数据库系统调优时有关操作系统的知识与测试监控
前言
在测试数据库的性能时,往往需要通过从网卡,CPU,内存,磁盘,代码等方面出发进行性能调优,这期间可能会纵向扩展机器以获得更好的性能。然而,在不同的硬件机器上测试时,有时的结果可能与预期相差较多,单从软件方面进行猜想可能并不靠谱。因此,需要对机器硬件进行一定的了解和对应的测试,这样就能够在调优分析时利用底层的硬件信息来支撑瓶颈分析,从而更可能做出正确的判断。本篇博客将从网卡,CPU,内存,磁盘出发来介绍一些基本的知识和性能评测方式,最后也会介绍 Linux 下常用的性能测试工具 sysbench 的使用和性能监控工具 glances 的使用。
网卡
介绍
网卡,即网络接口卡(network interface card),也叫 NIC 卡,是一种允许网络连接的计算机硬件设备。网卡应用广泛,市场上有许多不同种类,如 PCIE 网卡,服务器网卡。
基于不同的速度,网卡有 10Mbps,100Mbps, 10/100Mbps 自适应卡,1000Mbps、10Gbps、25Gbps、100Gbps 甚至更高速度的网卡。10Mbps、100Mbps 和 10/100Mbps 自适应网卡适用于小型局域网、家庭或办公室。1000Mbps 网卡可为快速以太网提供更高的带宽。10Gbps, 25Gbps, 100Gbps 网卡以及更高速度的网卡则受到大企业与数据中心的欢迎。
测试
Linux 下要想得知本机的网卡速率。可以查也可以测。
对于查,可以使用 ifconfig 找到网卡对应的设备名,然后使用 ethtool <device> 来查看对应网卡设备的额定速率。如下图所示: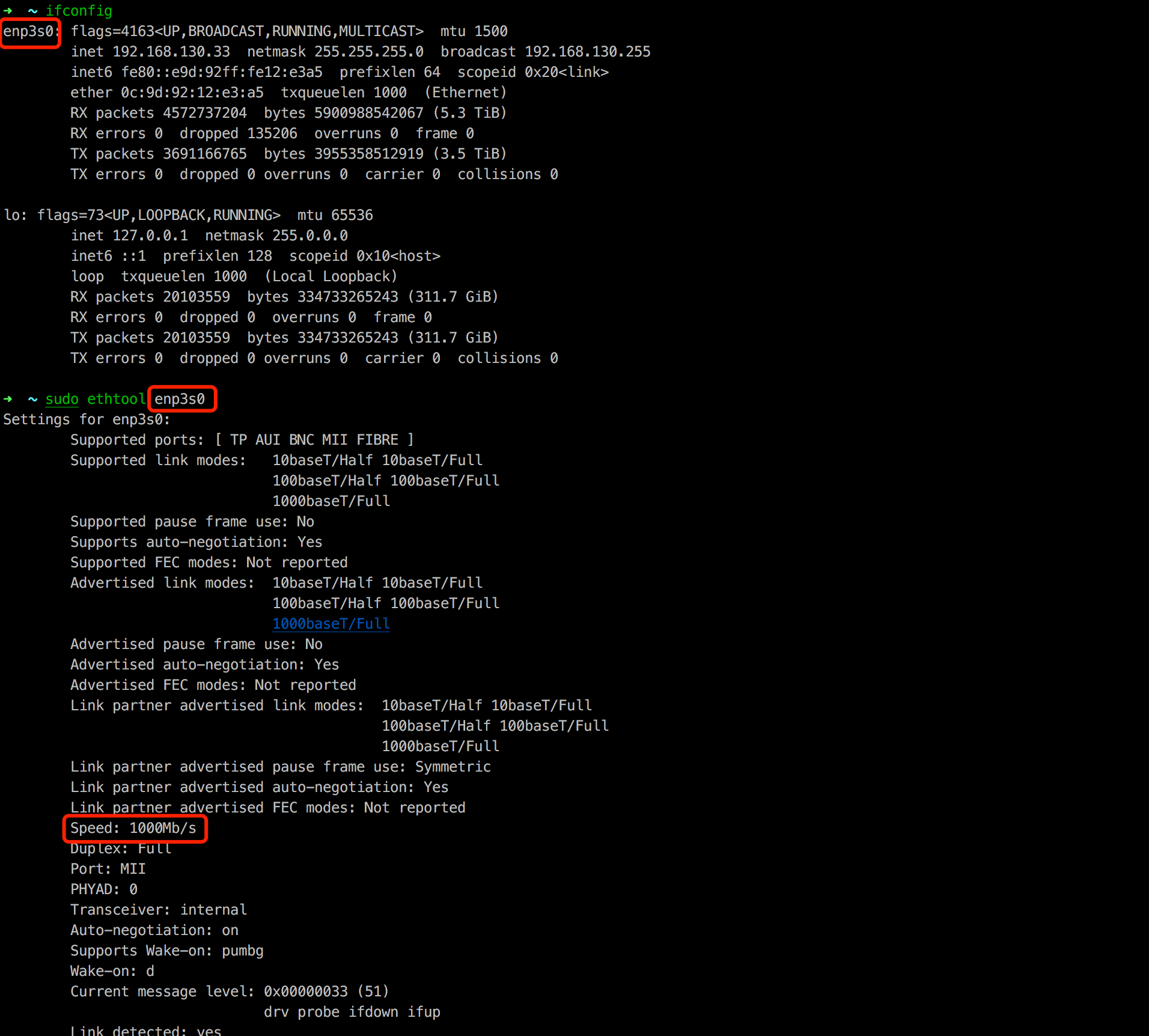
对于测,可以使用 iperf 或者 iperf3 来测量 tcp/udp 协议的吞吐量,进而测试网卡的性能。当然,由于连接参数(比如客户端连接数,包大小)的不同,测试时可能也跑不满理论带宽,因此对实际线上系统调优操作系统网络栈就是一个可以优化性能的方向。
