利用 IDEA 对分布式 IoTDB 进行调试
前言
在单机数据库中,寻找 bug 相对较为简单。因为一旦可以复现 bug,那我们可以利用 IDE 在服务端打断点一步步执行并跟踪查看堆栈信息来判断代码出错的位置从而最终找到问题。
在分布式数据库中,找 bug 就变得相对困难了。一方面是因为分布式数据库较难利用 IDE 打断点,其往往通过打 log 的方式来记录错误情况,另一方面是一条客户端请求过来后往往伴随着若干并行和跨节点的 rpc,因此如果通过查 log 的方式来寻找 bug,往往很耗费时间和精力。
在生产环境中,线上 debug 显然是一个不可取(被运维打死)的行为,因此业务只能通过完善日志调用链路的方式来追踪一个请求在分布式系统中的行为,这种方式一方面需要各个项目能够支持对同一 requestId 请求的追踪,另一方面也需要各个应用能够打出合理数量的日志,不能太影响性能但也不能遇到问题无法定位,此外还需要支持海量日志收集(类似于 Flume + Kafka )和全文检索(ES 或 Spark/MR)的应用,总之这是一套相对较重的框架。就分布式追踪而言,目前较火的项目有 Skywalking,Zipkin 等等,可以参考这篇 博客 的介绍。
