BASE 定理介绍
前言
CAP 理论表明,对于一个分布式系统而言,它是无法同时满足 Consistency(强一致性)、Availability(可用性)和 Partition tolerance(分区容忍性)这三个条件的,最多只能满足其中两个。
对于绝大多数互联网应用来说,由于网络环境是不可信的,所以分区容错性(P)必须满足。
如果只能在一致性和可用性之间做出选择的话,大部分情况下大家都会选择牺牲一部分一致性来保证可用性。因为如果不返回给用户数据,用户的体验会十分差,因此很多应用宁肯拒绝服务也不会能访问却没有数据。当然,在一些较为严格的场景比如支付场景下,强一致性是必须要满足的。
好了,我们只能放弃一致性,但是我们真这样做了,将一致性放弃了,现在这个系统返回的数据你敢信吗?没有一致性,系统中的数据也就从根本上变得不可信了,那这数据拿来有什么用,那这个系统也就没有任何价值,根本没用。
如上所述,由于我们三者都无法抛弃,但 CAP 定理限制了我们三者无法同时满足。在这种情况下,我们只能选择尽量靠近 CAP 定理,即尽量让 C、A、P 都满足。在此大势所趋下,eBay 的架构师 Dan Pritchett 源于对大规模分布式系统的实践总结,在 ACM 上发表文章提出 BASE 理论,其是基于 CAP 定理逐步演化而来的。
定义
BASE 理论是 Basically Available(基本可用),Soft State(软状态)和 Eventually Consistent(最终一致性)三个短语的缩写。
其核心思想是:
即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
Basically Available
基本可用是相对于正常的系统来说的,常见如下情况:
响应时间上的损失:正常情况下的搜索引擎 0.5 秒即返回给用户结果,而基本可用的搜索引擎可以在 2 秒作用返回结果。
功能上的损失:在一个电商网站上,正常情况下,用户可以顺利完成每一笔订单。但是到了大促期间,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
Soft state
软状态是相对原子性来说的:
- 原子性(硬状态):要求多个节点的数据副本都是一致的,这是一种”硬状态”。
- 软状态(弱状态):允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延迟。
Eventually Consistent
最终一致性是相对强一致性来说的:
- 系统并不保证连续进程或者线程的访问都会返回最新的更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。但会尽可能保证在某个时间级别(比如秒级别)之后,可以让数据达到一致性状态。最终一致性是弱一致性的特定形式。
- 对于软状态,我们允许中间状态存在,但不可能一直是中间状态,必须要有个期限,系统保证在没有后续更新的前提下,在这个期限后,系统最终返回上一次更新操作的值,从而达到数据的最终一致性,这个容忍期限(不一致窗口的时间)取决于通信延迟,系统负载,数据复制方案设计,复制副本个数等。DNS 就是一个典型的最终一致性系统。
举例
讲完了定义,大家对于 BASE 到底是什么,到底有什么用可能还存在质疑,可以参照这篇 博客。
最终一致性的种类
在实际工程实践中,最终一致性常被分为 5 种:
因果一致性(Causal consistency)
如果节点 A 在更新完某个数据后通知了节点 B,那么节点 B 之后对该数据的访问和修改都是基于 A 更新后的值。与此同时,和节点 A 无因果关系的节点 C 的数据访问则没有这样的限制。