iperf 和 iperf3 的具体使用方式可参考此 博客。
补充
市面上常说的千兆网卡速率是 1000Mbps,即 125MB/s;万兆网卡速率是 10000Mbps,即 1.22GB/s;十万兆网卡速率是 100000Mbps,即 12.21 GB/s。
CPU
介绍
中央处理器(CPU),是电子计算机的主要设备之一,电脑中的核心配件。其功能主要是解释计算机指令以及处理计算机软件中的数据。CPU 是计算机中负责读取指令,对指令译码并执行指令的核心部件。中央处理器主要包括两个部分,即控制器、运算器,其中还包括高速缓冲存储器及实现它们之间联系的数据、控制的总线。
CPU 的性能与以下衡量指标都有关系,具体可以参考此 博客。
- 主频(时钟频率)
- 外频(基准频率)
- 总线 (FSB) 频率
- CPU 的位和字长
- 倍频系数
- 缓存
- CPU 内核和 I/O 工作电压
- 制造工艺
- 指令集
- CPU 扩展指令集
- 架构(如 UMA 或者 NUMA 架构),具体可以参考此 博客。
测试
Linux 下想要得知本机有关 CPU 的信息,可以使用 lscpu 指令,其会显示 CPU 的型号,架构,主频大小,缓存大小,物理和逻辑核心数等等,如下图所示。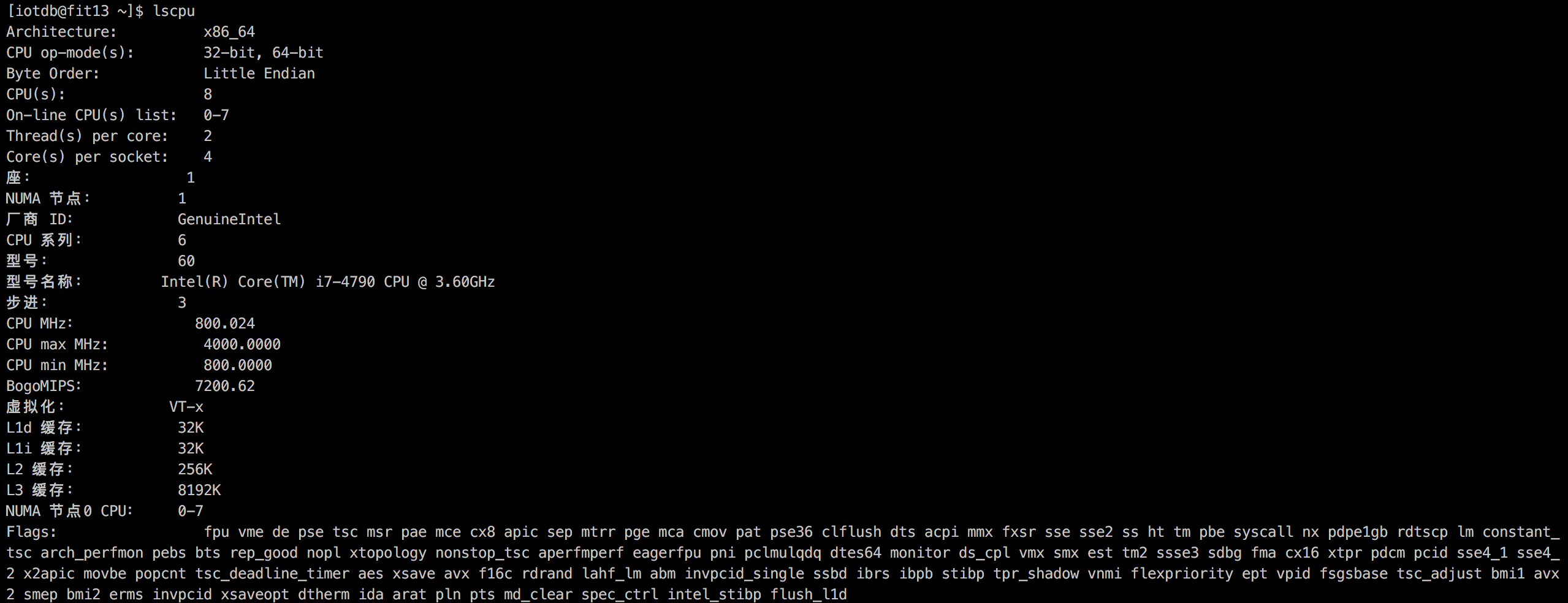
我们在知道 CPU 型号之后也可以去相关网站寻找更多有关此 cpu 的数据信息,比如 PassMark。
在系统运行过程中,可以评测 CPU 使用率的一个重要参考指标就是平均负载(load average)。如下图所示
平均负载是指单位时间内平均活跃进程数,包括可运行状态的进程数,以及不可中断状态的进程(如等待 IO, 等待硬件设备响应),其可以一定程度上反映一段时间内 CPU 的繁忙程度。但是平均负载高 CPU 的使用率不一定高,其主要表现如下,具体可参考此 博客。
