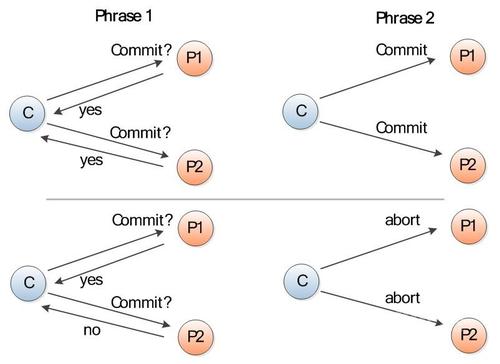
分布式事务简介 前言事务是作为单个逻辑工作单元执行的一系列操作。一个逻辑工作单元必须有四个属性,称为原子性、一致性、隔离性和持久性 (ACID) 属性。分布式事务则是尝试在多节点的环境下实现这些语义。 分布式事务涉及的知识内容较多,本篇博客并没有将其彻底整理清楚,只是简单记录了一下 6.824 课程所学。 内容对于分布式事务,可以将其细化为并发控制和原子提交两个子问题。前者是在说如何保证并发事务的串行隔离性,后者 2021-04-29 #分布式系统理论
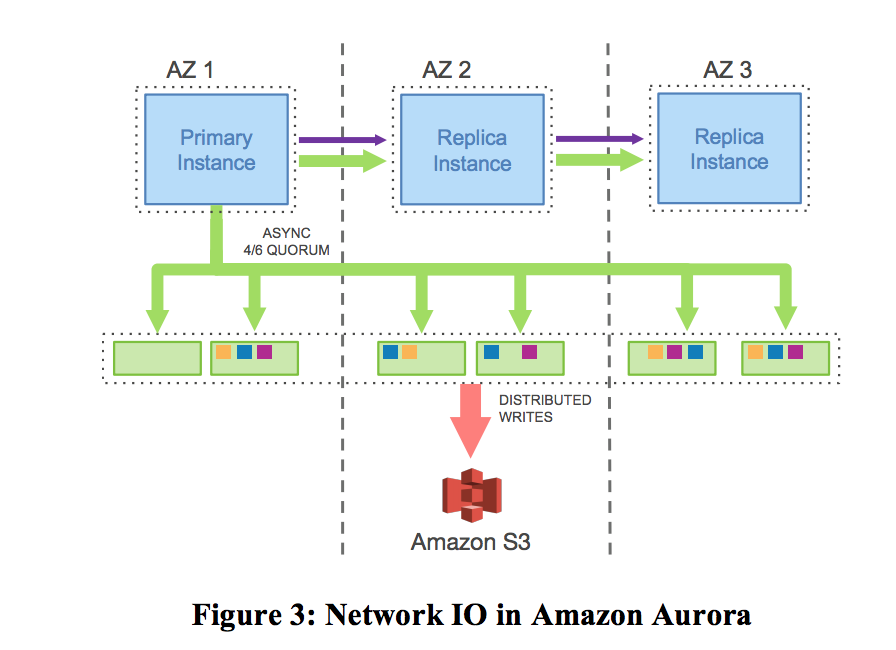
Aurora 论文阅读 相关背景Amazon Aurora 是一种与 MySQL 和 PostgreSQL 兼容的关系数据库,专为云而打造,既具有传统企业数据库的性能和可用性,又具有开源数据库的简单性和成本效益。 Amazon Aurora 的速度最高可以达到标准 MySQL 数据库的五倍、标准 PostgreSQL 数据库的三倍。它可以实现商用数据库的安全性、可用性和可靠性,而成本只有商用数据库的 1/10。 关于 A 2021-04-20 #分布式存储 #论文阅读
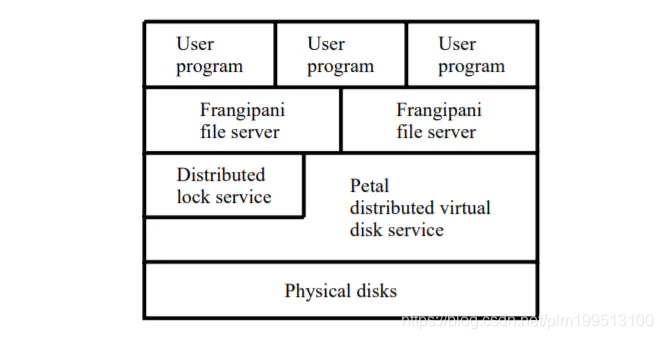
Frangipani 论文阅读 前言Frangipani 是一篇很古老的分布式存储论文,其设计思想在今天看来有很多已经过时了,但也有一定的参考意义。 