Monarch 论文阅读
摘要
Monarch 是谷歌的一个全球分布的内存时间序列数据库系统,它被广泛用在监控谷歌上十亿用户规模的应用程序和系统的可用性、正确性、性能、负载和其他方面。
Monarch 自 2010 年开始持续运行,收集、组织、存储、查询大量全球范围内快速增长的时间序列数据。它目前在内存中存储近 PB 的压缩时间序列数据,每秒摄入 TB 的数据,每秒处理数百万次查询。
本文介绍了系统的结构,以及在区域分布式架构下实现可靠、灵活的统一系统的新机制。我们也分享了十年来在谷歌中开发和运行 Monarch 作为服务的经验教训。
介绍
谷歌有大量的计算机系统监控需求。数以千计的团队正在运营面向全球用户的服务(如 YouTube、GMail 和 Google Maps),或者为这些服务(如 Spanner、Borg 和 F1) 提供硬件和软件基础设施。这些团队需要监视不断增长和变化的异构实体(例如设备、虚拟机和容器)集合,这些实体数量达数十亿,分布在全球各地。
谷歌必须从这些实体中收集度量,以时间序列的形式存储,并进行查询,以支持以下用例:
- 当被监视的服务没有正确执行时检测和警报;
- 显示显示服务状态和运行状况的图形仪表板;
- 针对问题的不可知性执行特别查询,探索性能和资源使用情况。
Borgmon 是谷歌内部的初代监控系统。随着大数据时代的到来,Borgmon 的部署规模逐渐扩大,暴露了一些弊端:
- Borgmon 常被鼓励使用成一种分散的架构,即每个团队都建立并管理自己的 Borgmon 实例,这导致一些人力资源的浪费。此外,用户经常需要跨应用程序和基础设施边界检查和关联监控数据以解决问题,而跨多个 Borgmon 实例来操作是很难或不可能实现的;
- Borgmon 缺乏度量符号和度量值的图表化,导致了查询的语义歧义,限制了查询语言在数据分析过程中的表达能力;