读己之所写(Read your writes)
节点 A 更新一个数据后,它自身总是能访问到自身更新过的最新值,而不会看到旧值。其实也算一种因果一致性。
会话一致性(Session consistency)
系统能保证在同一个有效的会话中实现 “读己之所写” 的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
单调读一致性(Monotonic read consistency)
如果一个节点从系统中读取出一个数据项的某个值后,那么系统对于该节点后续的任何数据访问都不应该返回更旧的值。
单调写一致性(Monotonic write consistency)
一个系统要能够保证来自同一个节点的写操作被顺序的执行。
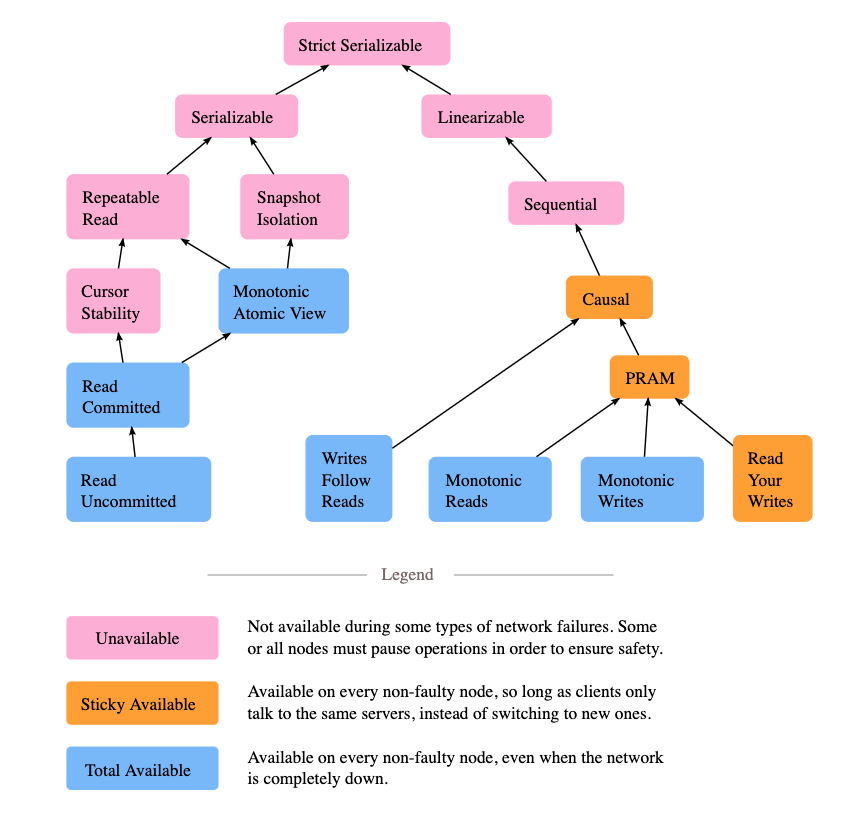
在实际的实践中,这 5 种系统往往会结合使用,以构建一个具有最终一致性的分布式系统。
事实上,最终一致性并不是只有那些大型分布式系统才设计的特性,许多现代的关系型数据库都采用了最终一致性模型。在现代关系型数据库中,大多都会采用同步和异步方式来实现主备数据复制技术。在同步方式中,数据的复制通常是更新事务的一部分,因此在事务完成后,主备数据库的数据就会达到一致。而在异步方式中,备库的更新往往存在延时,这取决于日志在主备数据库之间传输的时间长短,如果传输时间过长或者甚至在日志传输过程中出现异常导致无法及时将事务应用到备库上,那么很显然,从备库中读取的的数据将是旧的,因此就出现了不一致的情况。当然,无论是采用多次重试还是将数据修正,关系型数据库还是能够保证最终数据达到一致——这就是关系数据库提供最终一致性保证的经典案例。
生产系统的最终一致性示例可参考此 博客。
ACID
概念
ACID,是指数据库管理系统在写入或更新数据的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:
- 原子性(atomicity,或称不可分割性)
- 一致性(consistency)
- 隔离性(isolation,又称独立性)
- 持久性(durability)
原子性
一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
隔离性
数据库允许多个并发事务同时对齐数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
持久性
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
与 BASE 的联系
可以参考 PODC 的介绍:

- ACID 是传统数据库常用的设计理念,追求强一致性模型。
- BASE 支持的是大型分布式系统,提出通过牺牲强一致性获得高可用性。
与 CAP 的联系
CAP 理论的一致性是保证同样一个数据在所有不同服务器上的拷贝都是相同的,这是一种逻辑保证,而不是物理,因为光速限制,在不同服务器上这种复制是需要时间的,集群通过阻止客户端查看不同节点上还未同步的数据维持逻辑视图。
当跨分布式系统提供 ACID 时,这两个概念会混淆在一起,Google’s Spanner system 能够提供分布式系统的 ACID,其包含 ACID+CAP 的设计:
总结
总体来说 BASE 理论面向的是大型高可用、可扩展的分布式系统。与传统 ACID 特性相反,不同于 ACID 的强一致性模型,BASE 理论基于 CAP 定理提出通过牺牲强一致性来获得可用性,并允许数据段时间内的不一致,但是最终达到一致状态。同时,在实际分布式场景中,不同业务对数据的一致性要求不一样。因此在设计中,ACID,BASE 和 CAP 理论往往又会结合使用。