MaxCompute 跨域流量优化论文阅读
相关背景
随着大数据技术的长足发展,大公司和云供应商在全球创建了数十个地理上分散的数据中心(分布式数据中心)。一个典型的数据中心可包含数万台计算机,这些数据中心为许多大规模的 IT 企业提供了计算和存储能力。在管理这种大规模、分布式数据中心的过程中,减少跨数据中心流量是提高整体性能的核心瓶颈之一。
要解决的问题
MaxCompute 是阿里巴巴的大型数据管理和分析平台,管理着数十个分布式数据中心。每个数据中心都包含成千上万台服务器,并且通过广域网(WAN)相互连接。这些数据中心每天新增 500 万张数据表,并为阿里巴巴的各种业务应用程序(例如淘宝,天猫等)执行多达 700 万次的分析工作。 MaxCompute 中的作业每天生产和使用大量数据,形成了复杂的数据依赖关系。尽管这些依赖关系大多都在本地数据中心内部,随着业务的增长,来自非本地数据中心的依赖关系也在迅速增加。由于跨数据中心的依赖关系,使得 MaxCompute 中大约产生了数百 PB 通过广域网传输的数据。
日益增长的跨数据中心传输需求带来了多个方面的问题。WAN 的带宽约为 Tbps,而数据中心内网络的聚合带宽则大得多;另外,WAN 延迟是数据中心内部网络延迟的 10-100 倍。除网速之外, WAN 的成本也十分昂贵。如今,跨 DC 的带宽已成为一种非常宝贵的资源,同时也是 MaxCompute 运营的性能瓶颈。在优化之前,WAN 的成本占 MaxCompute 总体运营成本的很大一部分——考虑到 MaxCompute 的日常运营规模庞大,这是巨大的财务负担。正因如此,减少跨地区带宽的使用已经逐渐成为阿里巴巴数据中心业务的一大挑战。
解决方法
MaxCompute 研发了一个跨域流量优化系统 Yugong(意译:愚公),其通过与 MaxCompute 在大范围生产环境下进行协同运算,极大地降低了由项目迁移(project migration)、副本拷贝(table replication)以及计算调度(job outsourcing)所产生的大量跨数据中心带宽流量,由此有效地降低了运营成本。
业务数据分析
MaxCompute 业务场景中的数据有 project,table 和 partition 三个级别。project 可以类比于关系数据库中 database 的概念,通常是业务功能上相近的表的集合。table 是用户数据的某一张关系型数据表,partition 是 table 根据时间进行分区的子表,通常每张表每天会产生一个分区。
其特性如下:
- project,job 和 table 遵循幂律分布。作业和表之间的跨 DC 依赖关系呈现出长尾现象。相对较少的热表和大型作业在跨 DC 依赖关系中占很大一部分。
- 不论是数据大小还是分区数量,大部分作业的输入都要比输出大得多。
- 连续几天创建的表分区具有相似的大小。一个分区的大小比它的表的大小小数百倍。大多数作业是周期性的,连续几天的表访问模式是稳定的。