- Borgmon 不支持分布(即柱状图)值类型,这是一种强大的数据结构,能够进行复杂的统计分析(例如,计算跨多个服务器的请求延迟的 99%);
- Borgmon 要求用户手动跨多个实例对大量被监视的全局服务实体进行切分,并建立查询评估树。
考虑到这些经验教训,Monarch 成为了谷歌的下一代大规模监控系统。它的设计是为了适应持续增长的流量,并支持不断扩展的用例集。它为所有团队提供单一的统一服务,从而最大限度地减少了操作的工作量。它有一个简化的数据模型,便于复杂的查询和分布式类型时间序列的全面支持。
系统概述
Monarch 的设计理念:
- Monarch 技术上被设计成了一个 AP 系统而不是 CP 系统。他们认为在监控报警的场景下可用性比一致性重要得多,因为这能够显著增加检测到异常情况和减轻异常影响的平均时间。
- Monarch 的关键报警路径上不能产生循环依赖,即不能使用谷歌内部的 Bigtable, Colossus (the successor to GFS), Spanner, Blobstore, and F1 等存储系统再去监控这些存储系统的集群(非关键路径可以适当使用)。
- 结合全局管理和查询对区域 zone 进行本地监控。在降低延迟,减少可靠性问题的同时能够提供全球视角。
- 为了可靠性,Monarch 的全局组件在地理上进行复制,并使用最接近的副本与地域性组件交互以利用局部性,其区域 zone 中的组件将跨集群复制。
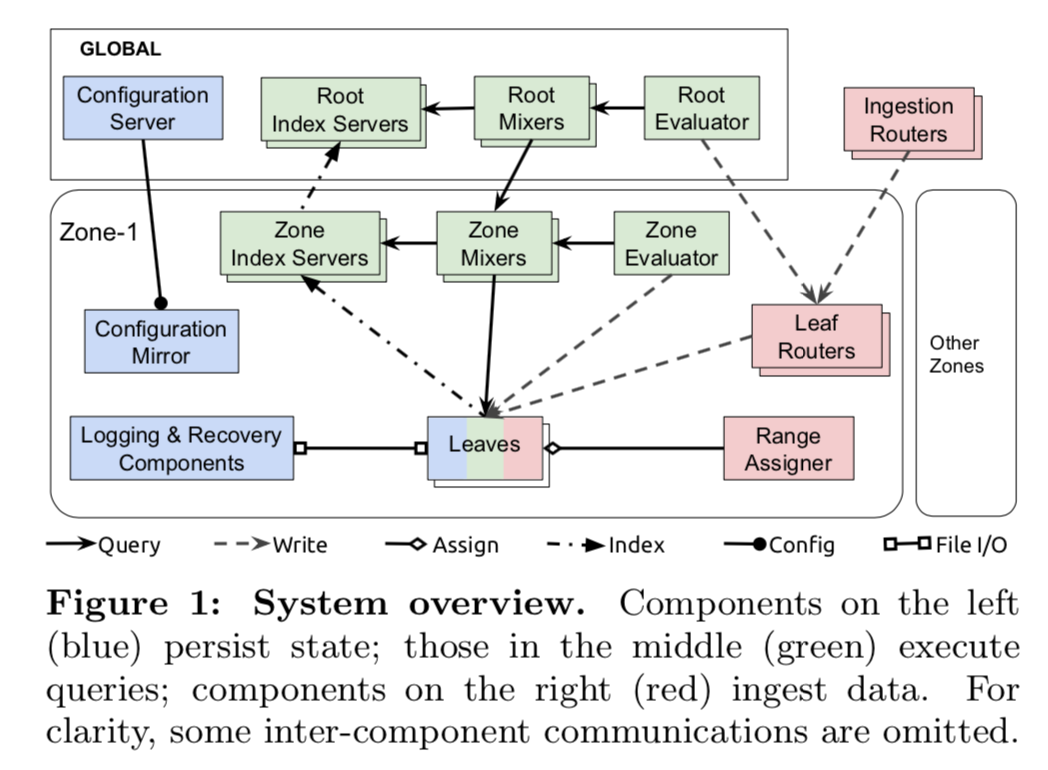
从功能上讲,为了可靠性,Monarch 组件可以分为三类:持有状态组件、数据存储组件和查询执行组件。
持有状态组件:
- 叶子(Leaves)将监视数据存储在内存中的时间序列存储中。
- 恢复日志(Recover Logs)将与叶子相同的监视数据存储在磁盘上,这些数据最终会被重写到一个长期时间序列存储库中。
- 全局配置服务器及其分区镜将配置数据保存在 Spanner 数据库中。
数据存储组件:
- 摄取路由器(Ingestion Routers)使用时间序列键中的信息来路由数据到适当的 Monarch 区域中的叶路由器。
- 叶路由器(Leaf Routers)接受数据存储在一个区域 zone,并路由到叶子存储。
- 范围分配管理器(Range Assigner)将数据分配到叶子,以平衡在一个区域的叶子之间的负载。
查询执行组件:
- 混合器(Mixers)将查询划分为多个子查询,将其路由到叶子去执行并合并子查询结果。查询可以在根级别(由根混合器)或在区域 zone 级别(由区域混合器)发出。根级查询同时涉及根和区域 zone 混合器。
- 索引服务器(Index Server)为每个区域 zone 和叶节点索引数据,并指导分布式查询执行。
- 评估器(Evaluator)定期向混合器发出长期查询并将结果写回叶子。
数据模型
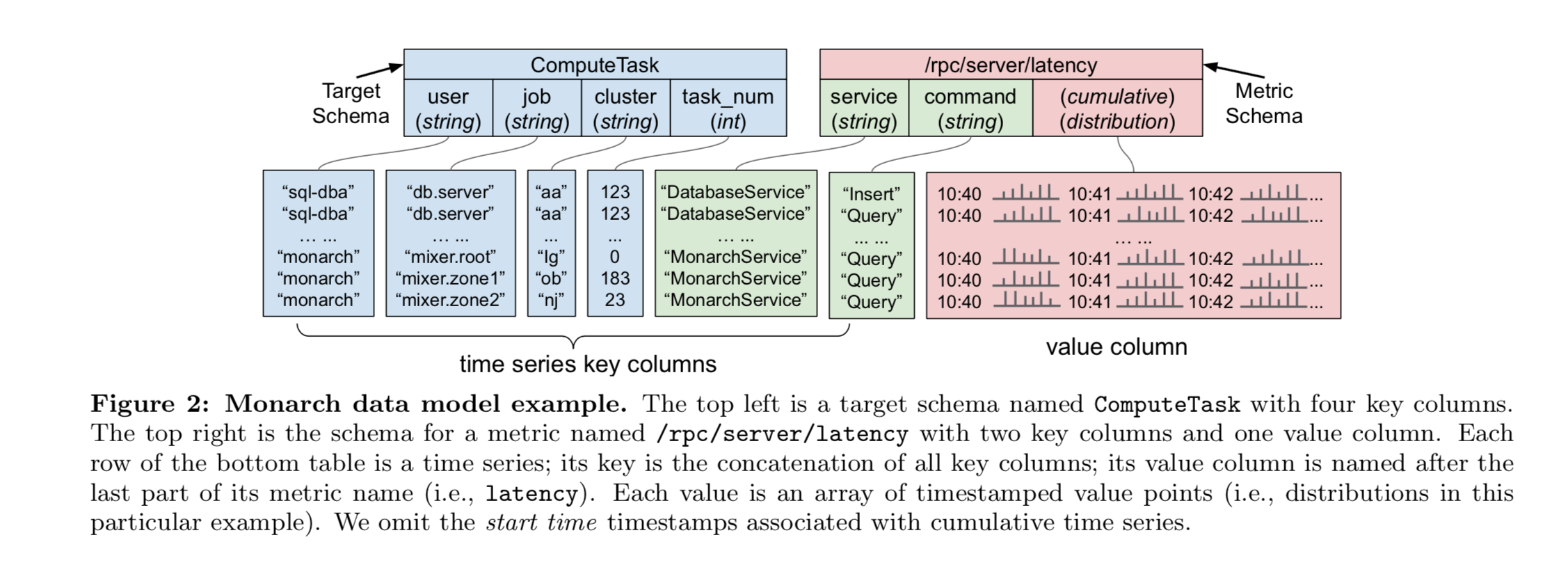
从概念上讲,Monarch 将监控数据存储为结构化表中的时间序列。每个表由多个键列组成时间序列键和一个值列组成时间序列点的历史,如图 2 所示。键列也称为字段,有两个源:目标(Target)和指标(Metric)。
Target
Monarch 使用 Target 将每个时间序列与它的源实体(或监视实体)相关联。例如,源实体就是生成时间序列的进程或 VM。每个 Target 表示一个受监视的实体,并符合一个 Target Schema,该模式定义了一组有序的 Target 字段名和相关字段类型。上图显示了一个名为 ComputeTask 的流行目标模式:每个 ComputeTask 目标标识 Borg 集群中正在运行的任务,具有四个字段:user、job、clsuter 和 task_num。