在测试环境中,尽管我们也可以采用生产环境的 debug 方式,但显然我们希望能够找到效率更高的方式。万幸的是,Jetbrains 全家桶为我们提供分布式系统的 debug 方式。比如对于 Java 应用而言,IDEA 就提供了远程 debug 和本地多进程 debug 的方式。对于远程 debug,可以参考这篇 博客 介绍的方式对远程的应用进行 debug,也可以参照这篇 博客 介绍的方式对分布式 IoTDB 远程 debug;对于本地多进程 debug,本篇博客将介绍如何利用 IDEA 对分布式 IoTDB 进行调试。
有关 Apache IoTDB 可以参考 官方网站。
本地多进程 debug 调试
对于 IoTDB 集群的搭建示例,可以参照 官方文档,其分布式模块的启动主类为 ClusterMain.java,其默认的三节点分布式配置参数文件夹可以参考 这里。
1 | |
可以看到其按照 seednodes 启动时指定 -s 即可,此外其也支持通过 -D{} 的方式来覆盖参数,因此我们可以利用 IDEA 分别指定不同的配置文件夹并用 debug 模式来启动三个 clusterMain 进程,这样即可达到本地多进程 debug 调试的理想效果。
操作步骤
- 点击
Edit Configurations...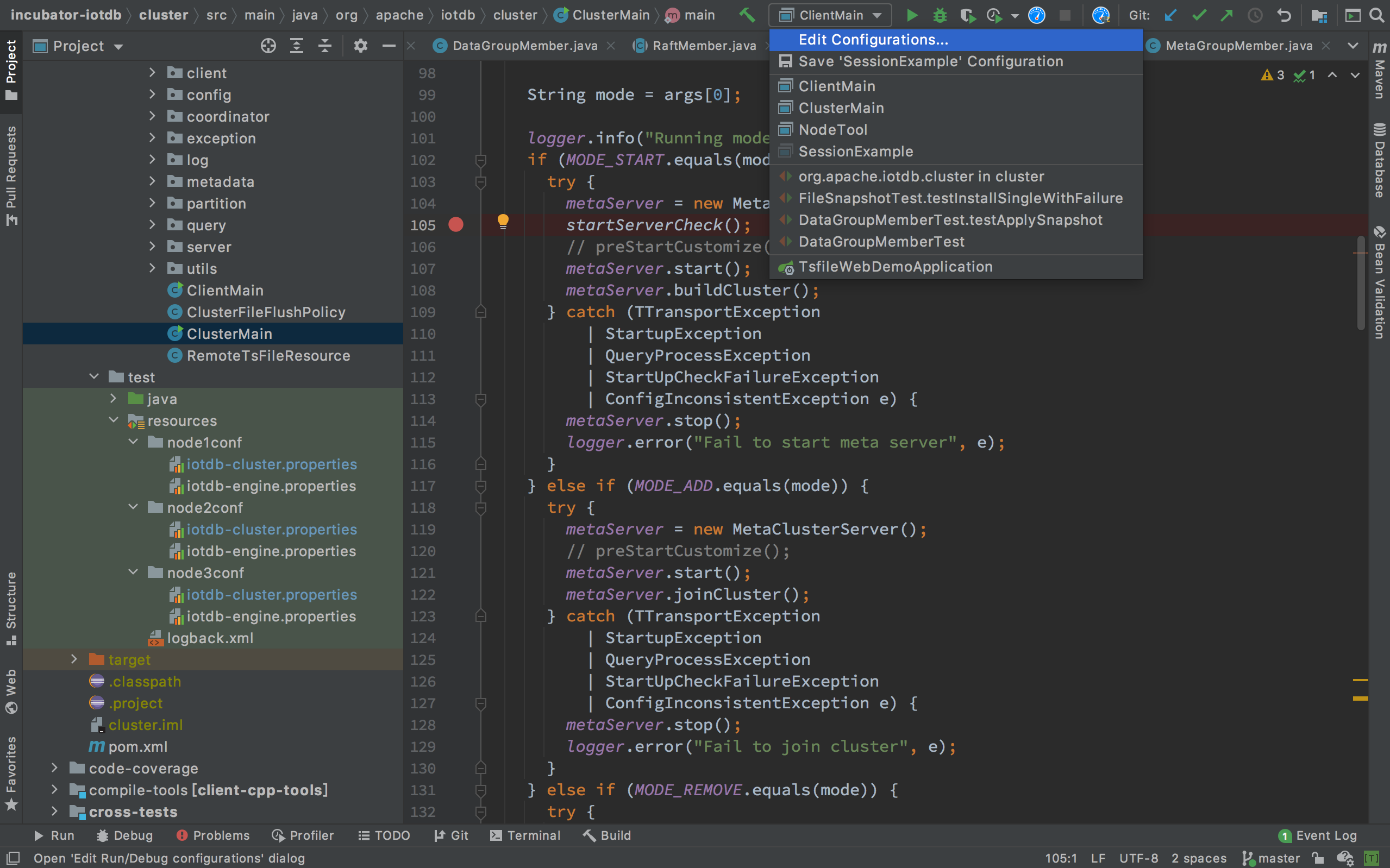
- 点击
Add new Configuration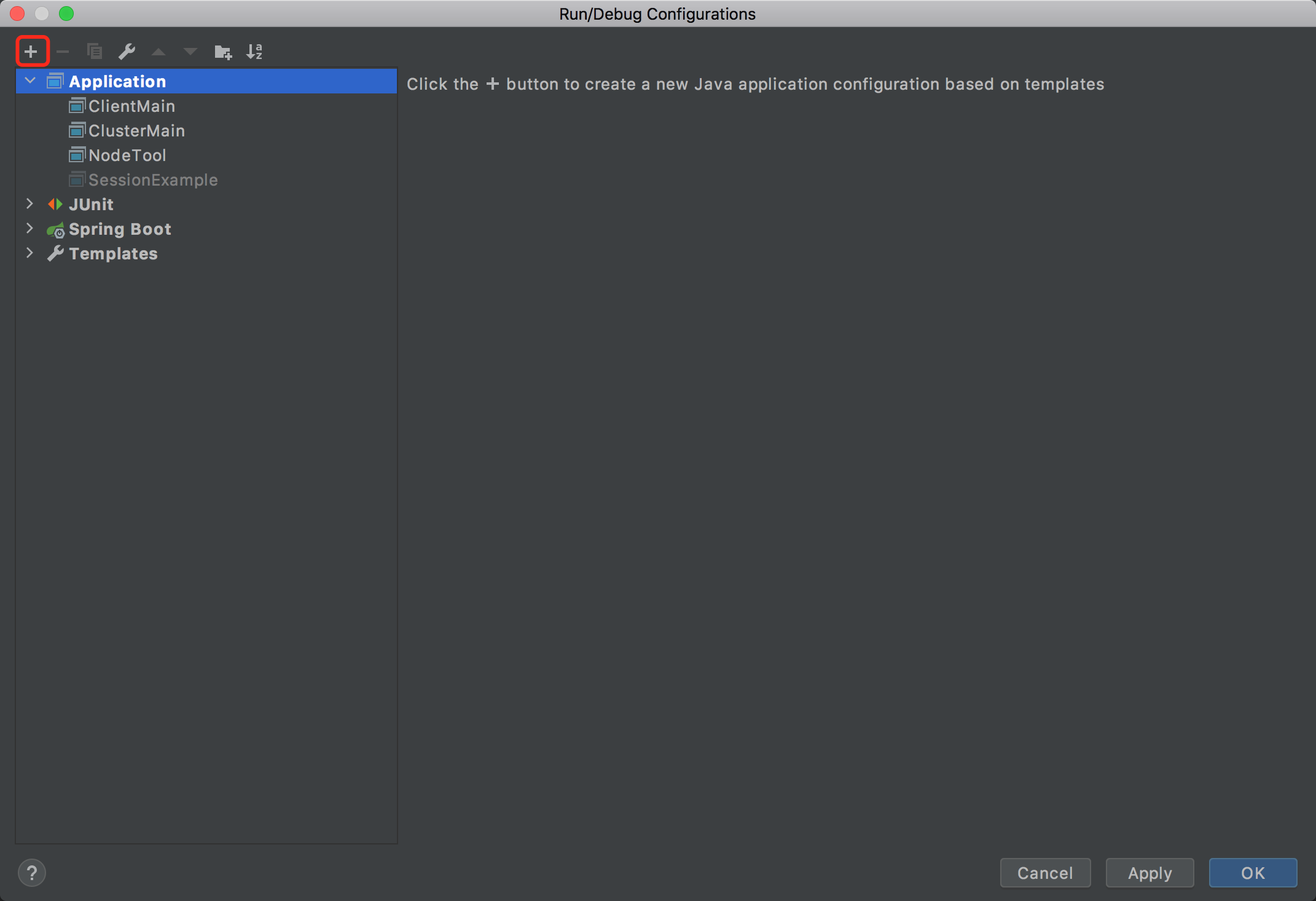
- 点击
Application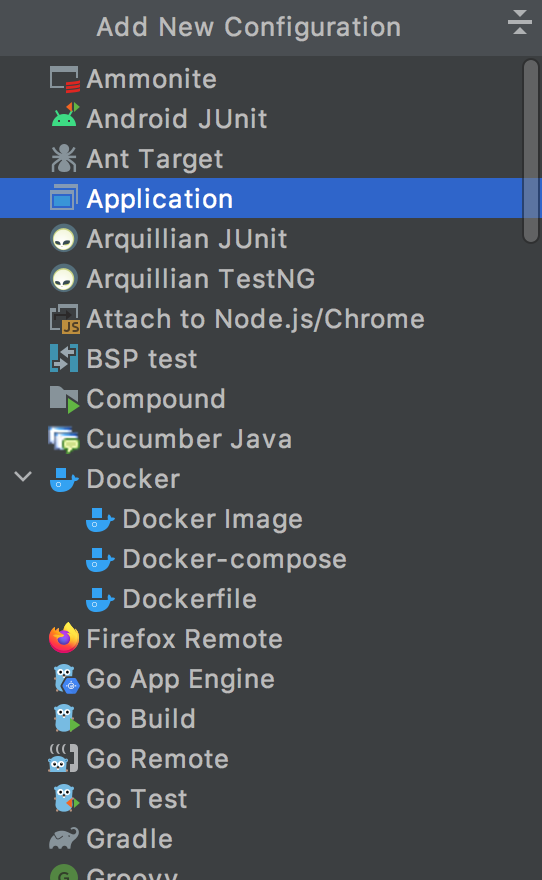
- 编辑好红框的五个部分,指定配置名称,jdk 版本,启动模块,启动主类和启动参数
-s,然后点击绿框。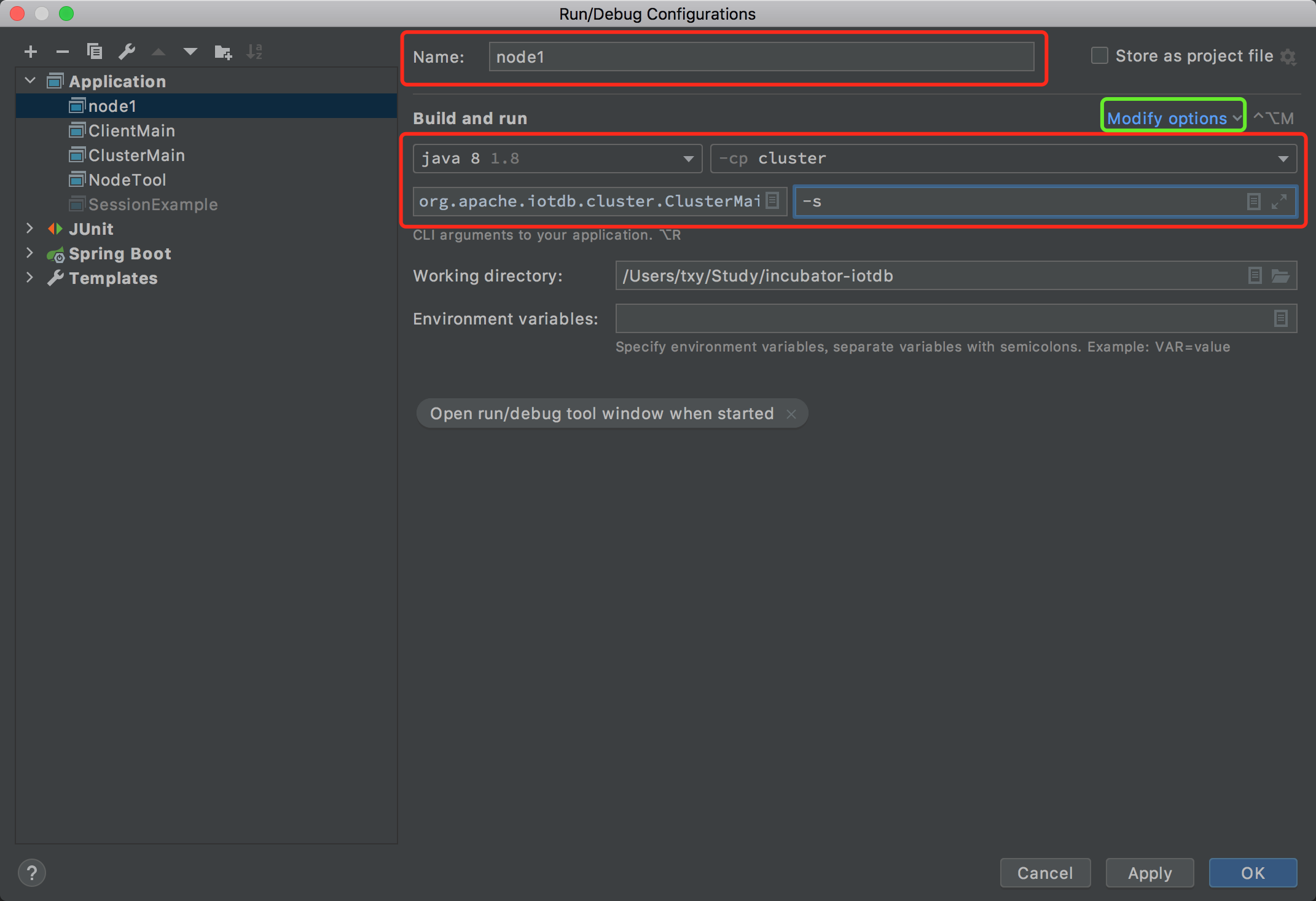
- 点击
