Talent-Plan:用 Rust 实现 Percolator 算法
版本
前期准备
Rust 学习
Percolator 学习
过关思路
在基本环境搭建好之后,观察发现 lab 只有 13 个测试,测试全部 AC 即可通过项目。实际上一个生产级别的 Percolator 实现这些测试是远远不够的,需要考虑和测试的 case 很多。
由于本 lab 的主要目标是帮助学习 Rust,因此本次过关思路便是通过 TDD 的方式通关,将主要精力放在通过测试以及对应 Rust 语法的学习和练习上,对于实现的 Percolator 算法满足论文要求和当前的测试 case 即可,不再去新增更多的 test case 和并发情况。

过关过程
TSO 测试
- test_get_timestamp_under_unreliable_network
该测试期望在不稳定网络下 client 的 get_timestamp 接口在超时重试时可以满足 backoff 幂增重试属性。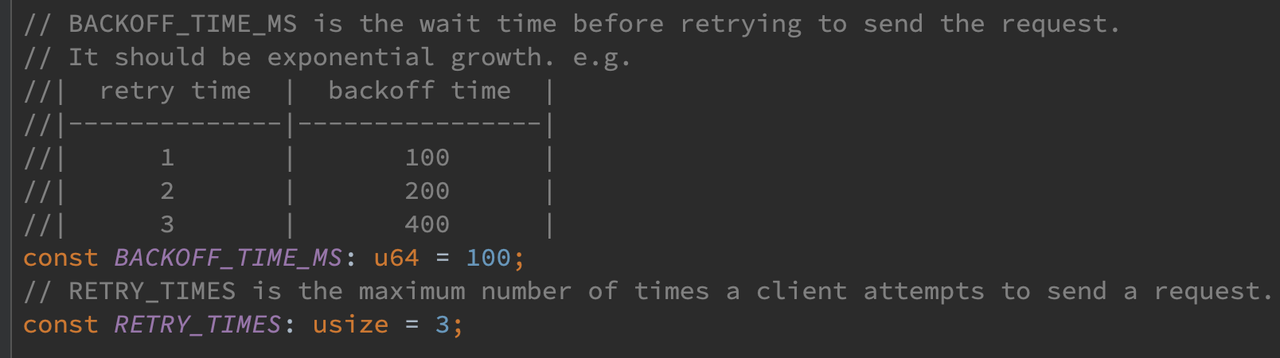
因此一方面在 TSO Server 端的 get_timestamp 接口处提供一个空实现,另一方面在 Client 中维护对应初始化时传入的 rpc client 字段并在 get_timestamp 函数中增加幂增 sleep 逻辑即可。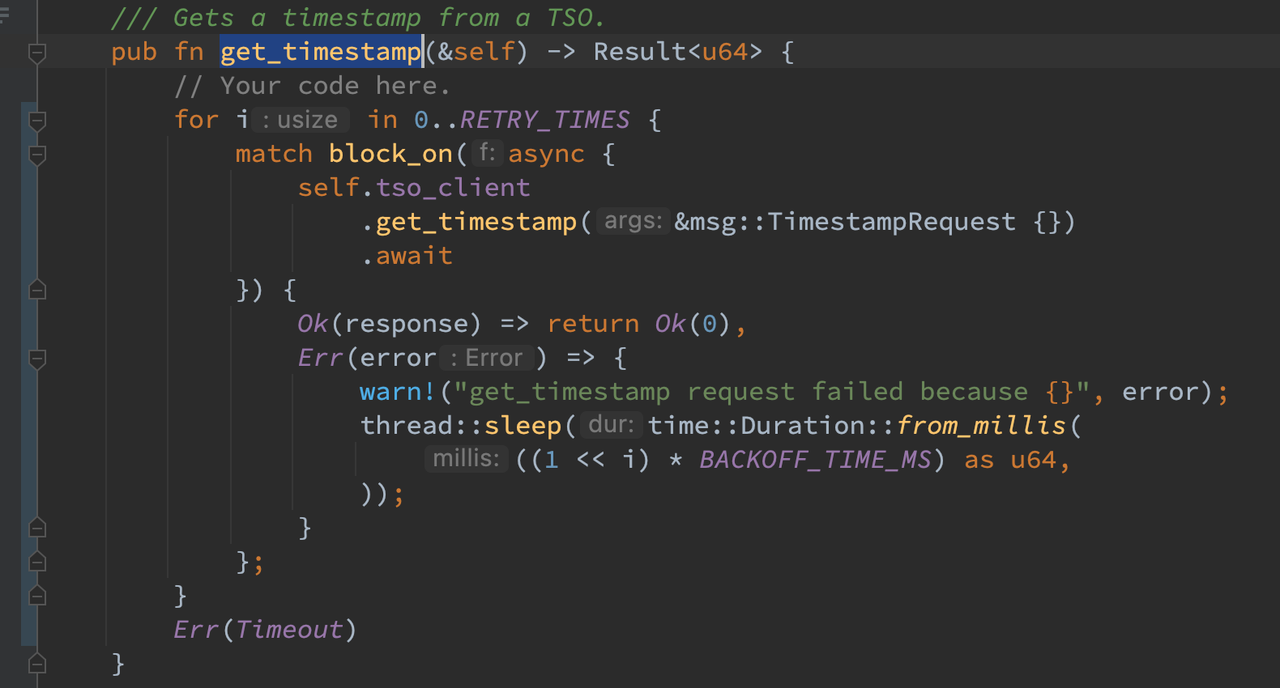
有关 async 和 await 的原理需要进一步理解学习,但仅就完成本 lab 而言,可以查看 labrpc example 中的使用样例来模仿使用,即使用 await 来驱动 async 的代码块执行,使用 block_on 达到同步执行的效果。