Monarch 将数据存储在离生成数据很近的位置。每个 Target Schema 都有一个标注为 location 的字段;这个位置字段的值决定了时间序列被路由和存储到的特定 Moranch zone。
在每个 zone 内,Monarch 将同一目标的时间序列存储在同一叶子中,因为它们来自同一实体,并且更有可能在一个 join 中被一起查询。Monarch 还将目标以[S_start,S_end]的形式分组为不同的目标范围,其中 S_start 和 S_end 是开始和结束目标字符串。目标字符串通过有序连接 Target Schema 名称来表示。
Target 范围用于字典分片和叶节点间的负载均衡;这允许在查询中更有效地跨邻近目标聚合。
Metric
Metric 测量被监视目标的一个方面,如任务所服务的 RPC 数量、VM 的内存使用情况等。与 Target 类似,Metric 也有 Metric Schema,该模式定义时间序列值类型和一组指标字段。指标的命名类似于文件。图 2 显示了一个称为 /rpc/server/latency 的示例度量,它测量 RPC 到服务器的延迟;它有两个度量字段,通过 service 和 command 来区分 RPC。
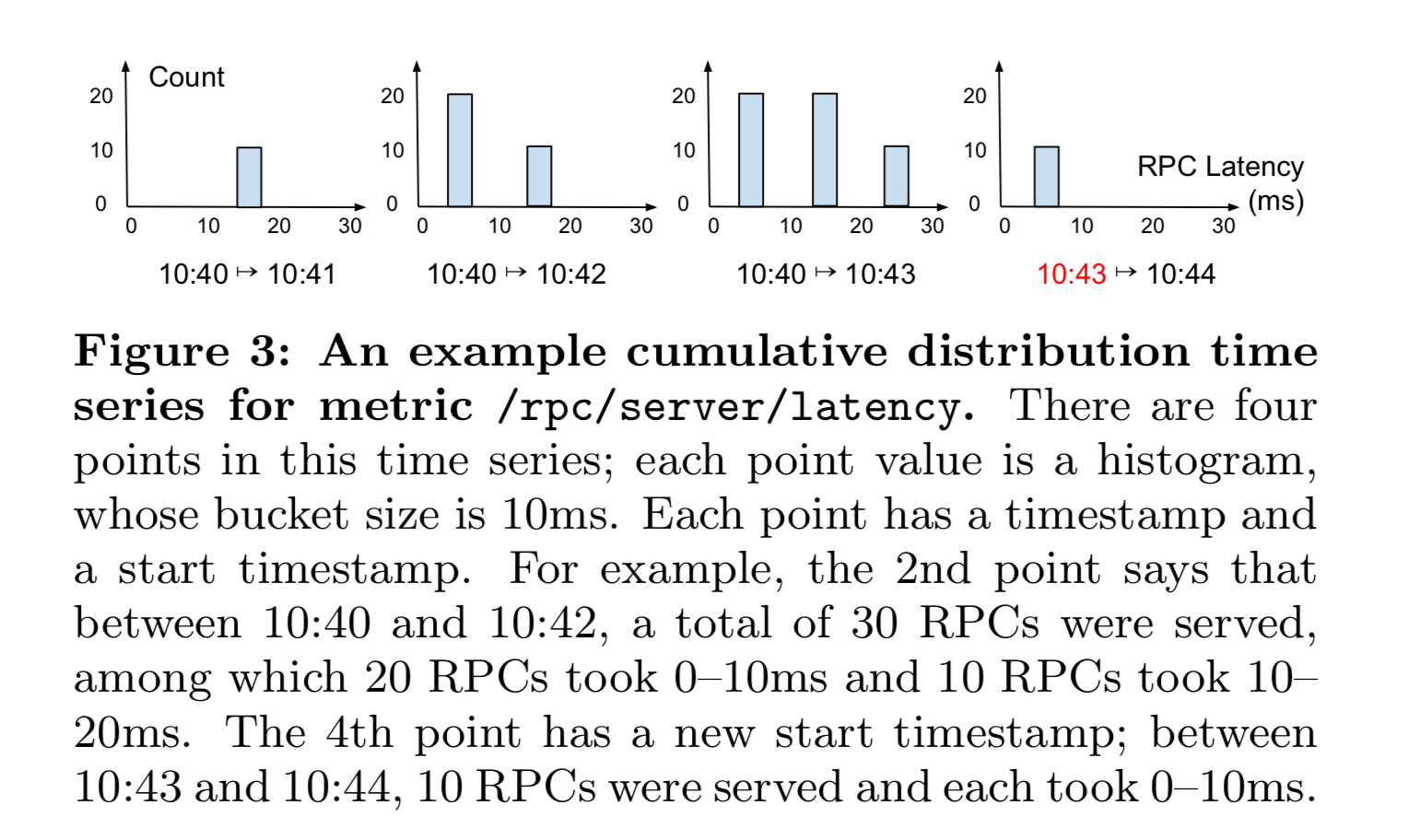