该论文主要介绍了三个方面的工作: cache coherence distributed transactions distributed crash recovery 内容具体内容可以参考此 博客 和 6.824 课程的 讲义,后者较为详细。 有关后两个工作可以直接参考以上博 2021-04-10 #分布式存储 #论文阅读
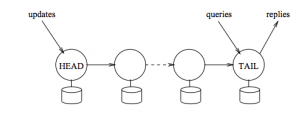
Chain Replication 论文阅读 前言对于 raft、paxos 这类共识算法,leader 节点需要将客户端的写请求编号并发送给所有 follower 以期望达成共识,这一定程度上导致写性能无法随节点个数线性增长,因为 leader 同步的数据量会随着节点数的增长而增长,从而使得主节点承载着更大的压力,往往成为了瓶颈。 2004 年,Chain Replication (之后简称 cr)方案被提出,其也能够保证多副本间的线性一致 2021-04-09 #分布式系统理论 #共识算法 #论文阅读
Zookeeper 论文阅读 前言Zookeeper 作为一个划时代的分布式协调服务,是 Hadoop 技术栈的重要组件。 本篇博客将讨论一些 zk 论文的知识点。 内容最近比较忙,没多少时间总结了,论文内容概要可以参考这篇 博客,更详细的细节可以参考这篇 博客。 讨论zk or etcd?同为分布式协调服务和元数据存储服务的产品:老大哥 zk 伴随 NoSQL 运动崛起,坐拥 hadoop 技术栈孤独求败;后起之秀 etcd 2021-04-08 #分布式系统理论 #共识算法 #论文阅读
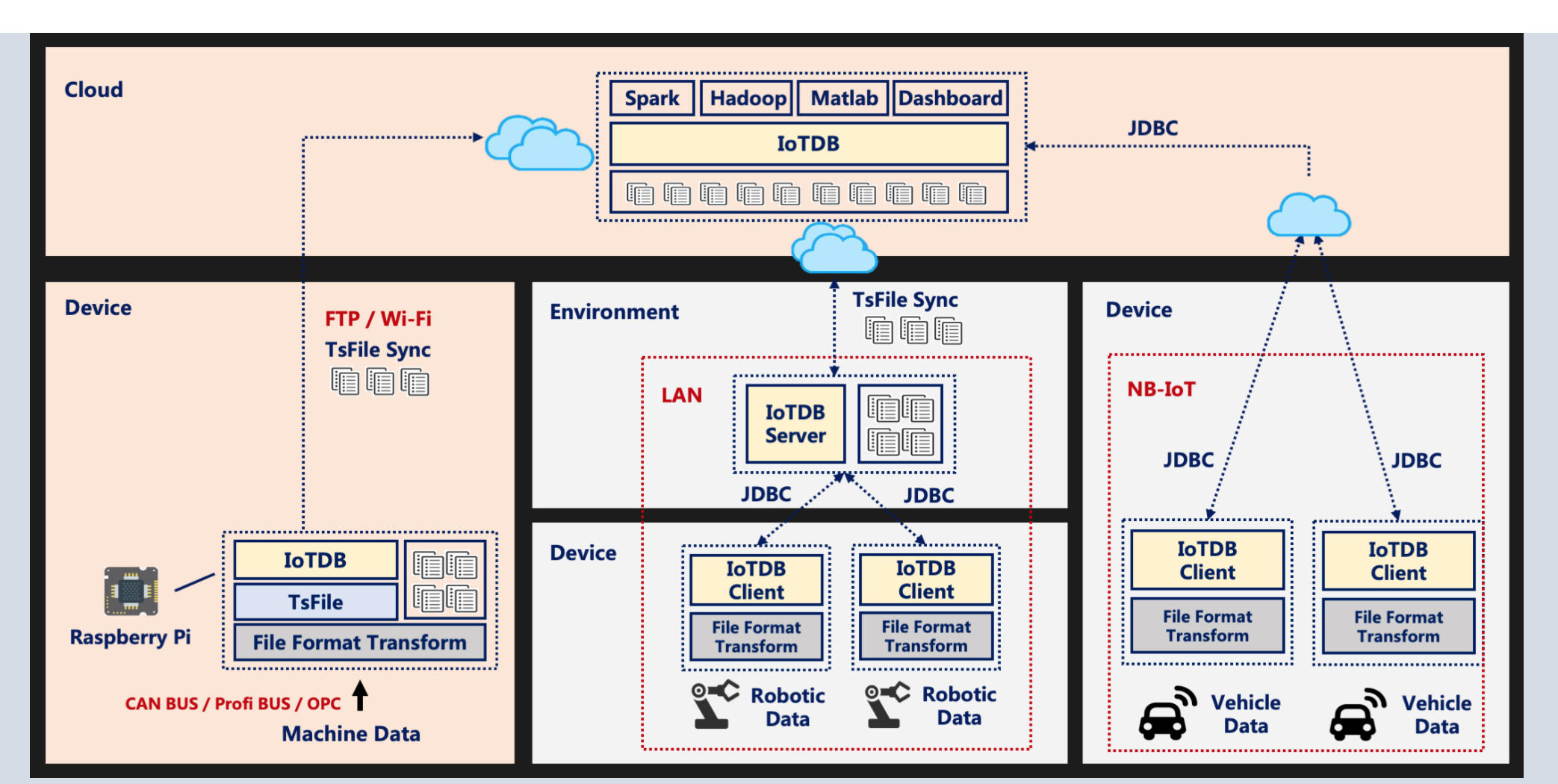