通过本测试的新增代码可查看 commit
TXN 正常测试
- test_predicate_many_preceders_read_predicates
- test_predicate_many_preceders_write_predicates
- test_lost_update
- test_read_skew_read_only
- test_read_skew_predicate_dependencies
- test_read_skew_write_predicate
- test_write_skew
- test_anti_dependency_cycles
以上测试要求在网络正常的情况下能够正确实现 Percolator 的事务提交,即可按照论文中的伪码实现即可。
client
对于 Client 的 new 函数,保存两个 rpc client 并初始化 start_ts 和 mem_buffer。注意,为了在客户端进行去重,mem_buffer 使用了 hashmap 而不是 Vec。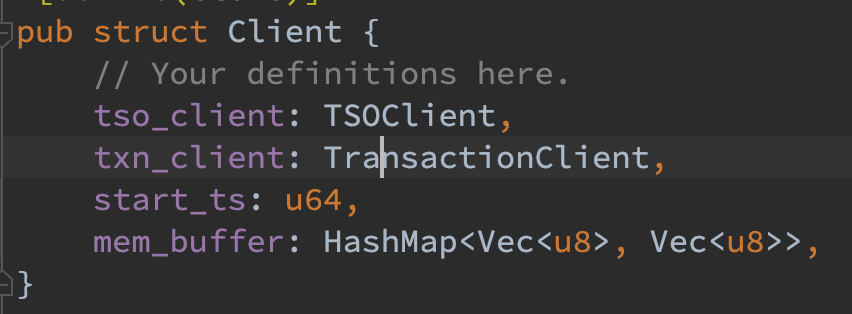
对于 Client 的 get_timestamp 函数,参照上一小节实现发 RPC 和对应的重试以及错误处理逻辑即可。
对于 Client 的 begin 函数,使用 get_timestamp 函数更新本地的 start_ts 即可,start_ts 将作为快照读取的依据。
对于 Client 的 set 函数,直接缓存到 mem_buffer 中即可。
对于 Client 的 commit 函数,开始 Percolator 的提交流程,即先 prewrite 再 commit。注意不论是 prewrite 还是 commit 都是先对 primary 进行处理再对 secondary 处理。