值类型可以是 bool、int64、double、string、分布类型或其他类型的元组。除了分布类型之外,它们都是标准类型,分布类型是一种紧凑类型,表示大量双精度值。分布包括一个直方图,该直方图将一组 double 值划分到称为 bucket 的子集中,并使用总体统计信息(如平均值、计数和标准差)汇总每个 bucket 中的值。桶边界是可配置的,可以在数据粒度(即精度)和存储成本之间进行权衡:用户可以为更流行的值范围指定更细的桶。图 3 显示了一个测试组分布类型的 /rpc/server/latency 时间序列,它测量服务器在处理 RPC 时的延迟;它有一个固定的桶大小为 10ms。
Exemplars:分布中的每个桶可以包含该桶中的值的一个范例。这会便于用户轻易的从直方图中找到慢 RPC 的详细信息。
Metric types:可以是度量类型或累积类型。累积 Metric 对于支持由许多服务器组成的分布式系统非常重要,这些服务器可能由于作业调度而定期重新启动,在重新启动期间可能会丢失一些点。
可扩展收集
为了实时摄取大量的时间序列数据,Monarch 采用了两种分治策略和一种关键的优化,在收集过程中对数据进行聚合。
数据收集概述
摄取路由器根据位置字段将时间序列数据划分给 zone,叶路由器根据范围分配管理器将数据分布在叶子之间。
一些细节:
- 客户端会按照特定频率将数据发送到离其最近的摄取路由器(全球分布)。
- location-to-zone 的映射配置在摄取路由器中且可以动态更新。
- 每个叶路由器维护一个持续更新的 range map,该映射将每个目标范围映射到三个叶子副本。注意叶路由器从叶子而不是从范围分配管理器获得范围映射的更新。
- 最小化内存碎片和分配混乱。为了在 CPU 和内存之间实现平衡,内存存储只执行少量压缩,比如时间戳共享和增量编码。时间戳共享非常有效:一个时间戳序列平均被大约 10 个时间序列共享。
- 尽最大努力异步向分布式文件系统写恢复日志但不需要确认来隔离分布式文件系统的故障。
