一致性模型与共识算法
前言
有关一致性模型和共识算法的一致性模型这两个问题,最近阅读了一些优质博客,学到了一些新的东西,同时感觉一些定义比较混乱,特此记录一下自己的理解。
一致性模型
一致性问题是分布式领域最为基础也是最重要的问题,具体来历可以参考此 博客。
一般来讲,分布式系统中的一致性按照对一致性要求的不同,主要分为强一致性,弱一致性这两大类,前者是基于 safety 的概念,后者是基于 liveness 的概念。
强一致性
强一致性包含线性一致性和顺序一致性,其中前者对 safety 的约束更强,也是分布式系统中能保证的最好的一致性。
顺序一致性
如果一个并发执行过程所包含的所有读写操作能够重排成一个全局线性有序的序列,并且这个序列满足以下两个条件,那么这个并发执行过程就是满足顺序一致性的:
- 条件 I:重排后的序列中每一个读操作返回的值,必须等于前面对同一个数据对象的最近一次写操作所写入的值。
- 条件 II:原来每个进程中各个操作的执行先后顺序,在这个重排后的序列中必须保持一致。
线性一致性
线性一致性的定义,与顺序一致性非常相似,也是试图把所有读写操作重排成一个全局线性有序的序列,但除了满足前面的条件 I 和条件 II 之外,还要同时满足一个条件:
- 条件 III:不同进程的操作,如果在时间上不重叠,那么它们的执行先后顺序,在这个重排后的序列中必须保持一致。
区别
- 它们都试图让系统“表现得像只有一个副本”一样。
- 它们都保证了程序执行顺序不会被打乱。体现在条件 II 对于进程内各个操作的排序保持上。
- 线性一致性考虑了时间先后顺序,而顺序一致性没有。
- 满足线性一致性的执行过程,肯定都满足顺序一致性;反之不一定。
- 线性一致性隐含了时效性保证(recency guarantee)。它保证我们总是能读到数据最新的值。
- 在顺序一致性中,我们有可能读到旧版本的数据。
弱一致性
弱一致性是指系统在数据成功写入之后,不承诺立即可以读到最新写入的值,也不会具体承诺多久读到,但是会尽可能保证在某个时间级别之后,可以让数据达到一致性状态。
可以根据能够恢复一致的时间将弱一致性进一步分类,如果是有限时间那就是最终一致性,如果是无限时间那实际上相当于没有一致性。对于前者,可以进一步分类,如下图所示:
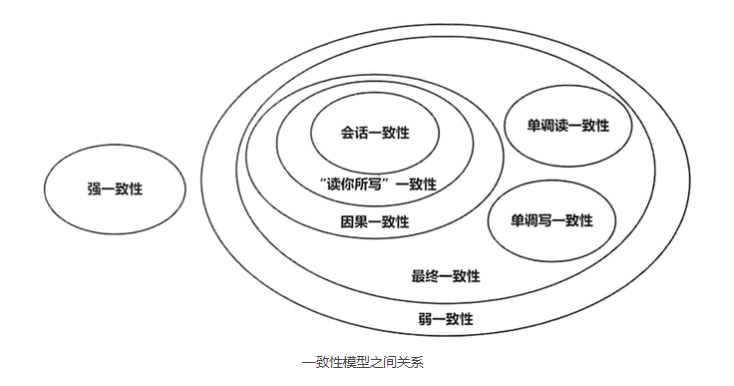
其具体的定义已经在此篇 博客 中有过介绍,此处不再赘述。
有关线性一致性和可序列化之前的异同,可以参考此 博客。重点是来自 Jepsen 官网的一张图,如下所示: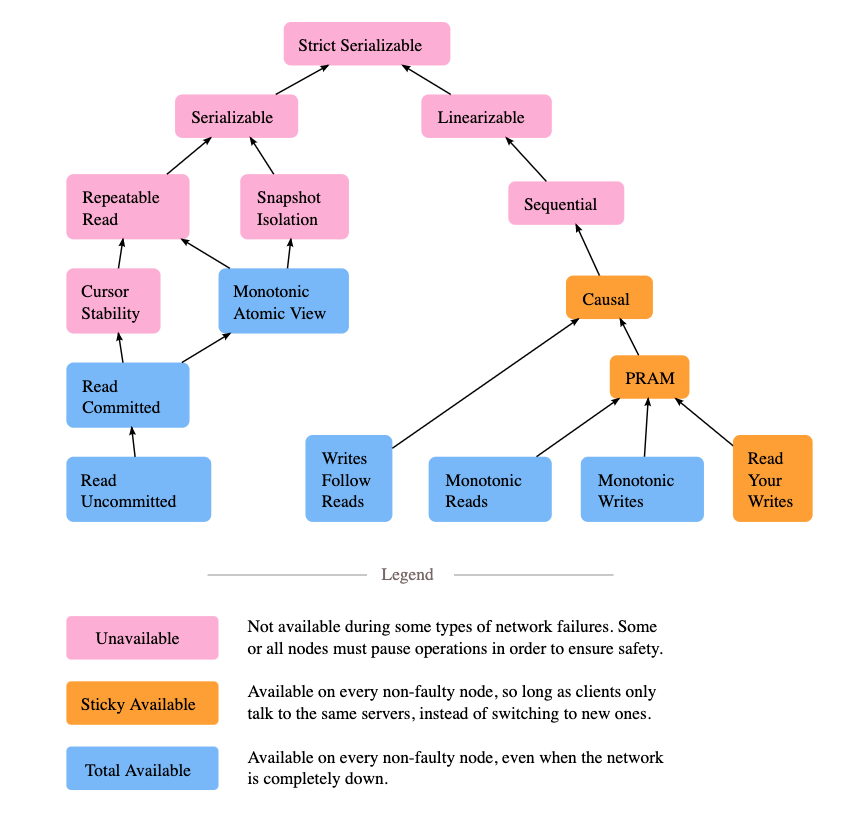
一致性与共识的区别
一致性往往指分布式系统中多个副本对外呈现的数据的状态。如前面提到的顺序一致性、线性一致性,描述了多个节点对数据状态的维护能力。
共识性则描述了分布式系统中多个节点之间,彼此对某个状态达成一致结果的过程。
因此,一致性描述的是结果状态,共识则是一种手段。达成某种共识并不意味着就保障了一致性(这里的一致性指强一致性)。只能说共识机制,能够实现某种程度上的一致性。
实践中,要保障系统满足不同程度的一致性,核心过程往往需要通过共识算法来达成。
共识算法
常见的共识算法有 Paxos,Zab 和 Raft,此处暂只介绍后两种共识算法的一致性模型。
ZooKeeper 的 Zab
一种说法是 ZooKeeper 是最终一致性,因为由于多副本、以及保证大多数成功的 Zab 协议,当一个客户端进程写入一个新值,另外一个客户端进程不能保证马上就能读到这个值,但是能保证最终能读取到这个值。
另外一种说法是 ZooKeeper 的 Zab 协议类似于 Paxos 协议,提供了线性一致性。
但这两种说法都不准确,ZooKeeper 文档中明确写明它的一致性是 Sequential consistency 即顺序一致性。
ZooKeeper 中针对同一个 follower A 提交的写请求 request1、request2,某些 follower 虽然可能不能在请求提交成功后立即看到(也就是强一致性),但经过自身与 leader 之间的同步后,这些 follower 在看到这两个请求时,一定是先看到 request1,然后再看到 request2,两个请求之间不会乱序,即顺序一致性。