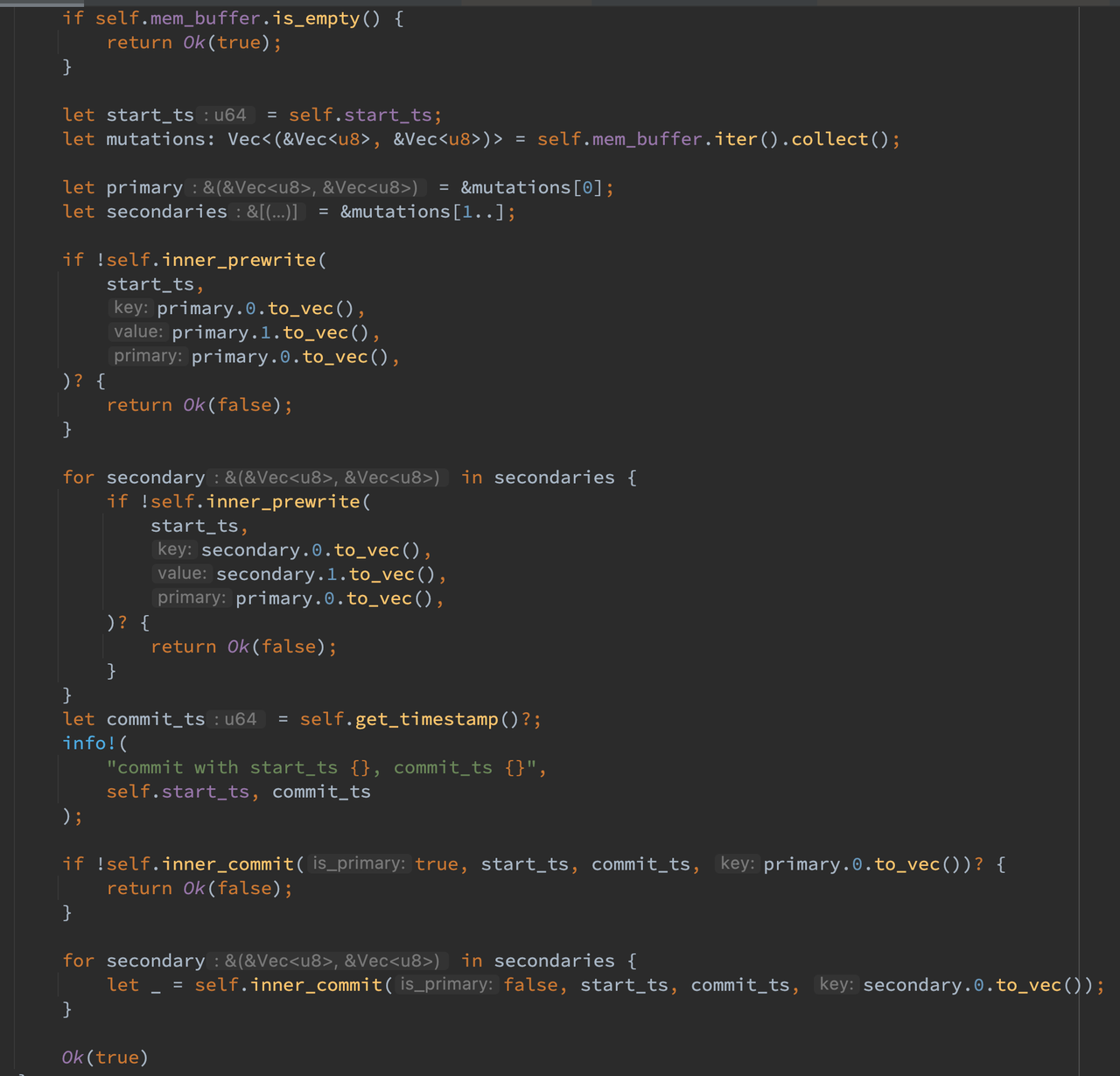
proto
参照论文写出了对应的 proto 文件如下,以下将分别分析四种 RPC 请求:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36message TimestampRequest {}
message TimestampResponse {
uint64 timestamp = 1;
}
message GetRequest {
bytes key = 1;
uint64 start_ts = 2;
}
message GetResponse {
bytes value = 1;
}
message PrewriteRequest {
uint64 start_ts = 1;
bytes primary = 2;
bytes key = 3;
bytes value = 4;
}
message PrewriteResponse {
bool success = 1;
}
message CommitRequest {
bool is_primary = 1;
uint64 start_ts = 2;
uint64 commit_ts = 3;
bytes key = 4;
}
message CommitResponse {
bool success = 1;
}
get_timestamp
对于 TSO 请求,此时需要使用一个全局唯一 ID 的递增生成器而不能硬编码成 0 了。最暴力的方法便是采用 wall clock time 来生成,然而在高并发情况下 wall clock time 可能产生重复的 ID,因此一般需要 HLC 结合物理时间戳和逻辑时间戳的方式来保证全局唯一。出于时间原因,我直接采用了逻辑递增 ID 的方式来生成全局唯一的递增 ID。为了性能考虑,我采用了 Arc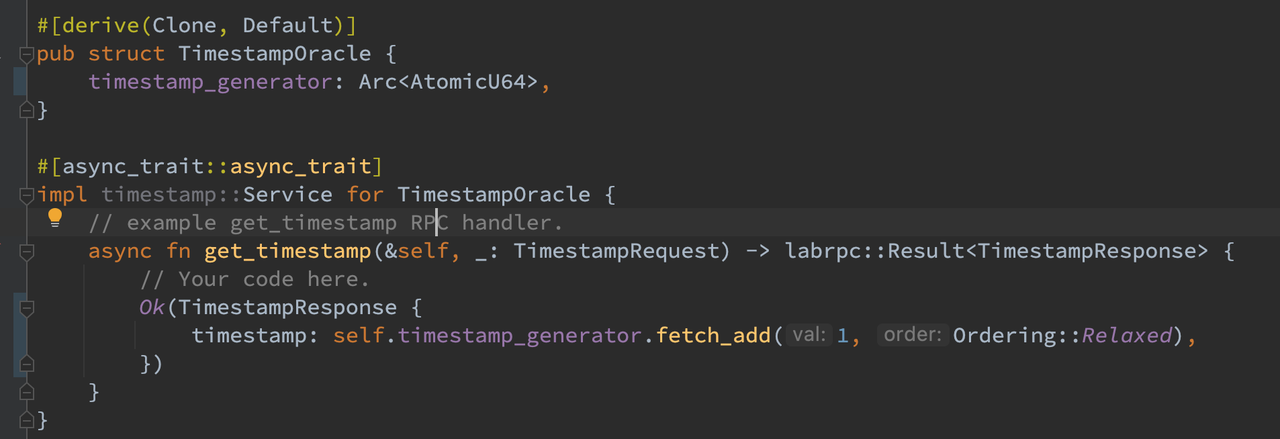
get
对于 Get 请求,需要携带 key 和对应的 start_ts 来针对某一全局快照读取。因此客户端构建好 request 后向服务端发送即可,注意此时依然实现了超时重试的逻辑。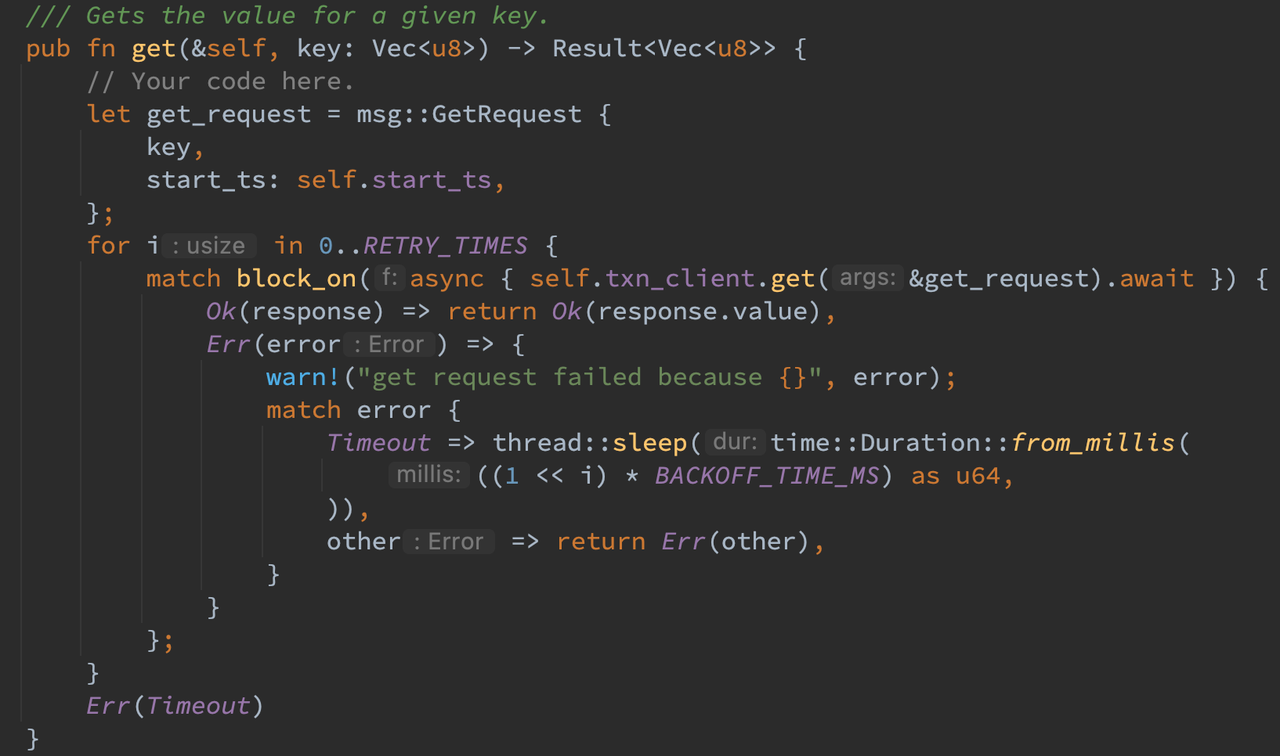
在服务端的 RPC handler 里,首先使用 lock 进入临界区,接着判断 lock 列中是否存在与本事务冲突的其他事务,如果存在则 backoff 等待并在稍后重试。接着查找 write 列中该 key 最接近当前事务 start_ts 的 commit_ts,如果不存在则返回空字符串,否则获取到其 start_ts 将其从 data 列读出来即可。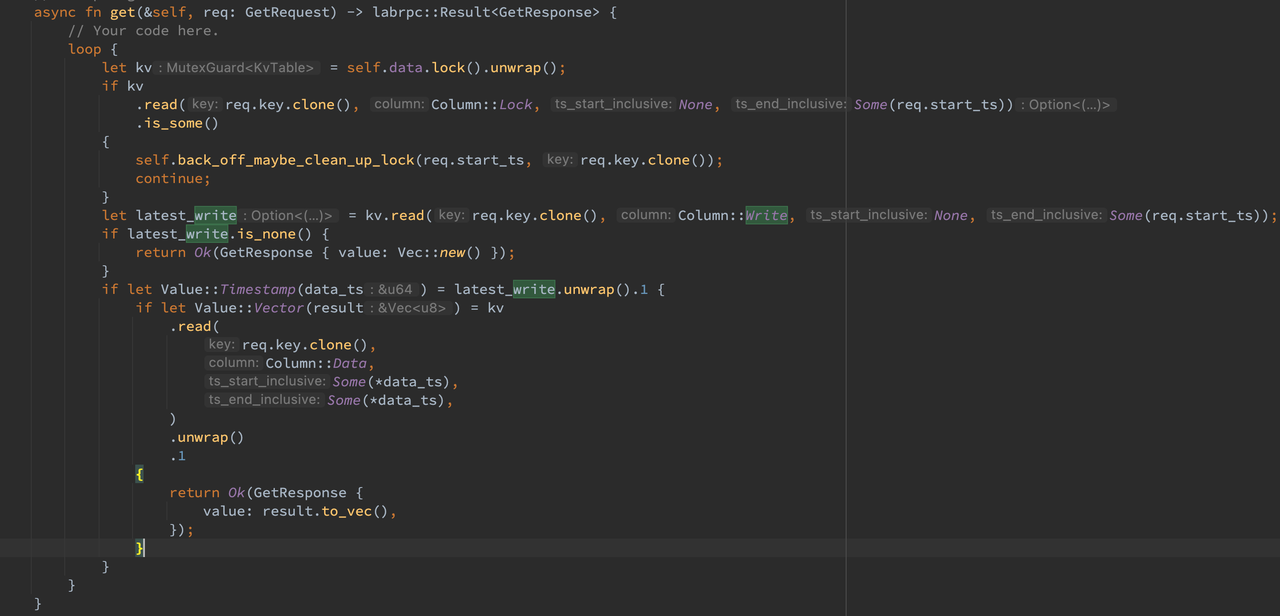
在 KVTable 的 read 函数中,使用 BTreeMap 的 range 接口和 last 接口来获取某个区间的最大值,如果不存在则返回 None。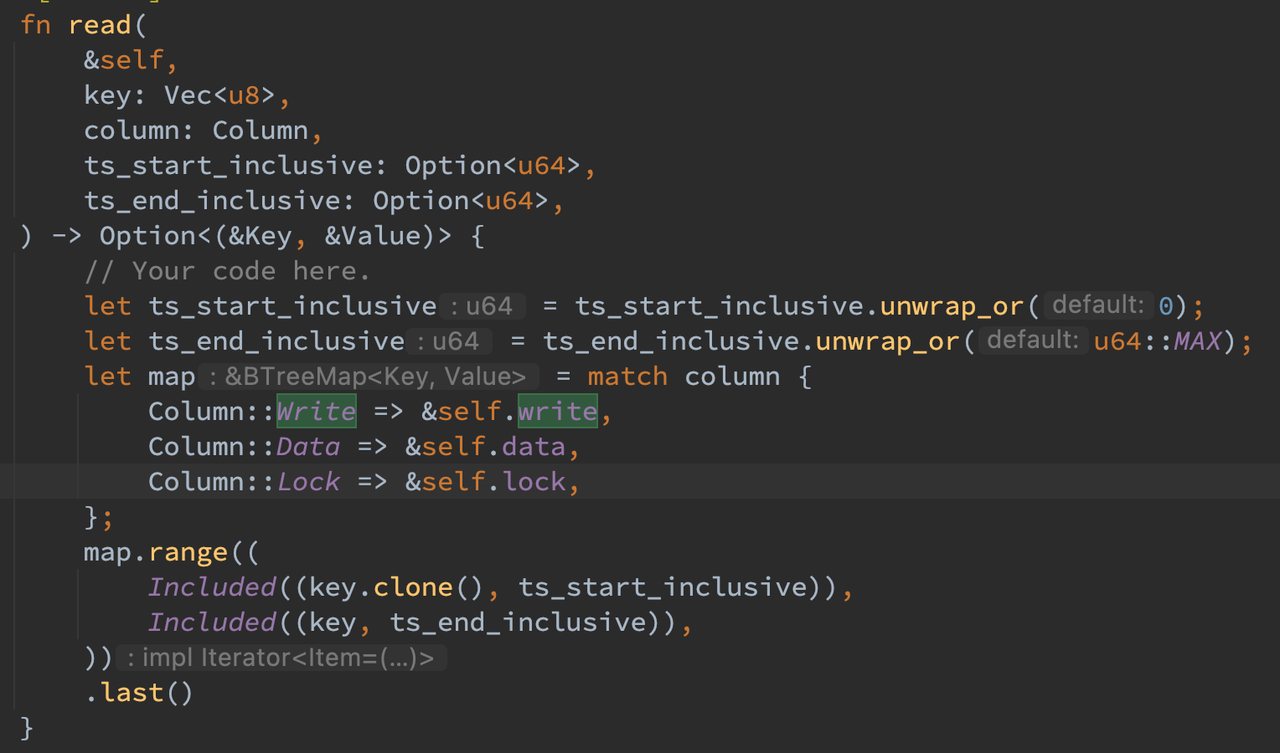
prewrite
对于 PreWrite 请求,需要携带 start_ts,primary 和对应的 KV 对来进行写入。客户端添加了对应的重试和错误处理逻辑,并将参数发送给服务端。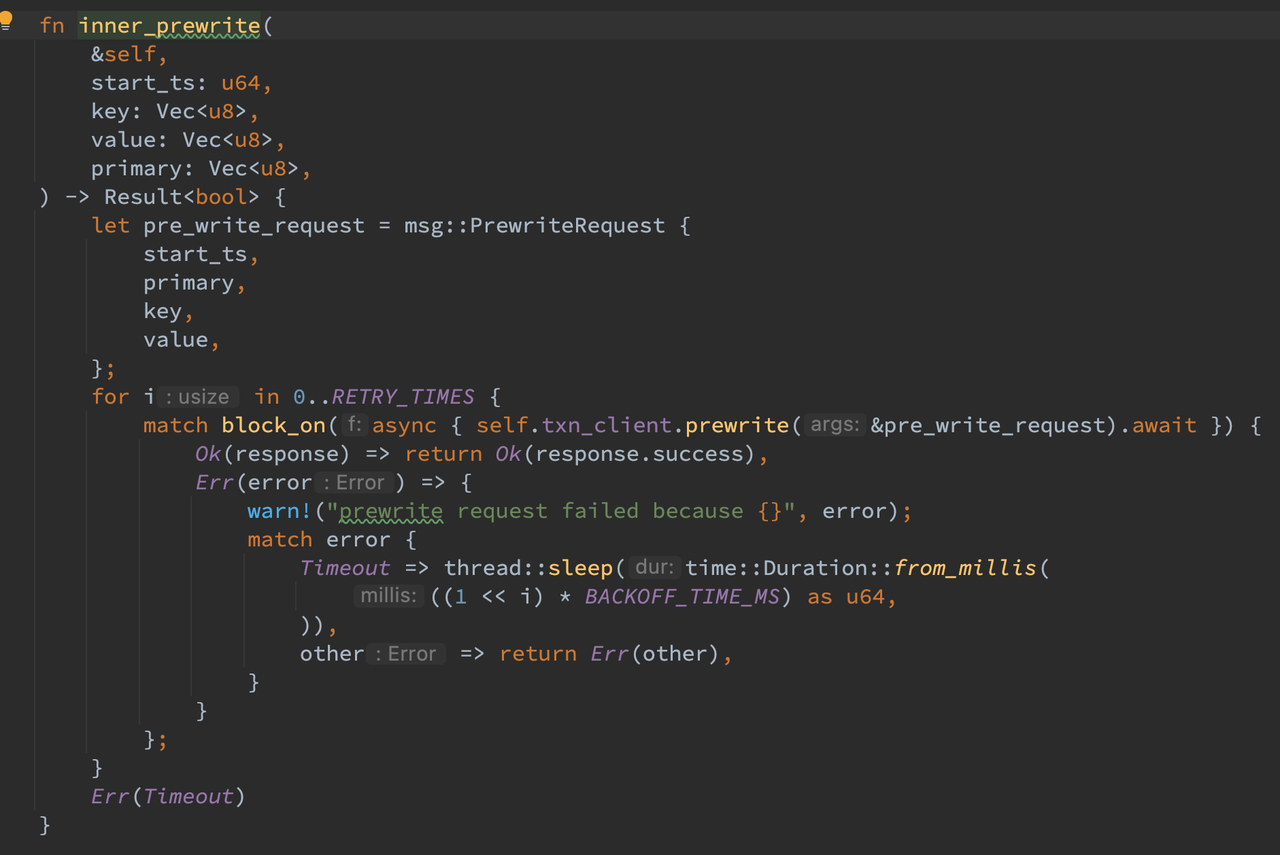
在服务端,首先使用 lock 进入临界区,接着判断 lock 列和 Write 列中是否存在与本事务冲突的其他事务,如果存在则返回错误,此时只能事务执行失败让应用层重试。如果没有冲突的事务,则可以向 data 列写入暂时不可见的数据,接着向 lock 列写入锁来保证不会出现 lost update。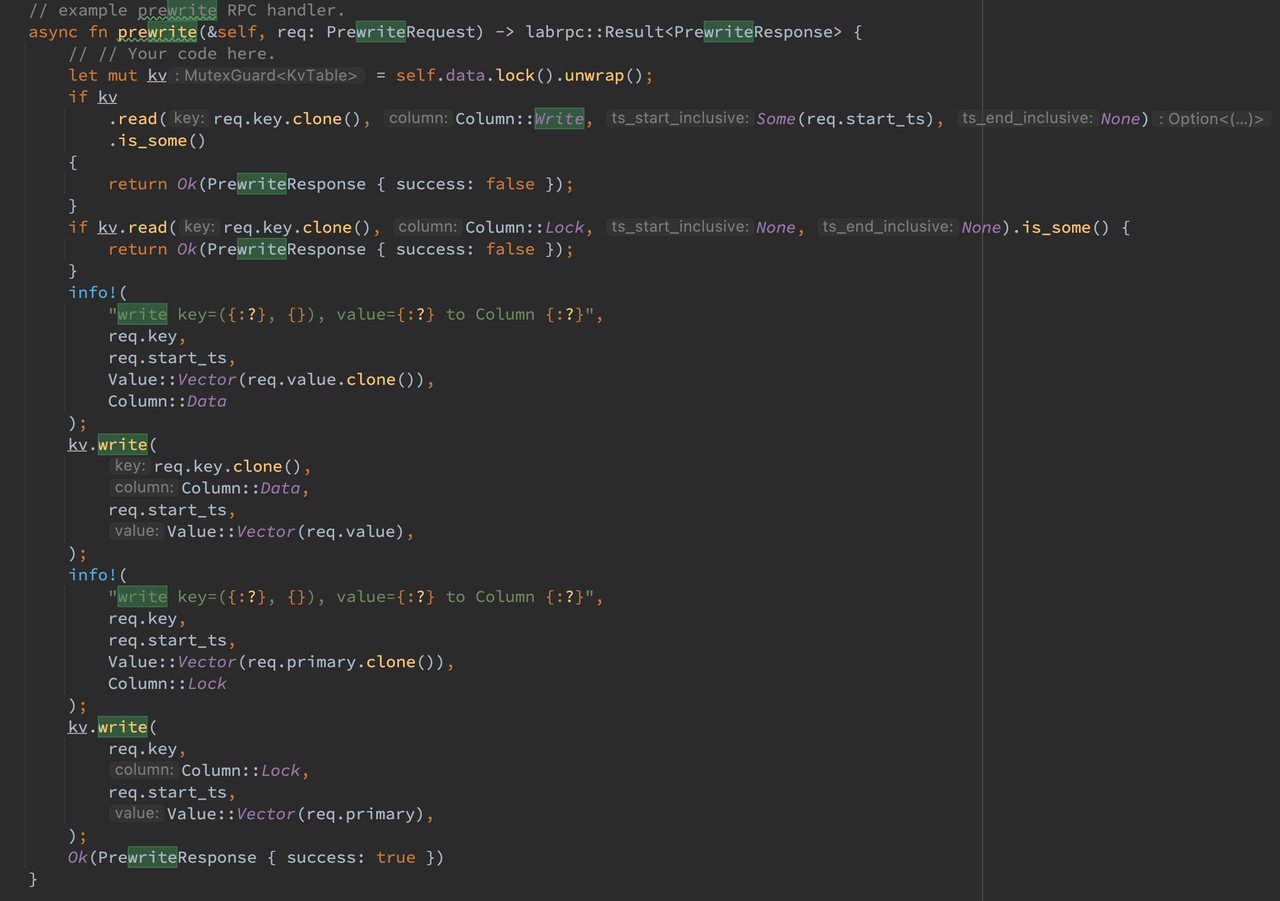
在 KVTable 的 write 函数中,使用 BTreeMap 的 insert 接口来新增对应的 entry。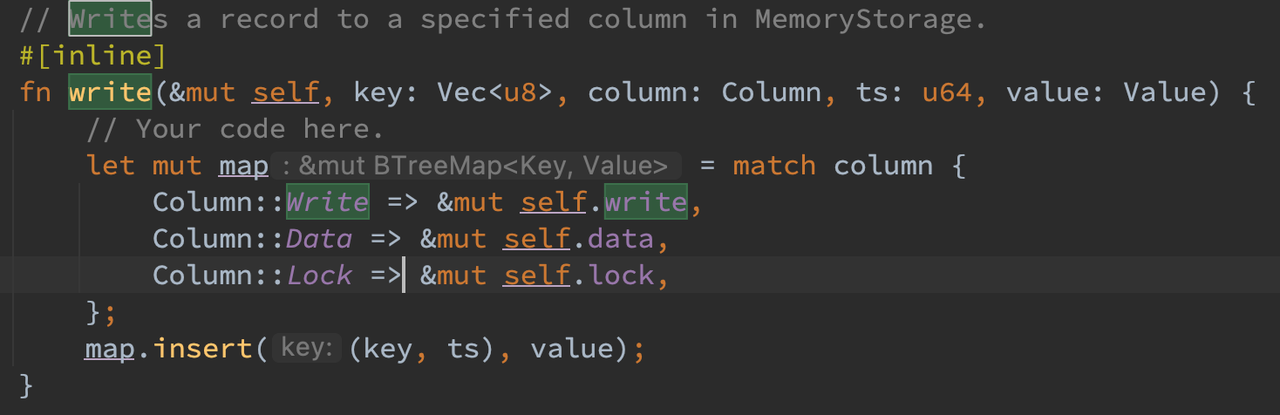
需要注意的是,该 Lab 中并未引入分片的概念,因此可以认为所有的数据均在一个分片,因此理论上可以直接使用 1PC 的方式将请求直接在服务端进行 PreWrite & Commit 处理。本人也进行了 1PC 的实现,在实现完后发现存在一个测试并不希望按照 1PC 去处理,因而便采用了效率最低但和论文伪码以及测试能够对应的方式,每个 key 都会发一次 rpc 且 prewrite 和 commit 会发两轮 rpc。
commit
对于 Commit 请求,需要携带 start_ts, commit_ts,是否为 primary 以及对应要 commit 的 key。客户端添加了对应的重试和错误处理逻辑,并将参数发送给服务端。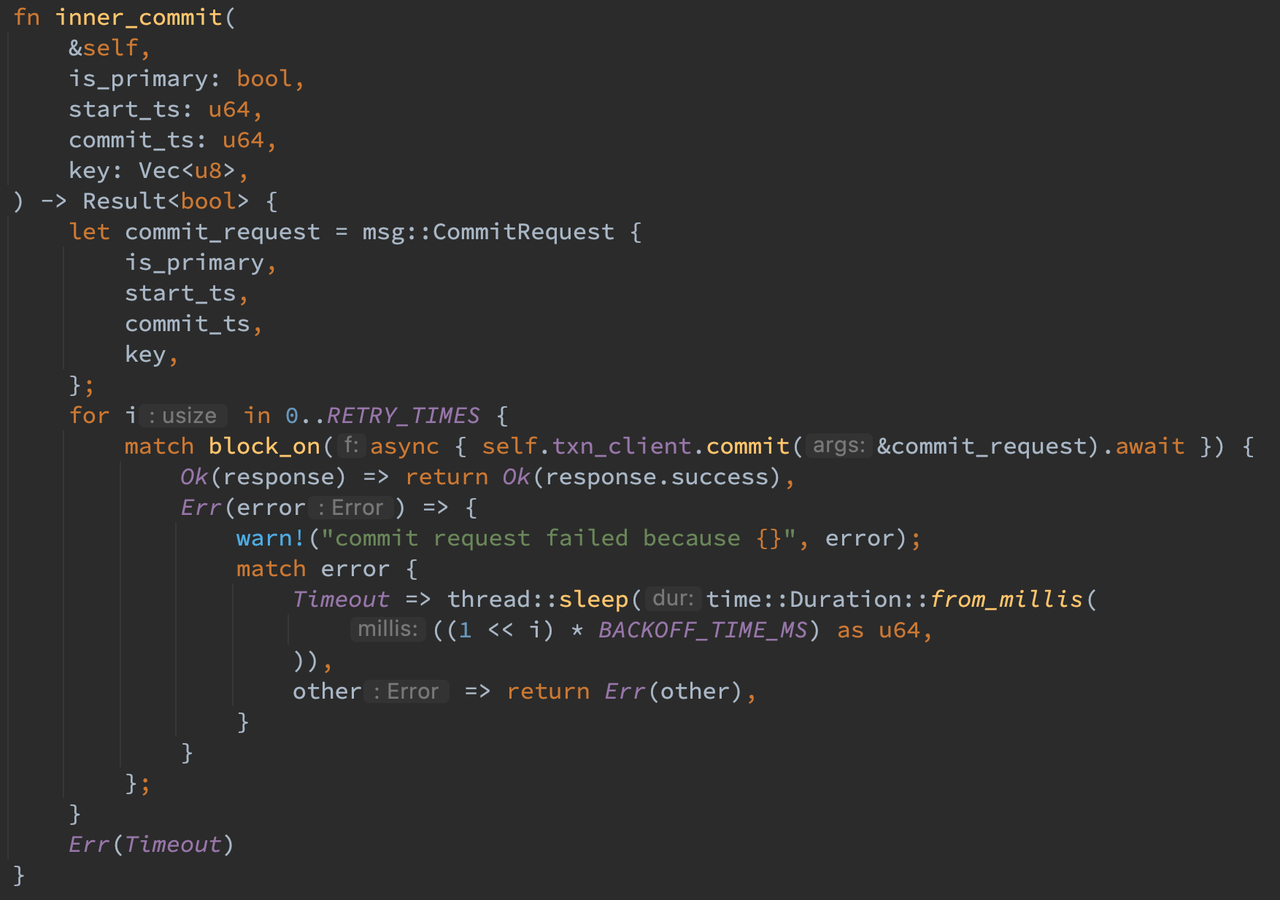
在服务端,首先使用 lock 进入临界区,接着判断 lock 列是否存在自己的锁,如果不存在则说明发生了不符合预期的错误(比如此次 RPC 延期到达,或者本事务已经被其他事务 abort 且清理),此时只能返回失败让应用层处理。如果自己的锁存在,则可以向 write 列写入 ((key, commit_ts), start_ts) 以让 data 列的数据可见,接着移除掉 lock 列写入的锁即可。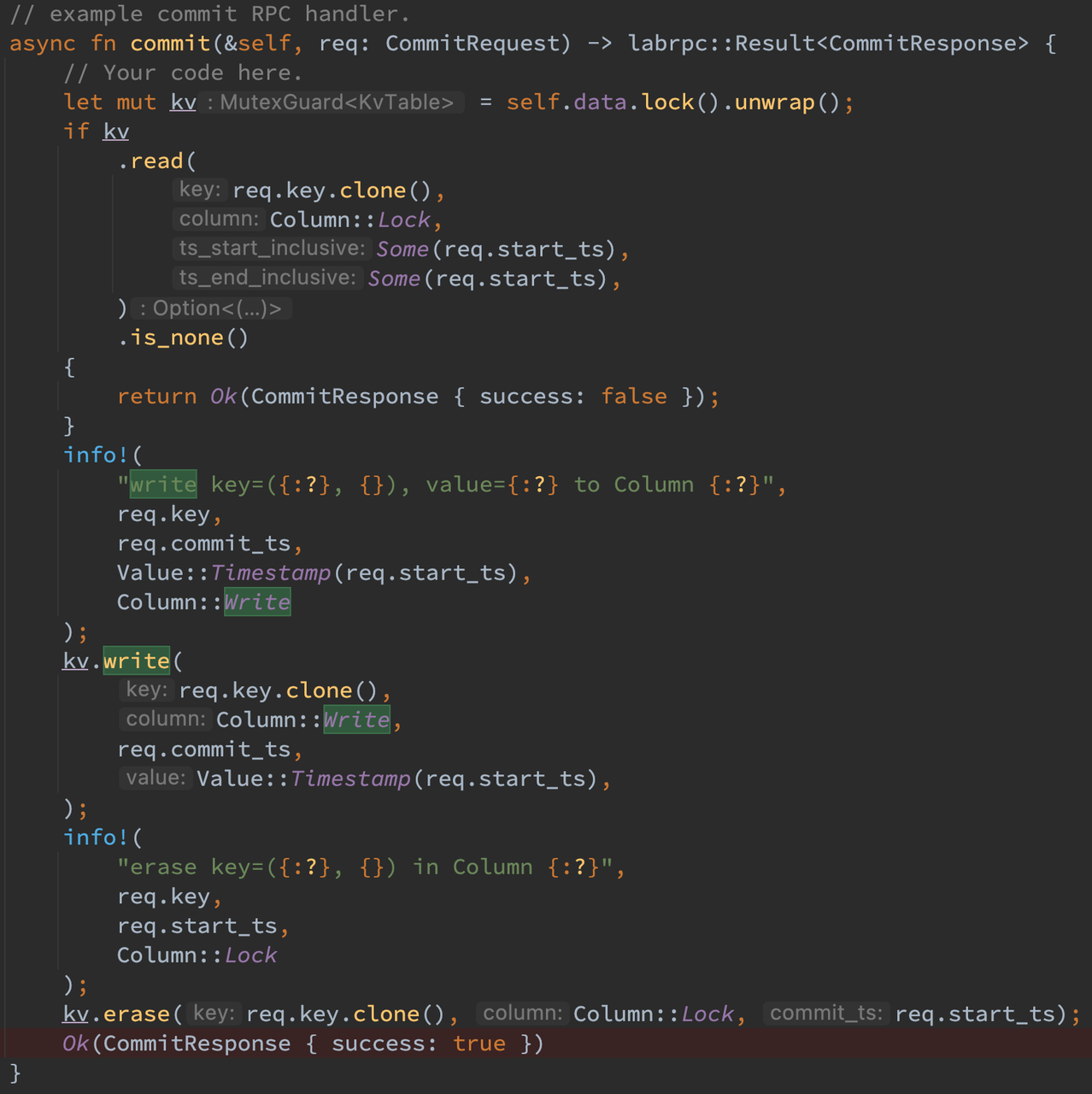
在 KVTable 的 erase 函数中,使用 BTreeMap 的 remove 接口来移除对应的 entry。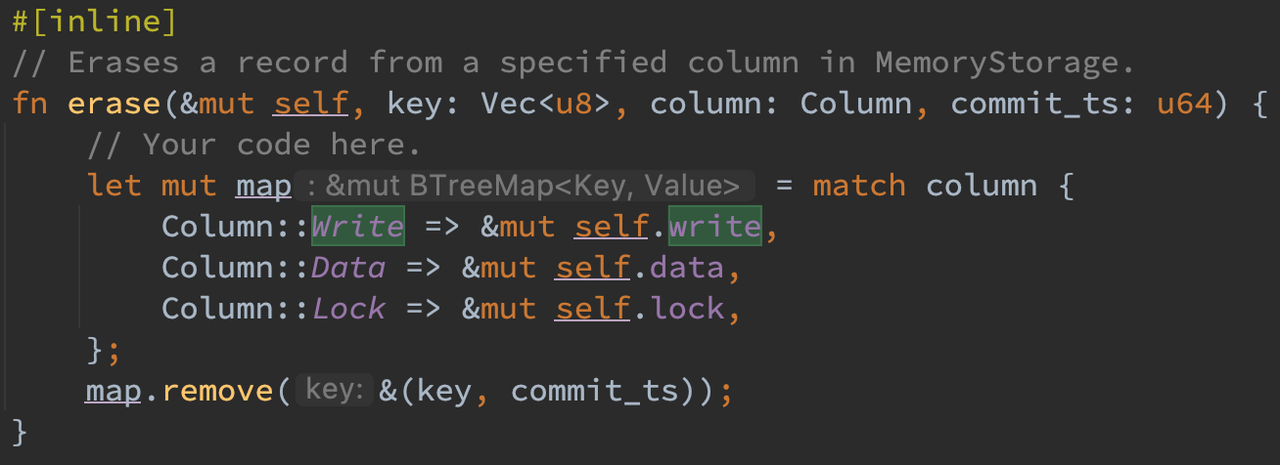
测试结果
以上逻辑通过了事务正常提交时的测试,然而网络异常或者协调者异常时的测试还未完全 AC,因此还需要进一步处理。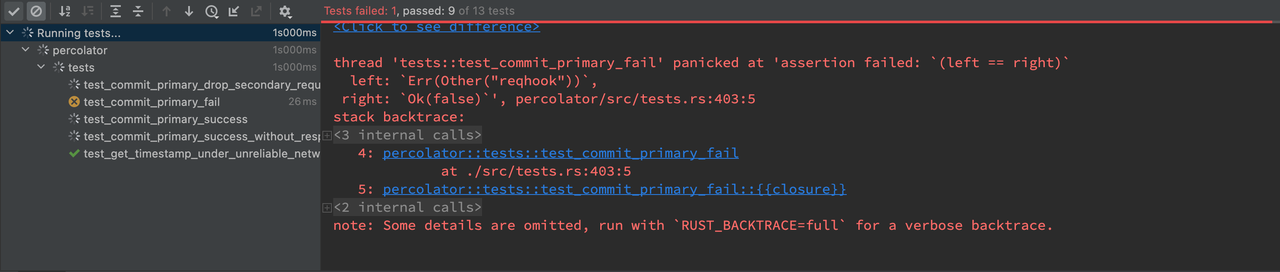
通过本测试的新增代码可查看 commit
TXN 异常测试
- test_commit_primary_drop_secondary_requests
- test_commit_primary_success
- test_commit_primary_success_without_response
- test_commit_primary_fail
异常测试会模拟 commit 请求的 req/resp 被丢弃的场景,但是 primary 的 commit 会始终被满足,因而 secondary 的请求有可能会被丢弃。
在客户端侧,首先需要针对 test_commit_primary_fail 和 test_commit_primary_success_without_response 返回的错误进行特判处理,同样是发 rpc 出错,但他们一个要求 client 返回 Err(Error::Other(“resphook”.to_owned())),另一个要求返回 Ok(False)。尽管并不统一,但可以通过修改特判 Err 类型的方式来通过测试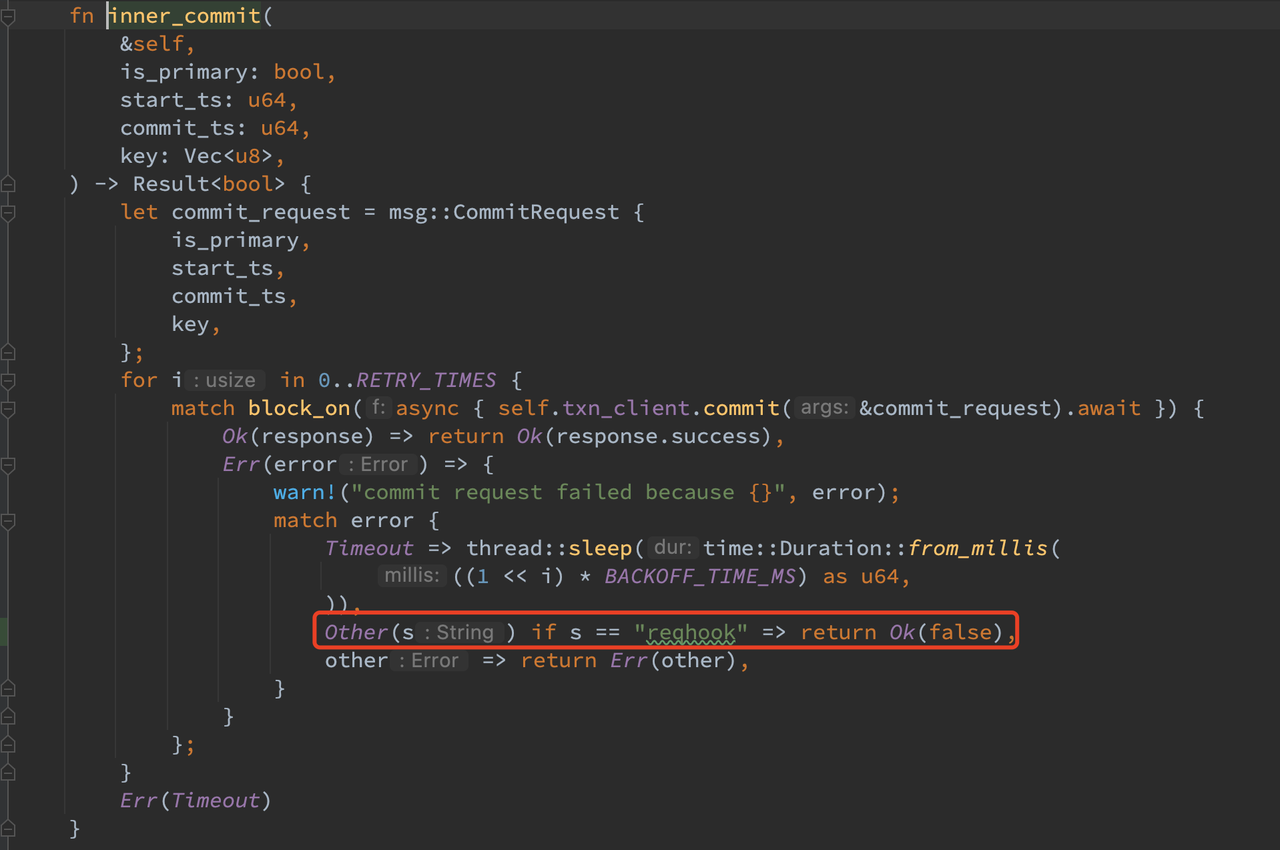
在服务端侧,异常测试主要实现的函数便是 back_off_maybe_clean_up_lock,即当遇到其他事务遗留下来的 prewrite 结果时要如何处理。
对于 percolator 这种事务模型,primary key 的提交与否便是整个事务提交与否的标志。任何事务在读某一 key 时,如果遇到遗留的 Lock 列锁,在 sleep 超过 TTL 时间后,可以接着获取该冲突 key1 在 lock 列 key 中的 start_ts 和 value 中存的 primary 值。然后再去 Write 列中寻找 (primarykey,0) 和 (primarykey, u64::MAX) 范围内是否有指向 start_ts 的记录。如果存在,则说明该事务已经提交且能够获取到 commit_ts,此时对该 key1 做 commit 处理即可,即清理 Lock 列并在 Write 列添加对应的记录。如果不存在,则说明该事务尚未提交,且其他任何 rpc 再执行的时候都能够确定性的判断出该事务并未提交(即便是乱序到达的 primary commit rpc,其也会检测 lock 记录是否存在,只有存在时才能 commit),此时只需要将当前 key1 的遗留 lock 清理即可。尽管也可以顺便检测清理其他的遗留 key,但让其他的遗留 key 在需要清理时再进行清理也不影响 safety,因而只用清理 key1 即可。在 key1 清理完之后,当前事务便可以正常读取 key 的值了。