- 叶子收集的数据还会触发用于约束读放大的 zone 和 root 索引服务器中的更新。
zone 内部的负载均衡
一个表模式由一个 target 模式和 schema 模式组成。target 模式的编码是 Monarch 用来分片的依据,这减少了写放大,即一次 RPC 可以携带一个 target 和几百个 metric,且这些数据最终最多被送到 3 个叶副本(不是有个 range map 吗,如果刚好在边界呢?)。这样的分配有利于查询操作的下推。
一些细节:
- 副本数(1-3)可自由配置。
- 通常,Monarch zone 包含多个故障域(集群)中的叶子;分配者会将范围的副本分配到不同的故障域。
- 范围分配管理器会根据 CPU 负载,内存使用量等变量来对不同的 Range 进行分裂或合并。
- 迁移时新节点利用恢复日志来重新构建数据,此外迁移过程中是新旧双写的,这样就不影响上层应用的可用性。
收集聚合
在有些监控场景下,用户只想知道整个人或某个集群的某个监控信息一段时间内的统计值而不是每个值。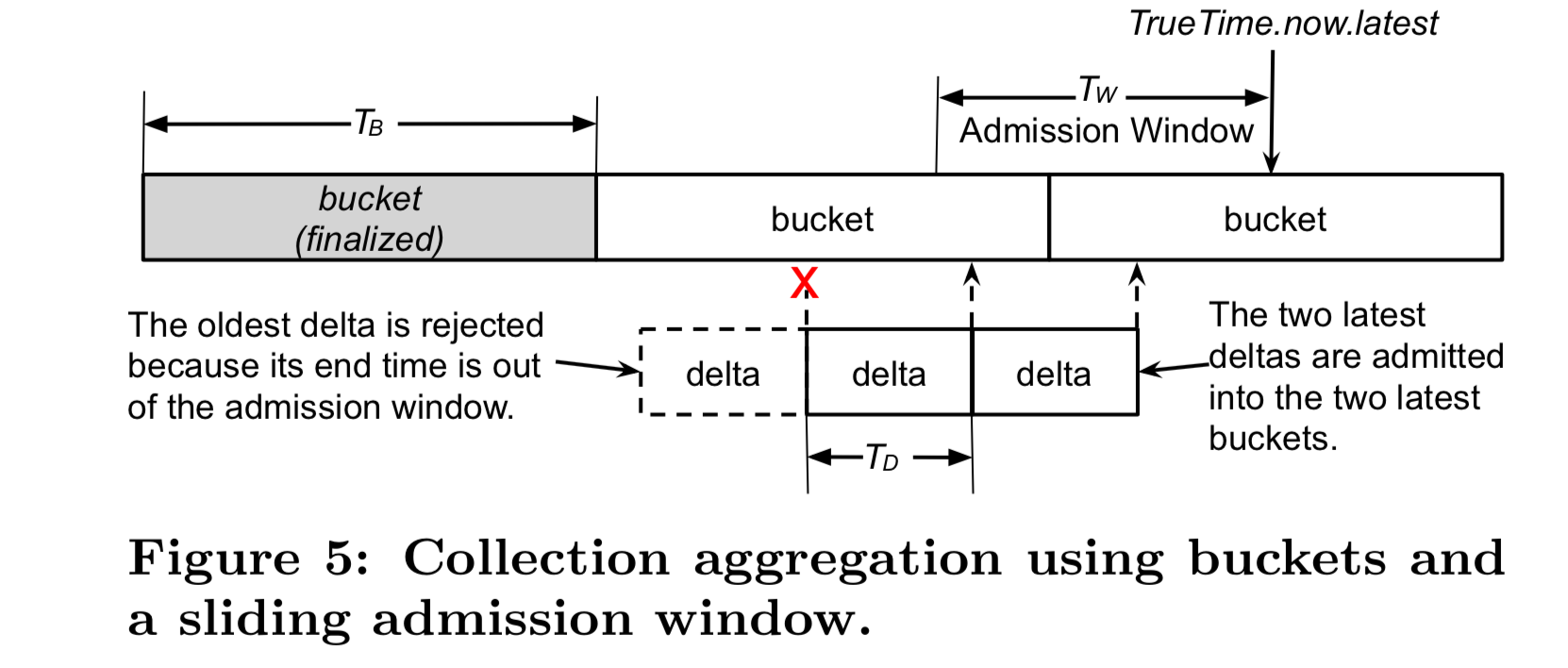
Monarch 利用分组连续聚合的方式收集数据并抛弃过时的数据,还用了 TrueTime 大杀器来确保时间分组的正确,实现了实时收集聚合。
可扩展查询
为了查询时间序列数据,Monarch 提供了一种由分布式引擎支持的表达语言,该分布式引擎使用静态不变量和新的索引来本地化查询执行。
查询语言

听他吹的很牛逼就完事了。类似于 SQL,表达能力比较强吧。
读流程概述
系统中有两种查询:临时查询和长期查询。前者是系统外的用户偶尔执行的,后者是 Monarch 周期性执行的物化视图,还会被重新写入到 Monarch 中来提高查询效率和报警。