- 最近的表分区被更频繁地访问,其他作业对其依赖的数量随着访问偏移量的增加呈指数级下降。
- 一些表经常被远程 DC 中的作业读取,因此复制这些表可以节省跨 DC 的带宽。另外,调度一些作业在它们的非默认 DC 中运行可以减少跨 DC 带宽的使用。
- DC 具有动态且不可预测的资源利用模式,在同一时间段内可能存在不同的资源瓶颈。
模型概述
下图为下文常用到的一些符号及其解释。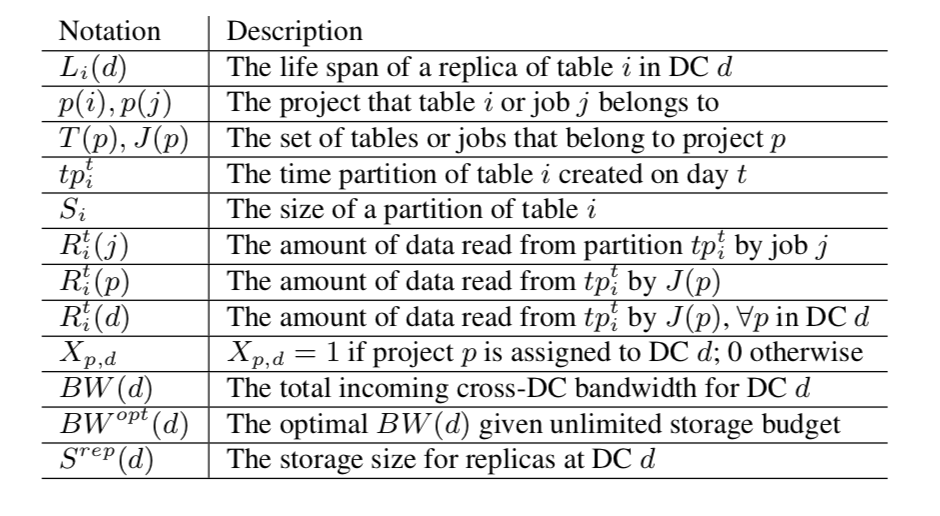
在下文中,我们将尝试最小化一天中跨集群的总带宽使用。我们假设连接每对 DC 的广域网具有相同的单位成本。我们假设来自同一个分时表的所有分区的大小是相同的,作业每天重复出现,并且它们的表访问模式连续几天都是相同的。因此,我们只需要考虑一天内运行的作业。我们使用“所有作业”来表示“在当前日期 tcur 上运行的所有作业”。表访问模式仅由在 tcur 上运行的作业生成。作业和访问模式实际上在几天内缓慢变化,我们将在 table replication 节再介绍如何应用于生产环境。


该分析模型在计算上是棘手的,因为它是(| T | + | P |)×| DC | 的整数规划问题,其中 | T | 是表的总数,| P | 是项目总数,并且 | DC | 是数据中心的数量。
根据前文讲述的业务数据分析,我们可以利用我们的发现来简化问题。由于作业倾向于读取最近的分区,并且它们对分区的依赖关系的大小随访问偏移的增加而呈指数下降,因此有理由首先假设我们有足够/无限的项目复制存储大小迁移,然后使用启发式方法确定固定存储预算下的寿命。这种简化极大地降低了模型的复杂性,因为我们实际上删除了存储空间的限制。
通过这种简化,我们可以将问题分解为两个问题:
- 一个项目迁移问题,该问题首先在假定复制存储预算不受限制的情况下找到项目放置计划 P,
- 一个表复制问题,该问题在给定项目放置计划 P 后生成表复制计划 R,同时满足存储空间的约束。这种分离对于我们的生产环境也是很自然的,因为由于较高的迁移成本,项目放置/迁移不能频繁执行,而表复制计划可以更频繁地更新。
项目迁移
在简化的项目迁移模型中,我们删除了存储空间约束。根据给定的项目布置计划,可以通过以下方法获得 DC d 的最小跨 DC 带宽成本 BWopt(d):
- 从表 i 的 DC 中远程读取每个表 i 的所有必需数据。 如果从表 i 读取的数据量小于其分区的总大小;
- 否则将表 i 的所有分区存储在 DC d 中,并每天复制其最新分区。
因此,BWopt(d) 由以下公式 12 给出:
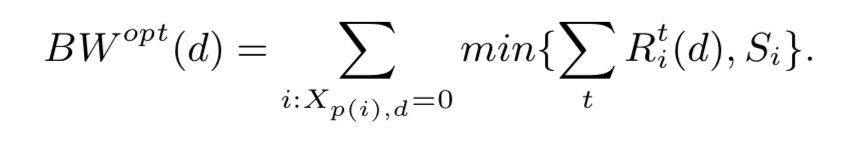
上面关于 Rit(d)沿时间维度 t 的总和有助于消除为每个时间分区共同考虑复制策略的复杂性。我们的目标是找到一个项目放置计划 P,以使总 BWopt(d) 最小化:
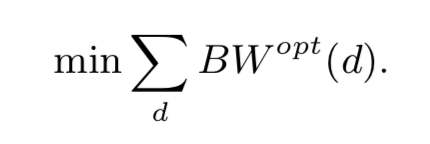