代码如下,需要注意在进入 back_off_maybe_clean_up_lock 函数前需要 drop 掉锁,back_off_maybe_clean_up_lock 函数在 sleep 完之后需要先拿到锁再进行操作。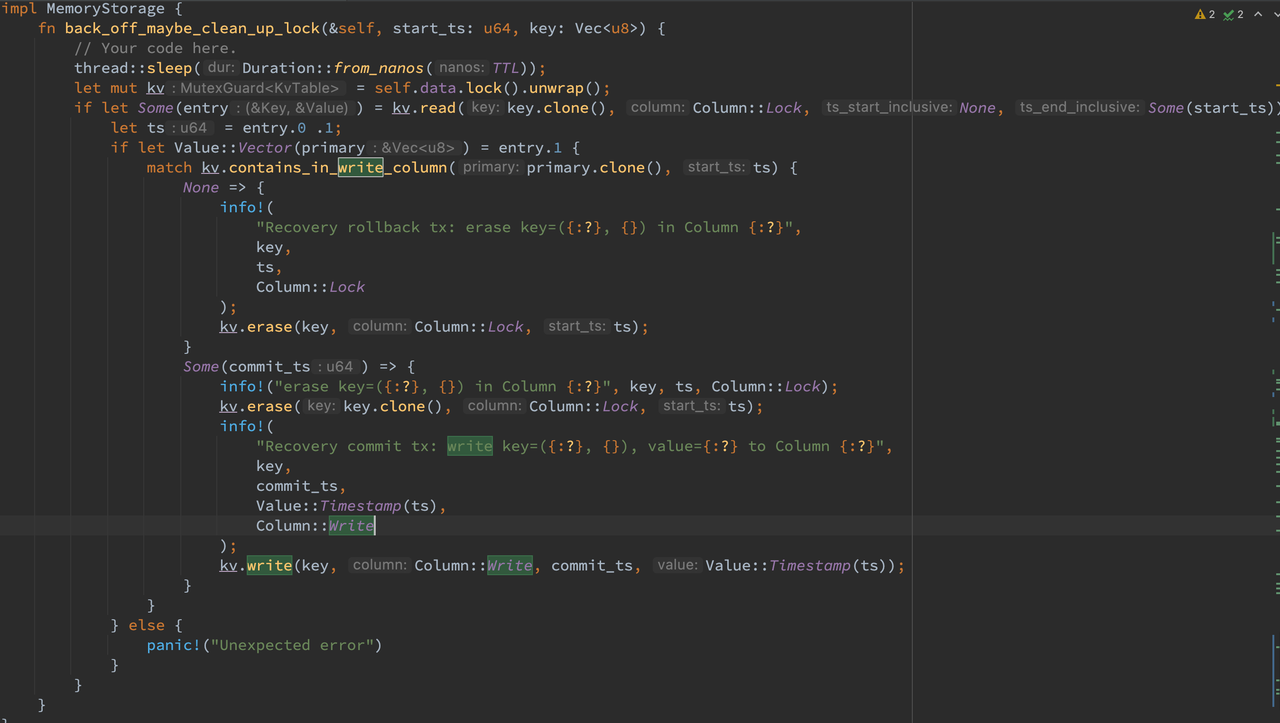
contains_in_write_column 函数遍历 write 列寻找 (primarykey,0) 和 (primarykey, u64::MAX) 范围内是否有指向 start_ts 的记录,如果存在则返回 commit_ts,否则返回 None。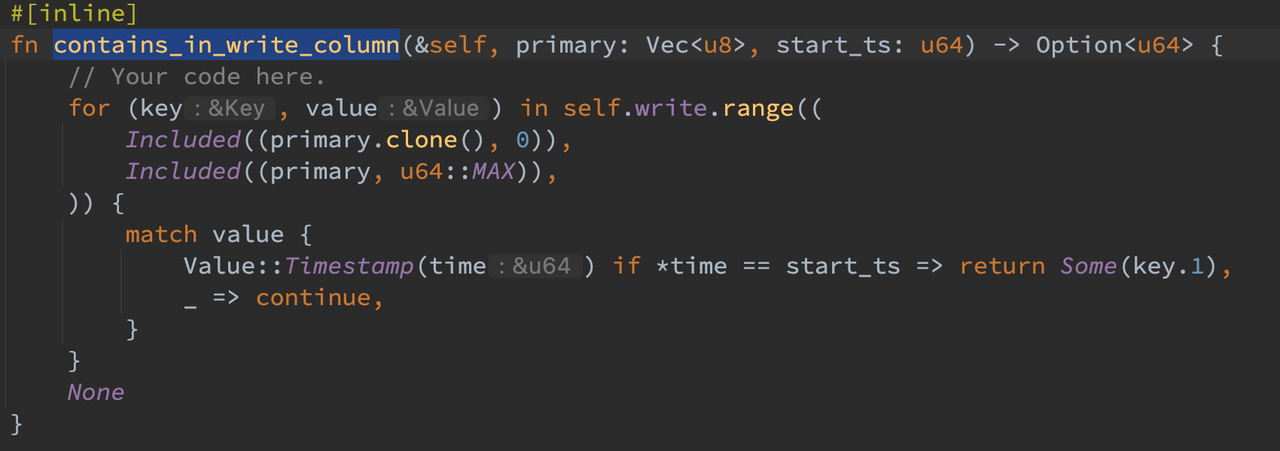
此外 kvtable 中的 erase 函数的参数之前是 commit_ts,但由于在 lock 列中记录的是 start_ts,不论是正常 commit 还是 rollback 均需要按照 (key, start_ts) 去清理而不是 (key, commit_ts),因而感觉这里应该是论文中的笔误被照抄过来了,在此处从 commit_ts 改为了 start_ts。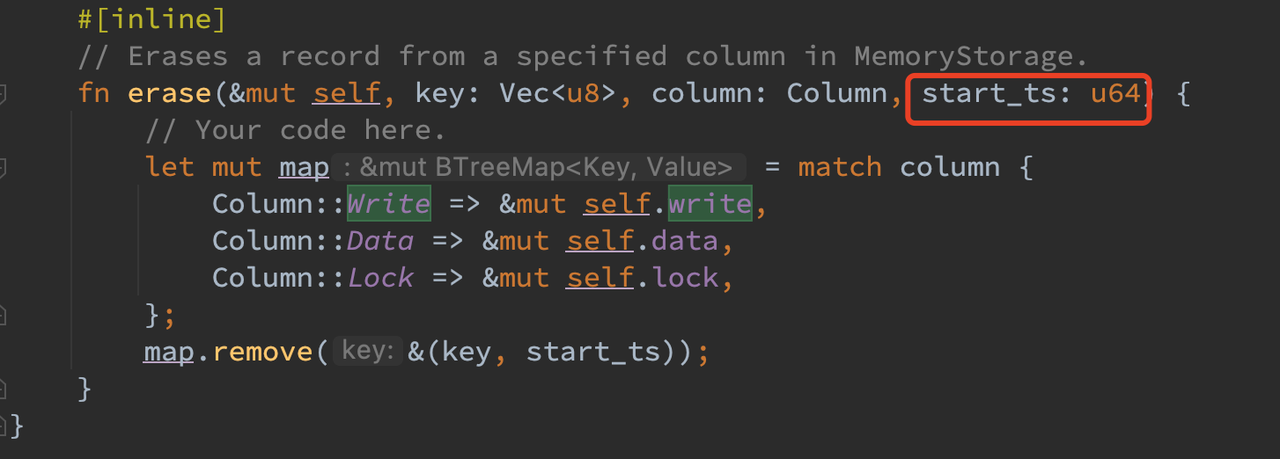
通过本测试的新增代码可查看 commit。
总结
最终所有测试通过如下,本人过关代码可参考该 PR。
通过本 lab,对 Rust 编程的若干关键工具和重要知识点有了一定的实践,包括但不限于 cargo 管理,模式匹配,流程控制,错误处理,所有权与借用,迭代器,宏编程等等。希望未来能够深入理解 rust 的异步编程,成为一名有经验的 Rustacean。