查询时也会分三层,即先从根混合器分配到 zone 混合器,然后再被分配到叶子中去。当然为了减少读放大,混合器都会向同一级别的索引服务器请教来剪枝(类似于布隆过滤器)。
Monarch 叶子的不同副本之间不是完全实时一致(最终一致),其会有一个质量参数,查询时混合器会对该时间序列不同 range 的分片挑选其质量最高的副本来读数据。
Monarch 做了租户隔离,会跟踪每个用户在集群中查询时使用的总内存,并在越界时取消查询,同时也为每个用户分配了公平的 CPU 时间。
查询下推
查询下推增加了可评估的查询规模,并减少了查询延迟,原因如下:
- 更低级别的评估越多,意味着更稳定和均匀分布的负载。
- 在较低级别计算的全部或部分聚合大大减少传输到较高级别节点的数据量。
提示字段索引
为了实现高可伸缩性,Monarch 使用存储在索引服务器中的字段提示索引 (FHI) 来限制从父节点向子节点发送查询时放大,方法是跳过不相关的子节点(那些没有向特定查询输入数据的子节点)。一个 FHI 是一个简明的,持续更新的索引时间序列字段值。FHIs 通过分析查询中的字段谓词跳过不相关的子字段,并有效地处理正则表达式谓词,而无需遍历精确的字段值。FHI 工作的区域有数万亿个时间序列键和超过 10000 个叶子,同时保持足够小的大小以存储在内存中。
可靠查询
- Monarch 的查询能够在文件系统或全局组件失效时继续工作。
- Monarch 时间序列的不同分片之间存在重叠。即适度的冗余存储有助于读性能的提升。
- Monarch 查询时还会有一些回退叶子来防止某些慢叶子对查询的影响。即 zone 混合器会在主叶和回退叶之间并行地继续进行,并从两个中较快的叶中提取和删除响应。
配置管理