即使进行了这种简化,项目和表的数量仍然很大,因为我们有成千上万个项目和数百万个表。我们利用跨 DC 依赖关系的幂律分布来进一步减小问题的大小,即少量表构成了大部分跨 DC 的依赖。因此,我们仅考虑项目迁移模型中具有最大依赖项大小的少数表。此外,在解决问题时,我们还发现,对少量项目进行迁移可以显着改善我们当前的项目布局,而随着影响力较大的项目已经放置在合适的 DC 中,随着进一步的迁移,这种改进会迅速降低。
我们的项目迁移策略还可用于解决新的项目放置问题。我们首先根据 DC 的负载将新项目放置在 DC 中,然后通过将 MigCount 设置为新项目的数量来解决项目迁移问题。
数据拷贝
给定上一节计算出的项目放置计划 P,我们然后找到一个表复制计划(即,找到每个 DC d 中每个表 i 的寿命 Li(d))以最小化跨 DC 带宽的总成本, 同时满足存储空间约束。 我们首先假设连续两天的表访问模式相同,针对不同 DC 中所有表的寿命设计一种启发式方法。然后我们删除该假设,并考虑动态维护表副本的生命周期,因为表访问模式实际上随着时间逐渐变化。 请注意,我们的解决方案中的表访问矩阵 Rit(d)仅包含不属于 DC d 中项目的表,即 Xp(i),d = 0,因为我们仅关心远程读取。为简单起见,我们在随后的讨论中省略了 DC d。
DP 解法
我们可以通过 DP 算法来获得给定复制存储大小和给定项目放置计划下的最佳表复制计划。 我们将 dp(i,s)表示为可以通过考虑复制存储大小约束 s 下的前 i 个表获得的最小跨 DC 带宽成本,定义表 i 的寿命是 Li。 用于存储表 i 的副本的存储大小为 Li×Si。 则读取表 i 的分区所产生的跨 DC 带宽成本为:
- 寿命未涵盖的部分的所有远程读取的总成本和。
- 寿命涵盖部分的复制成本。
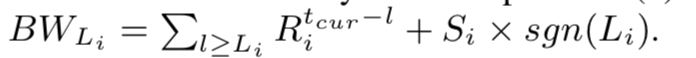
因此 dp 算法的转移函数可以定义如下:
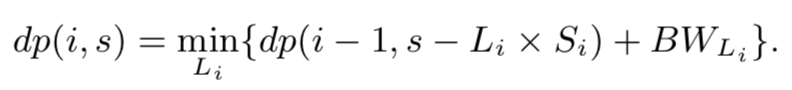
存储预算为 s 的前 i 个表的最小跨 DC 带宽成本是枚举表 i 的所有可能寿命 Li 并取其中的最小值。
DP 算法的时间复杂度为 O(| T | | L | | storage |),其中 | T | 是表的数量(从几万到几百万),| L | 是每个表的可能寿命(通常为几百个),并且 | storage | 是 DP 公式中使用的复制存储单位的数量(大约十亿:大约是存储总预算(PB 级别)除以分区大小(MB 级别))。因此,DP 算法太昂贵了。
贪心解法
作为 DP 算法的替代方法,我们提出了一种有效的贪心算法。 在每一步中,算法都会将表 i 的当前寿命 Li 最多提高 k 个单位,这由边际增益贪心地确定,其定义(公式 15)如下:
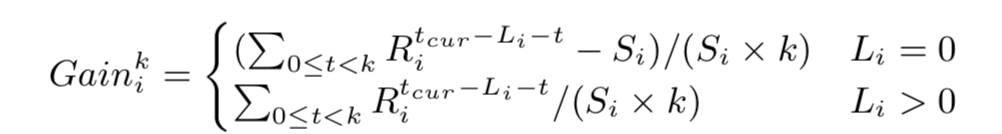