- CPU 密集型进程,导致平均负载和 CPU 使用率比较高
- IO 密集型进程,等待 IO 会导致平均负载升高,但是 CPU 使用率不一定高
- 等待 CPU 的进程调度也会导致平均负载升高,此时 CPU 使用率也高
内存
介绍
内存是计算机中重要的部件之一,它是与 CPU 进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。内存也被称为内存储器,其作用是用于暂时存放 CPU 中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU 就会把需要运算的数据调到内存中进行运算,当运算完成后 CPU 再将结果传送出来,内存的运行也决定了计算机的稳定运行。内存是由内存芯片、电路板、金手指等部分组成的。
有关内存的发展,分类等详细信息可以参考 百度百科。
测试
Linux 可以通过 free -h 命令来查看本机的内存大小等等,如下图所示
具体参数含义为:
- total:服务器内存总大小:31G
- used:已经使用了多少内存:26G
- free:未被任何应用使用的真实空闲内存
- shared:被共享的物理内存
- buff/cache:缓冲、缓存区内存数,缓存在应用之中
- available:真正剩余的可被程序应用的内存数
- Swap:swap 分区的大小
free 和 available 的区别
free 是真正尚未被使用的物理内存数量。
available 是应用程序认为可用内存数量,available = free + buffer + cache (注:只是大概的计算方法)
Linux 为了提升读写性能,会消耗一部分内存资源缓存磁盘数据,对于内核来说,buffer 和 cache 其实都属于已经被使用的内存。但当应用程序申请内存时,如果 free 内存不够,内核就会回收 buffer 和 cache 的内存来满足应用程序的请求。