利用 IDEA 对分布式 IoTDB 进行调试 前言在单机数据库中,寻找 bug 相对较为简单。因为一旦可以复现 bug,那我们可以利用 IDE 在服务端打断点一步步执行并跟踪查看堆栈信息来判断代码出错的位置从而最终找到问题。 在分布式数据库中,找 bug 就变得相对困难了。一方面是因为分布式数据库较难利用 IDE 打断点,其往往通过打 log 的方式来记录错误情况,另一方面是一条客户端请求过来后往往伴随着若干并行和跨节点的 rpc,因此如果通 2021-04-07 #IoTDB #开发工具配置
一致性模型与共识算法 前言有关一致性模型和共识算法的一致性模型这两个问题,最近阅读了一些优质博客,学到了一些新的东西,同时感觉一些定义比较混乱,特此记录一下自己的理解。 一致性模型一致性问题是分布式领域最为基础也是最重要的问题,具体来历可以参考此 博客。 一般来讲,分布式系统中的一致性按照对一致性要求的不同,主要分为强一致性,弱一致性这两大类,前者是基于 safety 的概念,后者是基于 liveness 的概念。 强 2021-04-02 #分布式系统理论 #共识算法
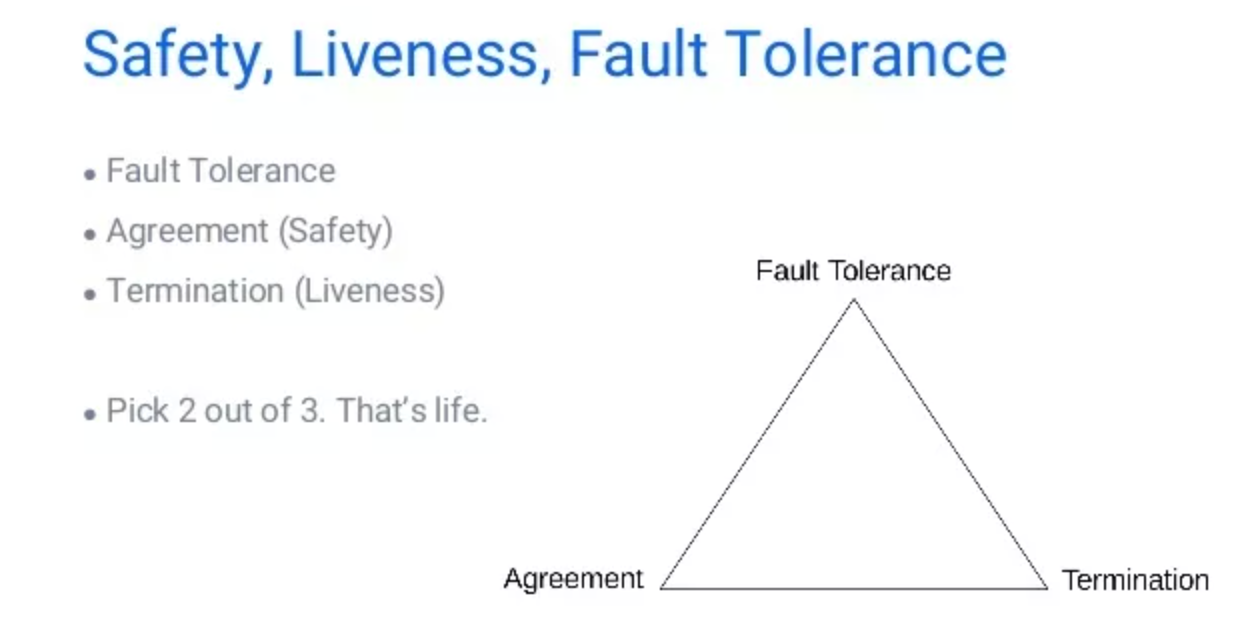
FLP 不可能定理介绍 前言FLP 不可能定理与 CAP,BASE 定理等一样,都是分布式系统的基本理论,因此我们有必要了解该理论。 本博客摘抄了此 博客 中对 FLP 不可能定理的部分描述。 定义1985 年,Fisher、Lynch、Paterson 三位科学家就发表了关于分布式一致性问题的不可能定理:在完全异步的分布式网络中,故障容错问题无法被解决。( We have shown that a natural an 2021-03-28 #分布式系统理论