直观地,分子是通过将 Li 提前 k 个单位可以节省的跨 DC 带宽总成本,而分母是存储额外的 k 个分区副本所需的存储空间。 如果 Gainik > 0,则意味着复制多余的 k 个分区可以进一步节省跨 DC 带宽。 请注意,当 Li = 0 时,我们需要从 Gainik 中减去 Si,因为我们需要使用跨 DC 带宽来复制分区 tpitcur,而对于 Li > 0,此成本 i 已经被 Li = 0 时所覆盖。
下图就是提出的贪心算法(算法 1)。 该算法首先初始化最大优先队列(maxPQ),以在所有表 i 的 Li = 0 时,如果 Gainik > 0,则保留所有可能的 Gaini。 然后,它将继续使 maxPQ 的最大增益出队,直到队列变空。 假设对于某个表 i,当前的最大增益为 Gainik’ ,如果存储预算仍允许其他 k’ 个副本,则将 Li 提前 k’ 个单位。”li = Li“ 条件是确保对于所有基于当前 Li 计算的 Gainik’,其中 0 ≤ k’< k,i 只能使用一个 k’ 来推进 Li。 在 Li 前进之后,将基于更新的 Li 来计算新增益 Gainik 并将其放入 maxPQ 中。

以上算法的时间复杂度为 O(k | T || L | log(k | T || L |)),由于 k 仅为数百个数量级,因此它的耗费时间大大小于 DP 算法。 此外,我们证明了贪心算法在给定足够的存储预算的情况下可以获得最佳带宽成本,如下所示。
定理 1:
将 STOrep 设置为达到等式 12 中的最佳带宽成本且 k 为最大寿命时使用的实际复制存储大小,算法 1 计算出的表复制计划能够给出与等式 12 相同的最佳带宽成本。
当达到公式 12 中的最佳带宽成本时,令 Liopt 为表 i 的寿命。 考虑算法 1 中表 i 的当前寿命 Li。我们有 Li < Liopt,并且将 Li 提升到 Liopt 的收益高于任何 l > Liopt 的收益,因为 Liopt 需要较少的存储空间,并且产生相同的读取次数( 请注意,在给定无限复制存储预算的情况下,因此只要从该分区的远程读取大小大于该分区的大小,就可以复制任何分区,如公式 12 所示)因此,如果我们的存储预算与等式 12 中用于获得最佳带宽成本的实际复制存储大小相同,则在某一点上表 i 将从 maxPQ 出队,并得到 Li 到 Lopt 的增益。 之后进一步提升 Li 的增益将变为 0,从而不会再入队。
动态维护
我们的贪心解决方案目前仅考虑固定的表访问模式。实际上,由于业务的增长和偶尔的临时工作,表访问模式实际上在随时间变化(尽管缓慢)。 因此,我们需要定期更新表复制计划。 假设计划每 δ 天更新一次。 现在的问题是,给定当前的复制计划 R,我们需要找到一个新的复制计划 R’,以便它可以用作接下来 δ 天的良好复制计划,以及最小化从 R 至 R’ 状态迁移的带宽消耗。 作为过渡成本的示例,假设表 i 的寿命是 R 中的 Li 和 R’ 中的 L’i,并且 Li < L’i,这意味着 R’ 对表 i 的覆盖范围比 R 多。 为了将较旧的分区从(tcur -L’i)复制到(tcur -Li),需要额外的带宽以保证从 R 过渡到 R’。
更新复制计划的最简单方法是每 δ 天重新运行一次算法 1,但这可能会导致相当大的过渡成本。考虑到复制较旧分区所产生的成本,我们建议对增益函数进行简单的修改。 设 Ii,t 为指标,如果 tpit 被 R 覆盖,则 Ii,t = 1,否则,Ii,t = 0。 我们将 Gi,t 定义为如果新计划涵盖 tpit 可以节省的带宽量。
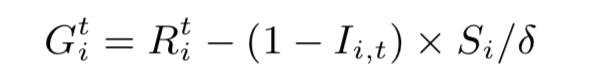
直觉是,如果分区 tpit 不在复制计划中,则将其包括在计划中需要付出一定的代价,该损失等于在 δ 天内复制 tpit 的摊余带宽成本。也就是说,除非收益很大,否则我们不鼓励复制较旧的分区。通过在公式 15 中用 Git 代替 Rit,我们获得了一个新的增益函数:
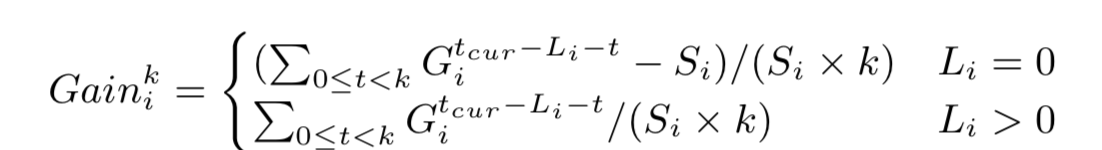
除了使用新的增益函数外,我们还取了前 δ 天的表访问矩阵 Rit 的平均值以减少表访问模式中振荡的影响。
计算调度
计算调度,即将作业调度到非默认 DC 进行处理,该 DC 可能包含作业所需的全部或部分输入表。当输入数据较大时,计算调度可以减少跨 DC 的带宽使用。这也可以用于在分布式控制系统之间平衡负载和各种资源(例如,中央处理器、内存、磁盘、网络等)的利用率来提高整体资源利用率(从而节省生产成本)。
对比前两种离线方式,因为调度决策需要考虑分布式控制系统的负载和资源利用率,所以计算调度需要在线解决方案。此外我们还需要考虑远程分布式控制系统是否有空闲资源来运行该作业,以及预期的作业完成时间(包括远程分布式控制系统中的等待时间)是否短于作业的默认 DC 时间。因此,我们设计了一个简单的评分函数来决定是否将工作 j 调度给 DC d:
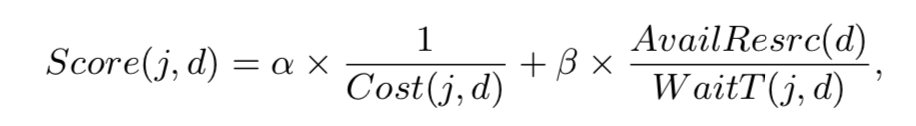
其中 Cost(j,d)和 WaitT(j,d)是跨 DC 带宽的总成本以及如果将工作 j 外包给 DC d 的估计等待时间,而 AvailResrc(d)是 DC d 中的可用资源量。请注意,Cost(j,d)包括将所有必要的信息/数据发送到 DC d 以执行作业,并将作业输出传回默认的 DC。我们仔细调整了参数 α 和 β,以降低跨 DC 带宽的成本。
效果评估
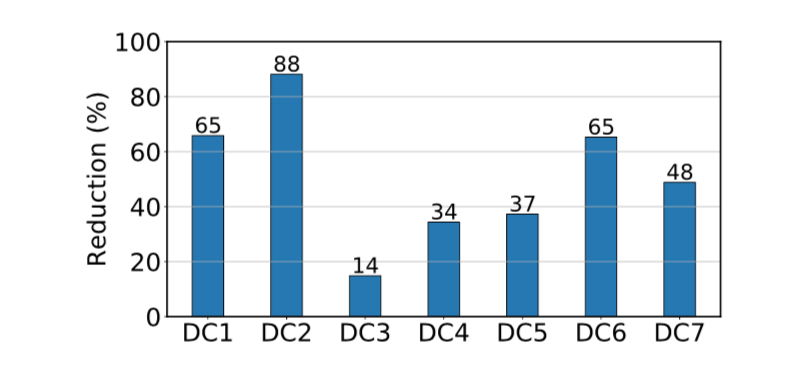
首先报告愚公在阿里巴巴投入生产的整体表现。下图显示了在典型的一天中每个 DC 传入的跨 DC 带宽使用量的减少。 愚公将不同 DC 的跨 DC 带宽使用率从 14% 降低到 88% 。 DC2 具有最大的减少量,因为它具有最大的远程依赖性。当天,愚公总共减少了总带宽使用量的 76%。
创新之处
- 根据实际业务的工作流来将如何减少跨域流量的难题解耦为三个容易分开解决的子问题。
