主流内存管理技术 slab-class ,在面对可变对象大小时表现十分受限,作者认为内存管理技术方面需要更大的创新,比如随着机器学习的发展,动态的预测缓存行为并做出智能的内存管理就是一个可行的方向。
TTL
TTL,一个限定对象生命周期的内存缓存系统特有参数,作者进行了细致的分析。对应前面提到内存缓存的三种场景,TTL 都有作用。
TTL 使用场景
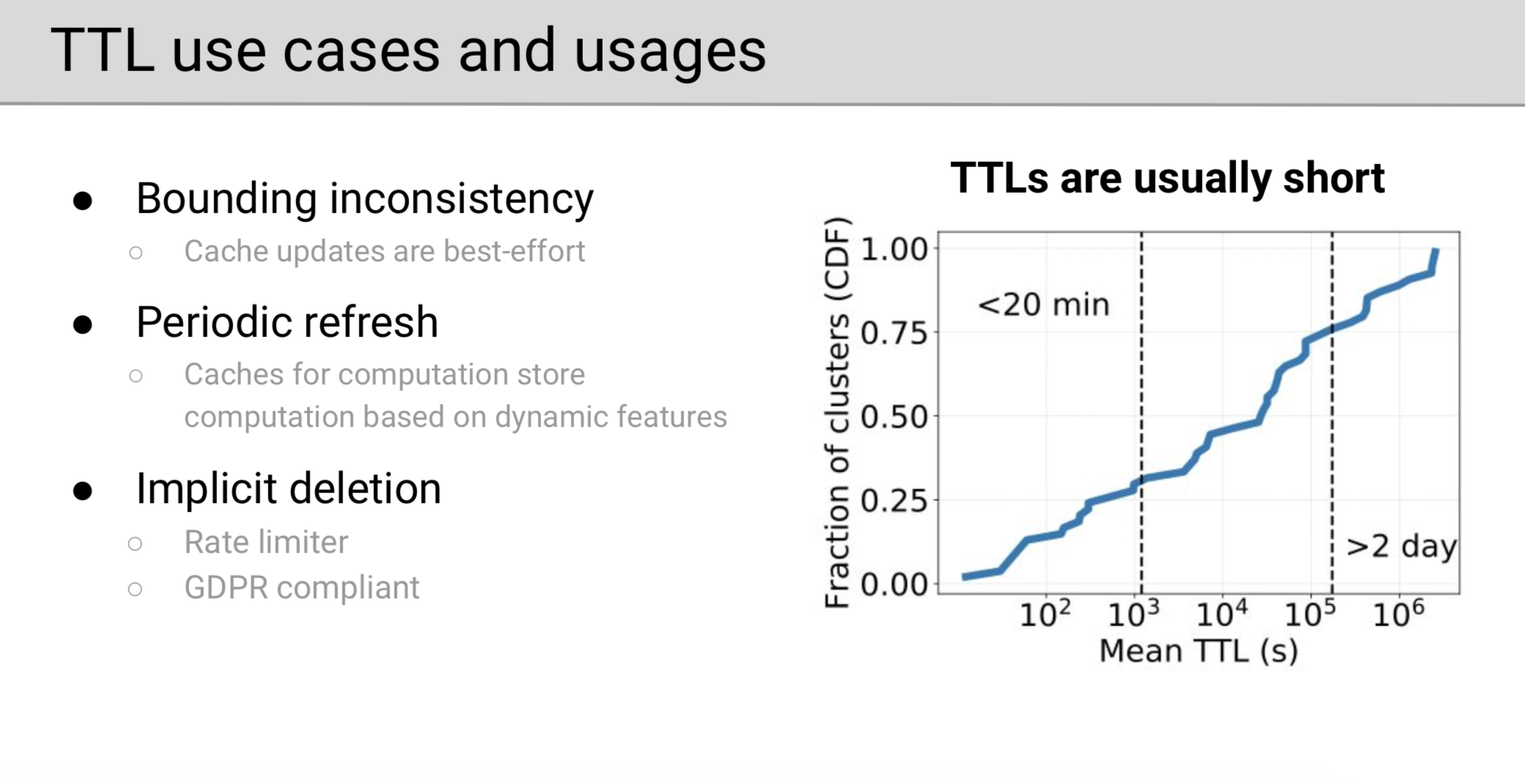
- 保证不一致上界:部分对一致性要求较低的业务可能在写缓存失败时并不重试,这可能最终导致缓存与实际数据的不一致,因此用户可以使用 TTL 这个属性给这个最终一致性的区间定一个上界,从而达到性能和不一致上限都得到保证的可控结果。
- 定期更新:用户画像随着时间推移可能逐渐变得不准确,不实时,因此需要一个 TTL 属性来隐性指示计算,即哪怕新一轮计算结果还没触发,每过 TTL 时间请求用户的画像就得重新计算一次,这其实是一个实时性和计算资源之间的 trade-off。
- 隐形删除:比如限速场景可以把用户每条请求数据的 TTL 设置为限速的时间窗口,这样既能够达到限速的目的又能够在一段时间后隐形删除掉这些数据。
小 TTL 能够限制工作集合的大小
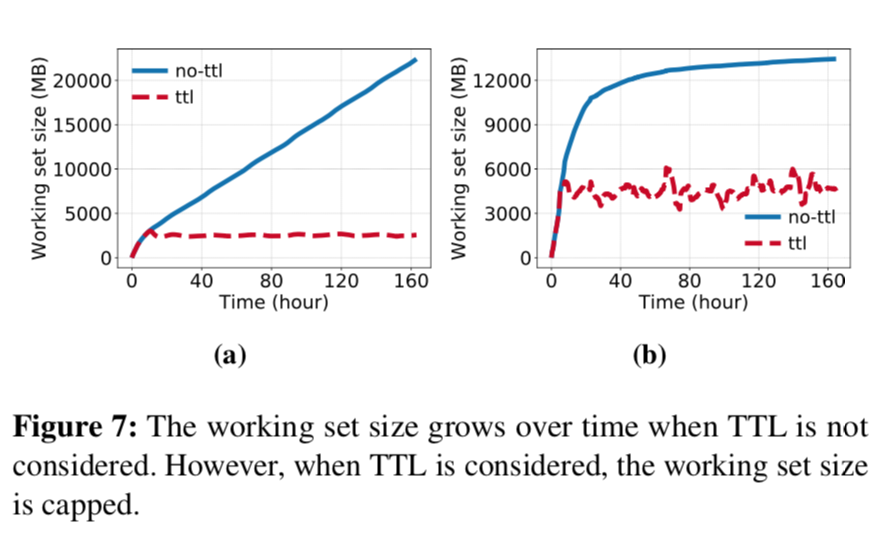
如图所示,作者统计了在有无 TTL 场景下的对象集合总大小和活跃对象集合大小,可以看到活跃的对象集合大小相比总大小始终在一个固定范围内。因此如果能够对过期数据清理得当,那么实际上不需要很大的缓存资源就能提供一个不错的缓存命中率。因此作者得出了结论,有效的主动过期策略比驱逐还要更重要。