buff 和 cache 的区别
buffer 名为缓冲,cache 名为缓存。
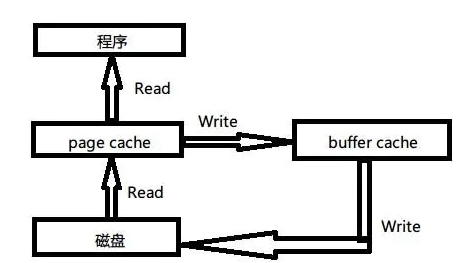
cache:文件系统层级的缓存,从磁盘里读取的内容是存储到这里,这样程序读取磁盘内容就会非常快,比如使用 grep 和 find 等命令查找内容和文件时,第一次会慢很多,再次执行就快好多倍,几乎是瞬间。但如上所说,如果对文件的更新不关心,就没必要清 cache,否则如果要实施同步,必须要把内存空间中的 cache 清楚下。
buffer:磁盘等块设备的缓冲,内存的这一部分是要写入到磁盘里的。这种情况需要注意,位于内存 buffer 中的数据不是即时写入磁盘,而是系统空闲或者 buffer 达到一定大小统一写到磁盘中,所以断电易失,为了防止数据丢失所以我们最好正常关机或者多执行几次 sync 命令,让位于 buffer 上的数据立刻写到磁盘里。
swap 是什么
在 Linux 下,swap 的作用类似 Windows 系统下的“虚拟内存”。当物理内存不足时,拿出部分硬盘空间当 swap 分区(虚拟成内存)使用,从而解决内存容量不足的情况。
swap 意思是交换,顾名思义,当某进程向 OS 请求内存发现不足时,OS 会把内存中暂时不用的数据交换出去,放在 swap 分区中,这个过程称为 swap out。当某进程又需要这些数据且 OS 发现还有空闲物理内存时,又会把 swap 分区中的数据交换回物理内存中,这个过程称为 swap in。
当然,swap 大小是有上限的,一旦 swap 使用完,操作系统会触发 OOM-Killer 机制,把消耗内存最多的进程 kill 掉以释放内存。
有关数据库与 swap 的关系以及 swap 的细节机制可以参考此 博客。
补充