其实,实现上 ZooKeeper 的一致性更复杂一些,ZooKeeper 的读操作是 sequential consistency 的,ZooKeeper 的写操作是 linearizability 的,关于这个说法,ZooKeeper 的官方文档中没有写出来,但是在社区的邮件组有详细的讨论。ZooKeeper 的论文 《Modular Composition of Coordination Services》 中也有提到这个观点,官网上也有 声明。
总结一下,可以这么理解 ZooKeeper:从整体(read 操作 + write 操作)上来说是 sequential consistency,写操作实现了 Linearizability。
etcd 的 Raft
对于 raft 算法,其写操作一定得从 leader 向 follower 同步,这是 raft 算法的基石,也是很难变动的。由于 leader 始终是瓶颈,所以即使我们增加节点,raft 算法的写吞吐也不能够线性扩展,反而会越来越差。对于读操作,raft 的默认方式是从 leader 读,这样就能够满足线性一致性,然而这样的实现方式也会导致读吞吐也不能随节点个数的增长而线性提升。zab 提出了一种保证顺序一致性的 follower read 优化,针对读请求能够利用所有节点的计算和 IO 资源,从而使得读吞吐能够线性扩展。raft 更进一步,提出了一种保证线性一致性的 follower read 优化,具体可以参考此 博客。
对于 raft 算法,其写请求自然是满足线性一致性的,对于读请求,需要做一些额外的工作来保证线性一致性,这一点论文中也有说明实现线性一致性读的两种方式:
- Read Index
- Lease Read
对于 Read Index 方法,leader 大致的流程如下:
- 记录当前的 commit index,称为 Read Index
- 向 follower 发起一次心跳,如果大多数节点回复了,那就能确定现在仍然是 leader
- 等待状态机至少应用到 Read Index 记录的 Log
- 执行读请求,将结果返回给 Client
follower 大致的流程如下:
- 向 leader 请求其 commitIndex 来作为本次查询请求的 Read Index
- 该 leader 向 follower 发起一次心跳,如果大多数节点回复了,那就能确定现在仍然是 leader
- 该 leader 返回本地的 commitIndex 给 follower
- 等待状态机至少应用到 Read Index 记录的 Log
- 执行读请求,将结果返回给 Client
实际上 Read Index 流程第二步的主要作用是为了让 leader 确保自己仍是 leader。设想这样的情况:发生了网络分区,leader 被分区到了少数派中,多数派已经产生了新的 leader 并进行了新的数据写入,此时尽管老 leader 发送心跳无法得到大多数节点的回复,但其也无法主动退位。如果对于查询请求 leader 不进行第二步的检查直接读状态机的话,就可能读到旧的数据,从而使得 raft 不满足线性一致性了。
Lease Read 与 Read Index 类似,但更进一步省去了网络交互。基本的思路是 leader 取一个比 Election Timeout 小的租期,在租期不会发生选举,确保 leader 在这个周期不会变,所以就算老 leader 被分区到了少数派,直接读状态机也一定不会读到旧数据,因为租期内新 leader 一定还没有产生,也就不会有更新的数据了。因此 Lease Read 可以跳过 Read Index 流程的第二步,从而降低读延时提升读吞吐量。不过 Lease Read 的正确性和时间挂钩,因此时间的准确性至关重要,如果时钟漂移严重,这套机制就会有问题。
以上算是 raft 实现线性一致性读的直观解释了。
对于以上实现方式,我们还可以分析探讨一下两个问题:
- 如果读写请求都走 leader,要想保证线性一致性还需要上述 Read Index 流程的 1,3 步骤吗?