现有的主动驱逐策略主要有两种:一种是 Facebook 提出的环形缓冲区策略,它在 TTL 个数较少或者多但不连续时表现都不好;另一种是当前 redis 的定期删除策略,由于其是遍历实现的,而为了保证及时删除扫表时间至少要和最小的 ttl 在一个量级 ,则对于较大的 ttl,其数据会被扫描多次。这样也一定程度上造成了 cpu 时间的浪费,而且也容易有缓存雪崩问题。因此作者认为有效的主动过期策略也需要进一步的创新。
更多发现
生产数据统计
请求激增不一定就是热点导致的,可能就是均匀的涨了一些。
对象分布
尽管有些许偏差,但针对对象的请求基本符合幂率分布
驱逐策略
尽管不同负载的表现情况不一样,但 FIFO 与 LRU 策略在大部分负载下的表现近似。这也预示业务可能实际没必要费事费力的去搞 LRU 策略,简单的 FIFO 就能达到类似的性能的。
总结
- 证明了写多读少内存缓存场景的广泛存在,指明了一个可以研究的领域。
- 大多数场景的对象很小,要想提升吞吐量可以从减少元数据大小和适度压缩 key 入手。
- 在内存缓存的生产系统中,对象的大小并不是恒定不变的。基于对象大小固定不变进行的理论推理都存在问题。
- 有效的主动过期策略比驱逐策略更管用。
评价
本文作者基于世界上最大的实时内容公司之一 Twitter 的内存缓存统计数据,使用强有力的数据分析纠正了若干业界对于内存缓存的误区,辩驳了若干业界的前提假设和主流思想,并提出了若干研究方向,开创了多个子领域。我个人认为这是一篇很有意义的文章。