CPU 的处理速度一般约为 10GB /s,常用的 DDR4 内存到 CPU 的吞吐一般约在 30GB/s ,所以内存的吞吐量往往不会成为瓶颈。当然,不同的语言对内存管理的方式不同,某些自动管理内存的语言(比如 Java)会出现 STW (Stop the world)的状况来调整内存空间,其会暂停所有用户线程,对性能影响很大。因此,基于业务负载和语言特性制定更好的 GC 策略能够更好地利用 CPU,从而进一步发掘内存的吞吐量。
磁盘
介绍
磁盘是指利用磁记录技术存储数据的存储器。 磁盘是计算机主要的存储介质,可以存储大量的二进制数据,并且断电后也能保持数据不丢失。 早期计算机使用的磁盘是软磁盘(Floppy Disk,简称软盘),如今常用的磁盘是硬磁盘(Hard disk,简称硬盘)。
目前常见的硬盘大可分为三类:机械硬盘(HDD)采用磁性碟片来存储,固态硬盘(SSD)采用闪存颗粒来存储,混合硬盘(HHD)是把磁性碟片和闪存集成到一起的一种硬盘。
HDD 和 SSD 的区别主要如下: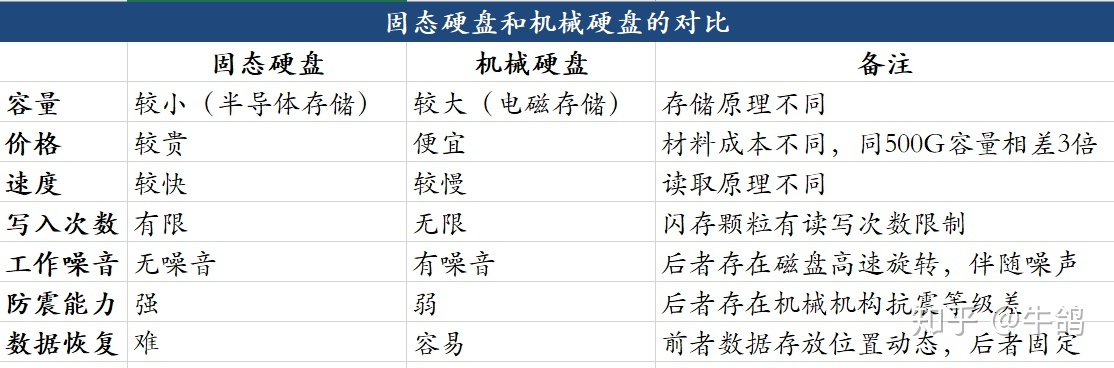
总体上来说,HDD 主要为 SATA 和 SAS 接口,目前家用类别的 HDD 多为 SATA 接口,SAS 接口则为企业级应用。SAS 可满足高性能、高可靠性的应用,SATA 则满足大容量、非关键业务的应用。
此外业界也常用多块 HDD 来组装磁盘阵列(比如 RAID 5 等等),从而提供更好的吞吐量和磁盘级别的容错,具体细节可参考此 博客。
至于固态硬盘,其常见接口和速率如下图所示:
测试
Linux 可以通过 df -hT 命令来查看本机磁盘设备挂载的磁盘目录,文件系统以及容量等等,如下图所示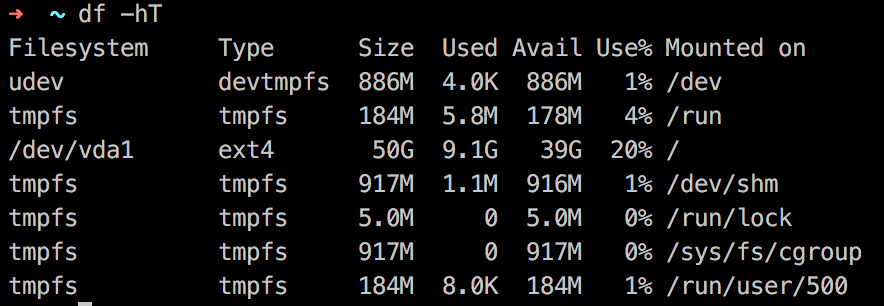
此外还可以通过 fdisk -l <device> 命令来查看磁盘设备的源信息,比如可以通过此命令来查看磁盘是 SSD 还是 HDD,如果有”heads”(磁头),”track”(磁道)和”cylinders”(柱面)等等则就是 HDD,否则则是 SSD。如下图所示就是 SSD。