- 在数据拷贝部分进行了系统的分析与设计并就此过程中的取舍进行了讨论。
不足之处
- 很多简化部分很直接,这可能是容易想到的最直接最容易实现的方法,但也可能还有一定的可优化空间。
- 如果能够将存储空间成本和带宽成本量化似乎模型会更准确。
相关工作
地理分布式调度
最近有关分析工作负载的地理分布调度工作仅考虑了少量作业,并假设数据在地理分布的 DC 之间进行了分区,并且一项任务可以在多个 DC 中运行。 Iridium 优化了任务调度和数据放置,以实现分析查询的低延迟。 Geode 和 WANalytics 使查询计划了解 WAN,并为整个 DC 的数据分析提供以网络为中心的优化。 Clarinet 通过考虑网络带宽,任务位置,网络传输调度和多个并发查询,提出了一种支持 WAN 的查询优化器。Tetrium 考虑了地理分布的 DC 中用于任务放置和作业调度的计算和网络资源。Pixida 应用图分区来最大程度地减少数据分析作业中的跨 DC 任务依赖性。Hung 提出了地理分布的作业调度算法,以最大程度地减少整体作业的运行时间,但并未考虑 DC 之间的 WAN 带宽使用情况。 Bohr 利用地理分布的 OLAP 数据立方体展示了不同 DC 中数据之间的相似性。 Lube 实时检测和缓解地理分布数据分析查询中的瓶颈。
还有其他使数据流分析,分布式机器学习和图形分析可感知 WAN 的工作。 JetStream 提出了显式的编程模型,以减少分析流数据集所需的带宽。对于机器学习工作负载,Gaia 和 GDML 开发了地理分布式解决方案,以有效利用稀缺的 WAN 带宽,同时保留 ML 算法的正确性。 Monarch 和 ASAP 提出了一种地理分布图模式挖掘的近似解决方案。
云原生数据仓库
Google BigQuery,Amazon Redshift,Microsoft Azure Cosmos DB 和 Alibaba MaxCompute 是大型数据仓库产品。 MaxCompute 中的 “project” 概念对应于 Redshift 中的 “database” 和 BigQuery 中的 “project”。 尽管愚公在此工作中主要是用作 MaxCompute 的插件构建的,但类似的想法也可以应用于其他地理分布的数据仓库平台。
缓存和打包
从 CPU 高速缓存,内存高速缓存到应用程序级高速缓存,高速缓存管理是在不同级别的计算机体系结构上经过充分研究的主题。 Memcached 和 Redis 是高度可用的分布式键值存储,可在磁盘上提供内存缓存。EC-Cache 和 SP-Cache 为数据密集型群集和对象存储提供了内存中缓存。Piccolo,Spark,PACMan 和 Tachyon 结合了用于集群计算框架的内存缓存。在这项工作中,我们使用磁盘存储作为远程分区的缓存,以减少跨 DC 带宽。 表复制问题是背包问题的变体,项目放置问题是装箱问题的变体。 Tetris 将多资源分配问题与多维 bin 打包问题进行了类比,以进行任务调度。