由于 Monarch 作为分布式的、多租户的服务运行的特性,需要一个集中的配置管理系统来为用户提供方便的、细粒度的控制,以便在整个系统中对其监视和分布配置进行控制。用户与影响所有 Monarch zone 的单一全局配置视图交互。
实现
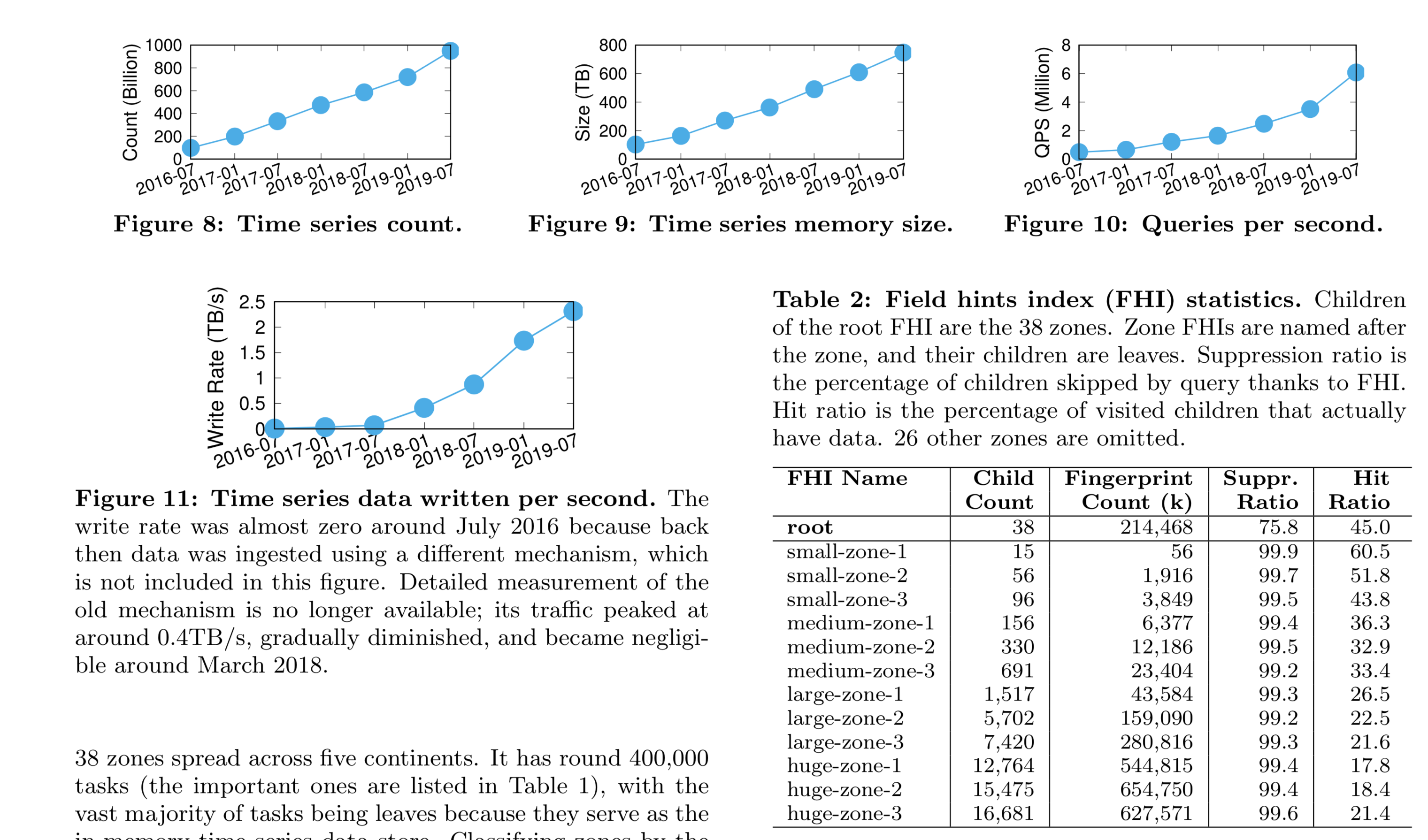
数据量很大,增速很快,节点很多,我很牛逼。..
相关工作
目前有许多开源时间序列数据库:Graphite,InfluxDB, OpenTSDB, Prometheus,和 tsdb 是最受欢迎的。它们将数据存储在辅助存储上(本地或分布式存储,如 HBase);辅助存储的使用使它们在关键监视时的可使用性降低。它们通过类似于 Monarch zone 的水平扩展来支持分布式部署,但是它们缺乏 Monarch 所提供的全局配置管理和查询聚合。
教训
- 时间序列键的字典序分片改进了摄取和查询的可伸缩性,使 Monarch zone 能够扩展到数以万计的叶子。
- 基于推的数据收集模式提高了系统的健壮性,同时简化了系统架构。
- 系统化的数据模型提高了健壮性和性能。
- 系统扩展是一个连续的过程。
总结
Monarch 可以在很大规模下高效可靠地运行,这是由于它将自治 zone 监控子系统通过全局配置和查询平面整合成一个连贯的整体。它采用了一种新颖的、类型丰富的关系时间序列数据模型,允许高效和可伸缩的数据存储,同时为数据分析提供了一种表达性查询语言。为了适应这种大规模,Monarch 在数据收集和查询执行方面使用了各种优化技术。对于数据收集,Monarch 服务器执行区域内负载平衡和收集聚合,以提高可靠性和效率。对于查询执行,Monarch 以分布式、分层的方式执行每个查询,执行积极的过滤和聚合下推以提高性能和吞吐量,并利用紧凑而强大的分布式索引进行高效的数据修剪。