1 | |
如果想要测试磁盘的 IOPS 或者吞吐量,则可以使用一些磁盘测试工具进行测试,如 smartctl,sysbench 等等,后文会介绍如何使用 sysbench 测量磁盘性能。
有关文件系统的区别(xfs or ext4),可以参考此 博客。至于具体性能,由于上层应用不同,其在不同文件系统上的表现也不同,建议实际测试一下才能知道真实场景下哪个更优秀,一般情况下选择 xfs 就够用了。
有关磁盘 IO 的理论细节可以参考美团技术团队的 博客,十分详细。
补充
- 吞吐量
- 对于顺序读写,普通的 HDD 的吞吐量一般在 100 MB/s 左右,某些企业级 HDD 能够达到 200 MB/s 左右。对于随机读写,HDD 的性能表现很差,一般是几十兆每秒。
- 对于顺序读写,普通的 SSD 的吞吐量一般在 300~500MB/s 左右,某些企业级 SSD(例如适配 PCIE 3.0 接口)甚至能够达到 2GB/s。对于随机读写,SSD 的性能相比顺序读写下降较少,一般也是几百兆每秒。
- 时延
- 图胜千言
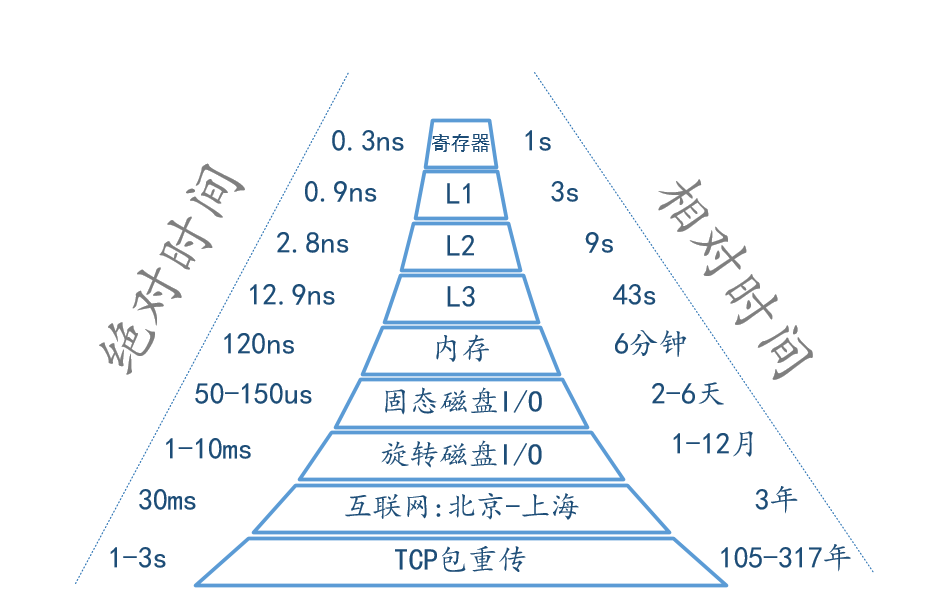
- 图胜千言
sysbench 测试工具
sysbench 是一款开源的多线程性能测试工具,可以执行 CPU/内存/线程/IO/数据库等方面的性能测试。
sysbench 支持以下几种测试模式 :
- CPU 运算性能
- 内存分配及传输速度
- 磁盘 IO 性能
- POSIX 线程性能
- 互斥锁性能测试
- 数据库性能 (OLTP 基准测试)。目前 sysbench 主要支持 MySQL,PostgreSQL 等几种数据库。
sysbench 的安装建议直接参考 官方 repo,最详细最不踩坑。具体负载参数可以用 sysbench --help 查看也可以参考官方 repo,当然也可以查看此 博客 和此 博客。