- 如果开启了 follower read,要想保证线性一致性 leader 还可以 wait-free 吗?
对于第一个问题,我的想法是不需要。因为这个时候读写请求都在 leader 上进行,那么整个系统表现的相当于只有一个副本。分析理论的话:对于一个写入成功的写操作,其状态一定已经被 apply 到了 leader 的状态机上,所以与其有全局偏序关系的后续读请求在执行时一定能够感知到这个写操作,这满足线性一致性;如果没有全局偏序关系,则该读请求和上一个写请求就是并发请求,那么是否感知到这个写操作都是满足线性一致性的,而且一旦该读请求感知到了这个写操作,后续与其有全局偏序的读请求就都能感知到这个写操作,这也是满足线性一致性的。这也是 PingCAP 线性一致性读博客 中 wait-free 优化的具体含义:
到此为止 Lease 省去了 ReadIndex 的第二步,实际能再进一步,省去第 3 步。这样的 LeaseRead 在收到请求后会立刻进行读请求,不取 commit index 也不等状态机。由于 Raft 的强 Leader 特性,在租期内的 Client 收到的 Resp 由 Leader 的状态机产生,所以只要状态机满足线性一致,那么在 Lease 内,不管何时发生读都能满足线性一致性。有一点需要注意,只有在 Leader 的状态机应用了当前 term 的第一个 Log 后才能进行 LeaseRead。因为新选举产生的 Leader,它虽然有全部 committed Log,但它的状态机可能落后于之前的 Leader,状态机应用到当前 term 的 Log 就保证了新 Leader 的状态机一定新于旧 Leader,之后肯定不会出现 stale read。
对于第二个问题,我的想法是不可以。我们设想一个 follower apply 比 leader 快的场景(比如 leader 的磁盘是 HDD,follower 的磁盘是 SSD),比如 leader 和 follower 的日志本来均为 [1,2],此时一个客户端执行了一个写请求,leader 将其进行了广播并进行了 commit,然后正在很慢的异步 apply 中,此时 leader 的日志为 [1,2,3],commitIndex 为 3,applyIndex 为 2,follower 的日志为 [1,2,3],commitIndex 为 3,applyIndex 为 3。此时另一个并发的客户端发起了一个查询请求,该查询请求路由到了 follower,follower 用了上述 Read Index 的步骤拿到了 leader 的 commitIndex 3 并确定自己的 applyindex >= 3 后对状态机进行了查询然后返回。接着该客户端又发起了一个查询请求,该查询请求路由到了 leader,此时 leader 如果采用 wait-free 的方式,则只能对 applyindex 为 2 的状态机进行查询,那么就可能返回旧的数据。虽然此时这两个读请求和另一个写请求是并发关系,是否保证这个写操作的状态都符合线性一致性,但线性一致性还规定一旦读请求感知到了某个写操作,则与这个读请求有全局偏序关系的后续读请求都应该感知到这个写操作,那么这个例子描述的场景就不符合线性一致性了。通过这个例子我们可以看到,如果开启了 follower read,要想保证线性一致性 leader 不能再采用 wait-free 直接读的方式,必须获取 Read Index 才能保证线性一致性,这一点也可以参考 PingCAP CTO 的 博客。
做一个总结:
- 如果不做 follower read 的优化,读吞吐无法随节点个数线性提升,但 leader 可以采用 wait-free 的方式对状态机直接做读操作,这样可以保证线性一致性。(注意:仍然需要通过心跳或 lease 的方式确保自己是 leader)
- 如果做了 follower read 的优化,读吞吐可以随节点个数线性提升,但 leader 不能再采用 wait-free 的方式对状态机直接做读操作,需要严格按照 Read Index 或 Lease Read 的方式才可以保证线性一致性。
总结
本篇博客首先简单介绍了若干一致性模型,然后介绍了一致性和共识的关系,最后对于 zab 和 raft 的一致性模型进行了较为详细的分析讨论。此外,在撰写博客的过程中也发现了一些优质博客如下: