Facebook 的 Memcached 系统扩展论文阅读
背景
本篇论文由 Facebook 2013 年在 NSDI 上发表,其系统地介绍了 Facebook 公司内部对于大规模缓存系统的使用实践。
这篇论文没有太多新的想法,但却传达了一个很重要的理念:不同的场景有不同的系统需求。在成本有限的情况下,并不一定线性一致性就是最好的,对于有些场景,最终一致性带来的收益远超我们的想像。
对于大部分 2C 应用,随着用户数量的逐渐增加,其后台数据存储系统大致是如此的进化路线:
- 单机 Web 服务器 + 单机数据库(MySQL / Oracle): 随着负载增加,单机 Web 服务器逐渐占满了 CPU,需要横向扩展。
- 多台无状态 Web 服务器 + 共享的单机数据库(MySQL / Oracle):无状态的 Web 服务器可以横向扩展以获得更高的吞吐量。随着负载进一步增加,单机数据库成为了瓶颈。
- 多台无状态 Web 服务器 + 关系数据库集群(分库分表 / NewSQL 数据库): 横向扩展了关系数据库的性能,这里可以参考分库分表或者一些 NewSQL 产品。对于前者,跨分区的事务会是一个痛点。此外,这类应用的业务场景一般情况下都是读多写少的场景。对于写性能,只能通过横向扩展数据库的方式来解决。对于读性能,除了横向扩展数据库,还可以加一层缓存层以提升系统的吞吐量,同时也减少数据库的负载。
- 多台无状态 Web 服务器 + 用于读加速的分布式缓存系统(Redis / Memcached) + 关系数据库集群(分库分表 / NewSQL 数据库):此时对于读写性能基本都能够扩展,关系数据库中的数据也可以通过 CDC 同步到下游去做离线或近实时计算。此时需要进一步关注的便是缓存系统的一致性。
脸书在 2013 年就已经进化到了第四个阶段,以下会简单介绍其架构:
架构
Facebook 的架构包括多个 web、memcached 和数据库服务器。一组 web 和 memcached 服务器组成一个前端集群,多个前端集群组成一个数据中心。这些数据中心在论文中称为 region 。一个 regions 内的前端集群共享同一个存储集群。Facebook 在全球不同地区复制集群,将一个 region 指定为主 region,将其他 region 指定为次要 region。
其架构图如下:
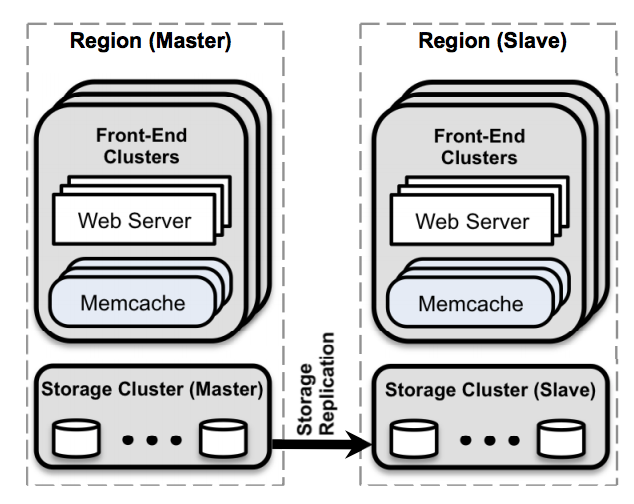
对于脸书的场景,其数据一般都是用户信息,好友信息,帖子信息,喜欢信息,照片信息等等。这些消息主要有两个特点:
- 用户能够容忍适度的旧数据,但不能容忍非常旧的数据。
- 用户想要能够读自己所写。
基于以上特点,Facebook 使用了 memcached 来减少其数据库的读取负载。Facebook 的工作负载以读取为主,而 memcached 可防止它们为每个请求访问数据库。他们使用 memcached 作为后备缓存。这意味着当 Web 服务器需要数据时,它首先尝试从缓存中获取数据。如果该值不在缓存中,Web 服务器将从数据库中获取数据,然后用数据填充缓存。
对于写入,Web 服务器会将键的新值发送到数据库,然后向缓存发送另一个请求以删除键。对该键的后续读取将从数据库中获取最新数据。
流程如下图所示: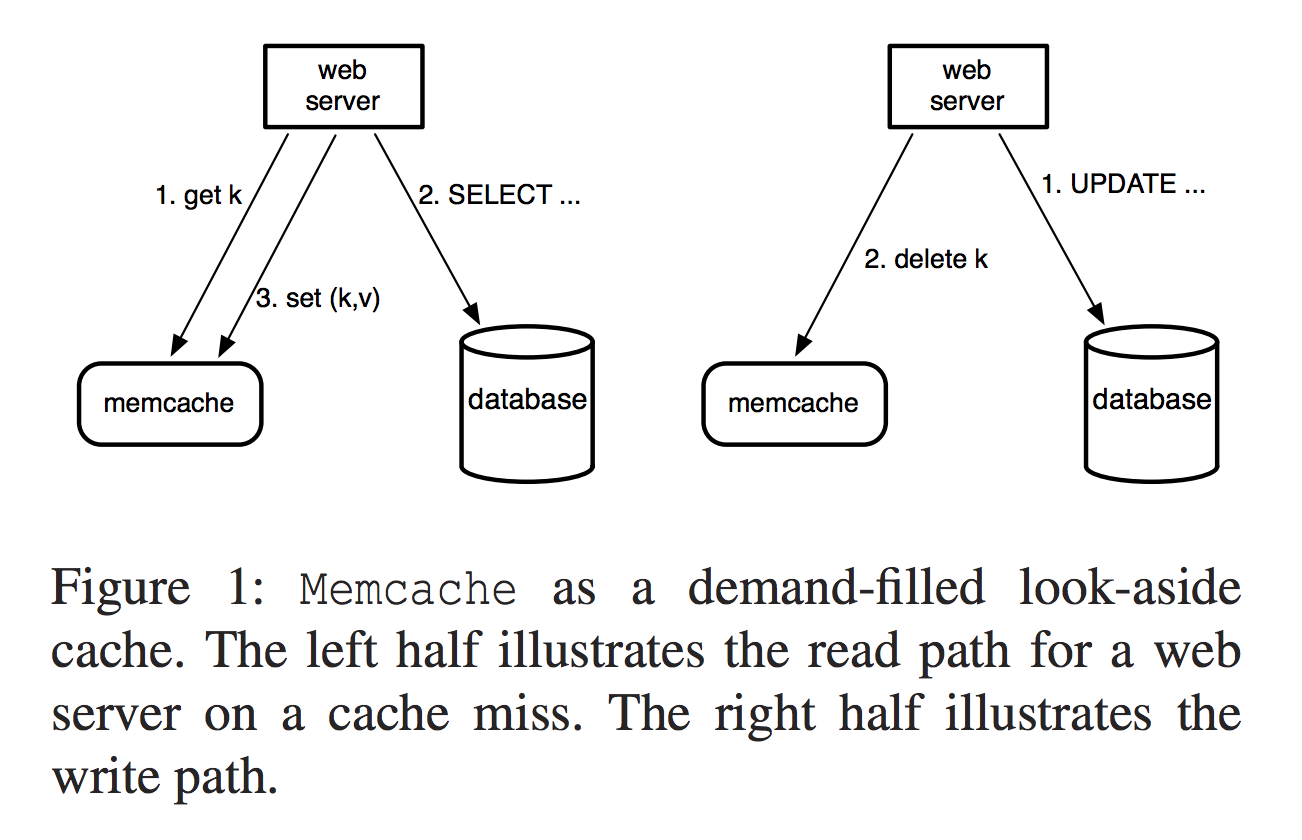
至于为什么在写数据库成功时要删除缓存系统中的 key 而不是 set 进去当前写入成功 key 的 value,大致原因是为了降低并发写入时出现 stale read 的概率,从而进一步满足用户读自己所写的需求。
需要注意的是,即使使用了 delete 的方案,还是不能完全避免 stale read 的可能性。归根原因,是因为在 db 处的更新和在 cache 处的更新很难保证原子性,我们只能尽量减少其不一致的概率而很难完全避免它。因此,对于每个 key 都设置合理的 TTL 时间和缓存过期策略也十分重要,这其实相当于给系统不一致的阈值定了一个上限,从而保证了最终一致性。这一点本论文没有介绍,但 Twitter 的内存缓存系统有介绍,可以参考本人另一篇 阅读博客。
对于如何保证数据库和缓存的一致性,该 博客 有一些有趣的思考。
对于缓存穿透,缓存击穿,缓存雪崩,可以简单看看 八股文。
此外,缓存系统一般由两种并行处理策略:
- 分片
- 节省内存:每个 key 一个副本。
- 可横向扩展:流量均匀时能够均匀的利用所有节点的资源。
- 更多的长连接:客户端节点需要与很多节点建立连接。
- 复制
- 浪费内存:每个 key 多个副本。
- 对 Hot Key 友好:分片对 Hot Key 无帮助,而复制可以提升 Hot Key 的吞吐量。
- 更少的长连接:一个节点上可能有多个分片的副本。
根据情况可以做取舍,一般分片和复制都是需要做的。
对于 Facebook,其存在两个全量异步复制的 region ,这一定程度上保证了跨 region 的容错,同时也减少了不同地域用户的读延迟。
在每个 region 内部,其首先将数据库在数据库层做了分片以支持高性能的横向扩展,接着其利用多个缓存集群缓存了相同的 Hot Key 来共享负载,同时其也单独将不那么 hot 的 key 放到一个默认缓存集群中以减少缓存成本。
对于工业界系统,Facebook 还仔细设计了网络协议(UDP 读,TCP 写),流量控制,网络布局,缓存集群冷启动,缓存节点宕机等实际情况。感兴趣的可以关注其论文,此处不再赘述。
总结
简单介绍了 Facebook 使用 Memcached 的实践。