以下列出几种测试实例:
CPU 运算性能
单核性能
1 | |
多核性能
1 | |
内存吞吐量
1 | |
磁盘性能
顺序读写
1 | |
乱序读写
1 | |
POSIX 线程性能
1 | |
互斥锁性能
1 | |
glances 监控工具
glances 是一个基于 python 语言开发,可以为 Linux 或者 Unix 性能提供监视和分析性能数据的功能。glances 在用户的终端上显示重要的系统信息,并动态的进行更新,让管理员实时掌握系统资源的使用情况,而动态监控并不会消耗大量的系统资源,比如 CPU 资源,通常消耗小于 2%,glances 默认每两秒更新一次数据。同时 glances 还可以将监控数据导出到文件中,便于以后使用其他可视化工具(例如 grafana)对报告进行分析和图形绘制。
glances 可以分析系统的:
- CPU 使用率
- 内存使用率
- 内核统计信息和运行队列信息
- 磁盘 I/O 速度、传输和读/写比率
- 磁盘适配器
- 网络 I/O 速度、传输和读/写比率
- 页面监控
- 进程监控-消耗资源最多的进程
- 计算机信息和系统资源
当然,也可以用一些专业的服务器监控平台,其包含的信息可能更详细。但是 glances 的一个重要优点是开箱即用,不用专门部署,具体安装方式和参数可参考 官方 repo,使用示例如下图所示: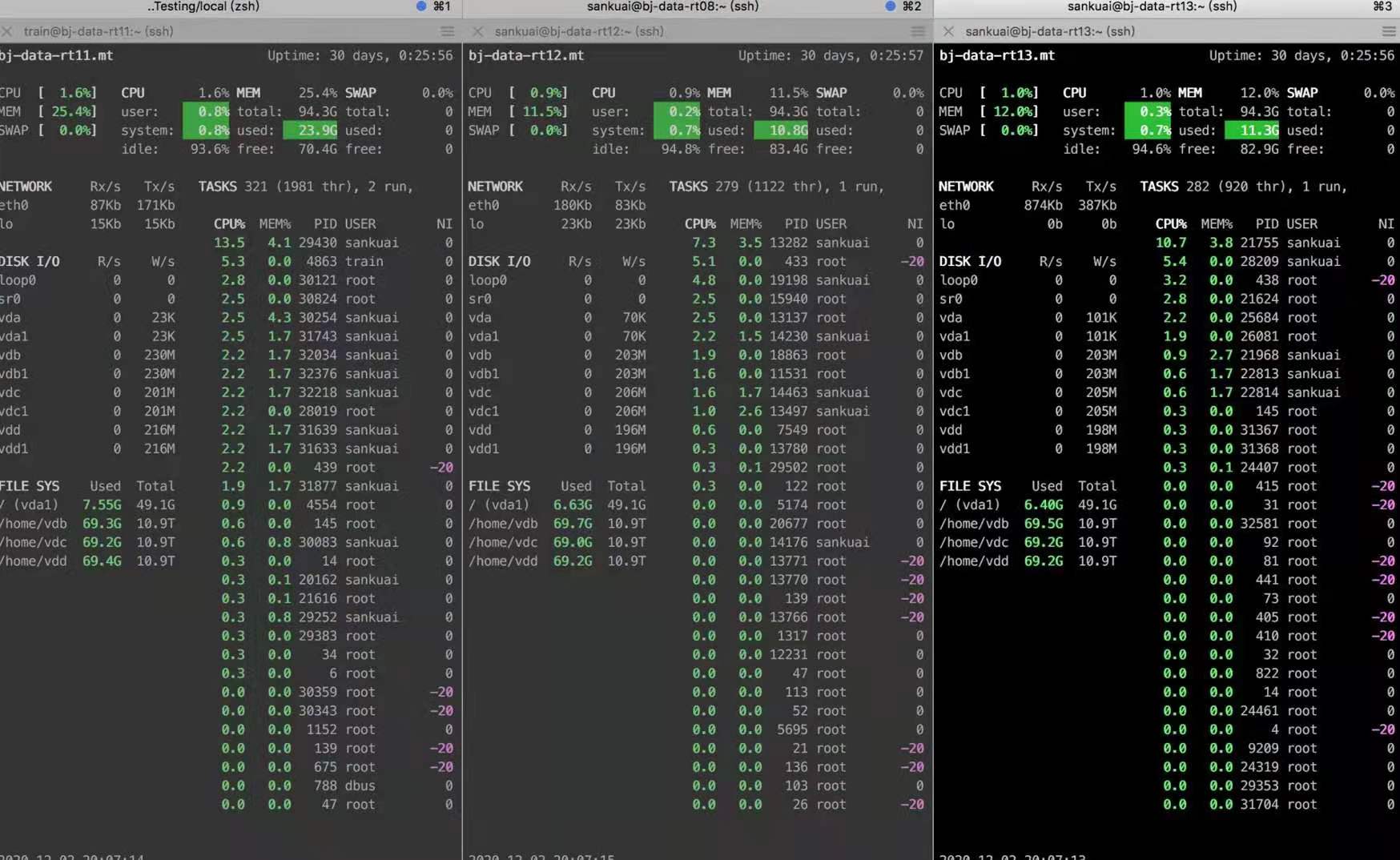
总结
本篇博客简单介绍了网卡,CPU,内存和磁盘的一些理论知识和我个人认为写的比较好的博客,最后介绍了 Linux 下常用的性能测试工具 sysbench 的使用和性能监控工具 glances 的使用。
本篇博客涉及了较多硬件和操作系统的知识,其实这些都可以挖的更深,由于水平和时间有限,暂不继续深挖,希望看完本博客之后能对大家的系统调优有所帮助。