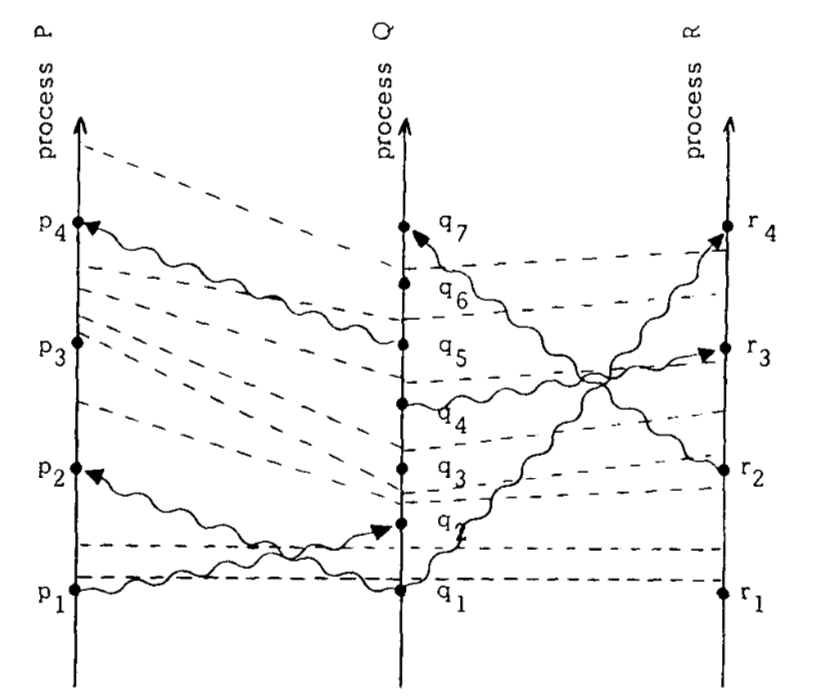
Time, Clocks, and the Ordering of Events in a Distributed System 论文阅读 背景这篇论文是 Leslie Lamport 于 1978 年发表的,并在 2007 年被选入 SOSP 的名人堂,被誉为第一篇真正的”分布式系统”论文,该论文曾一度成为计算机科学史上被引用最多的论文(截止 2022 年 3 月 6 日已达到 13071 次)。论文的作者 Lamport 享有分布式计算原理之父的美誉,并且因其对分布式系统研究作出的卓越贡献,于 2013 年被授予了图灵奖。 这篇论 2021-03-21 #分布式系统理论 #论文阅读
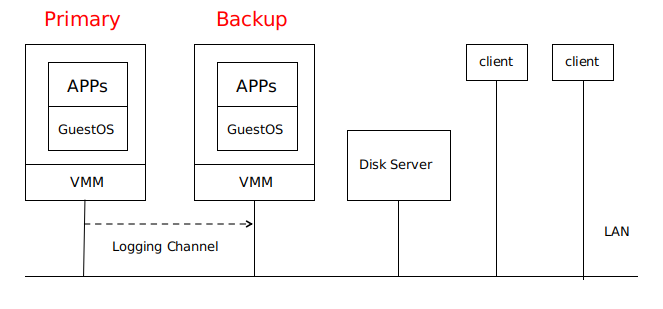
VM-FT 论文阅读 背景本论文主要介绍了一个用于提供容错虚拟机 (fault-tolerant virtual machine) 的企业级商业系统,该系统包含了两台位于不同物理机的虚拟机,其中一台为 primary,另一台为 backup,backup 备份了 primary 的所有执行。当 primary 出现故障时,backup 可以上线接管 primary 的工作,以此来提供容错。 内容论文内容可以参考此 博客 2021-03-13 #分布式系统理论 #论文阅读