Add VM options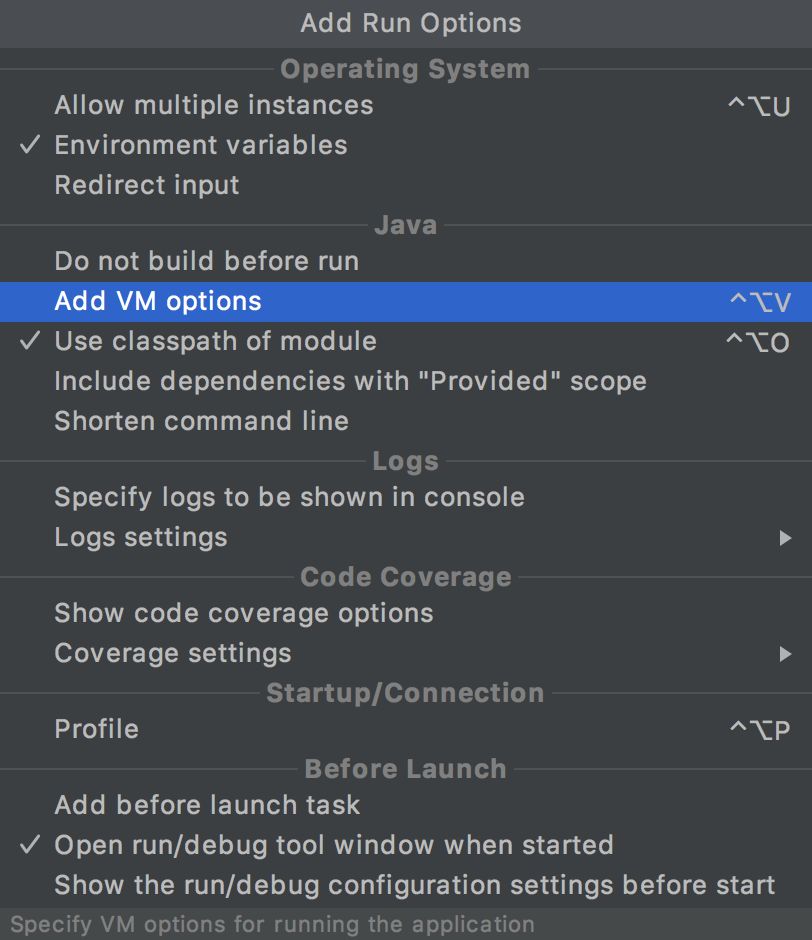
- 添加
-D{}环境变量,例如我填的就是-DIOTDB_CONF=/Users/txy/Study/incubator-iotdb/cluster/src/test/resources/node1conf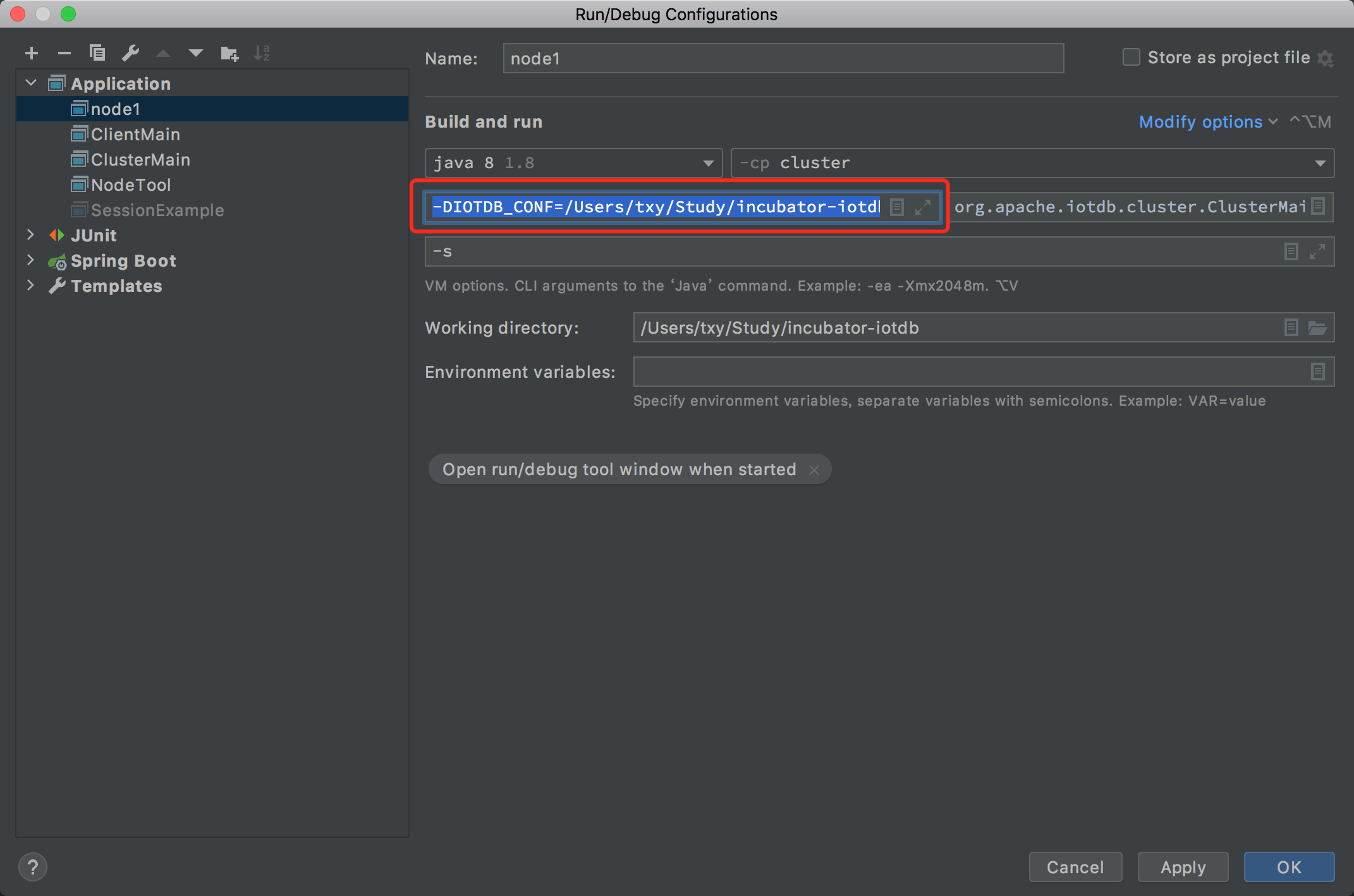
- 复制两份 node1 的配置
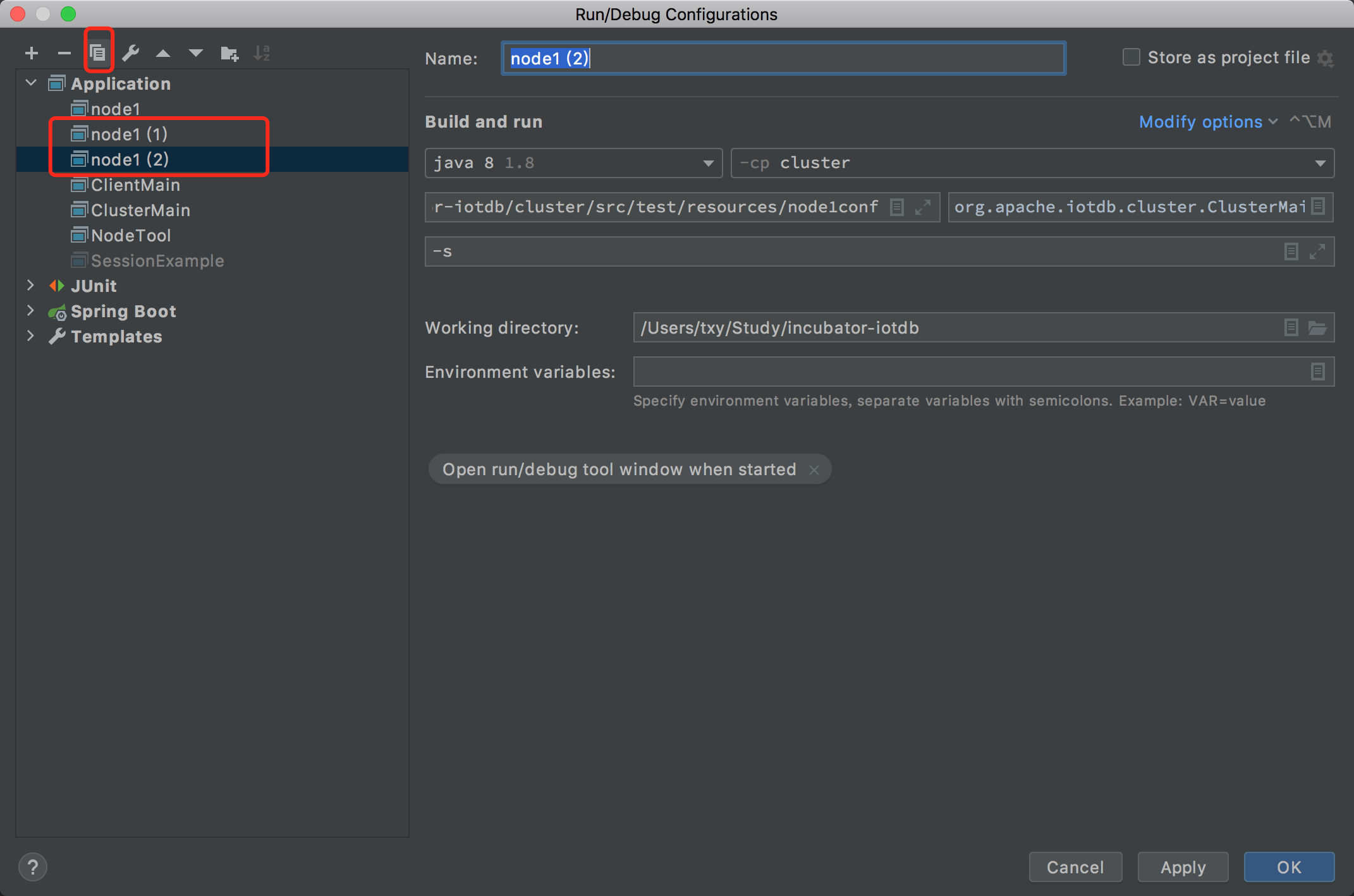
- 编辑好 node2 的名称和配置文件
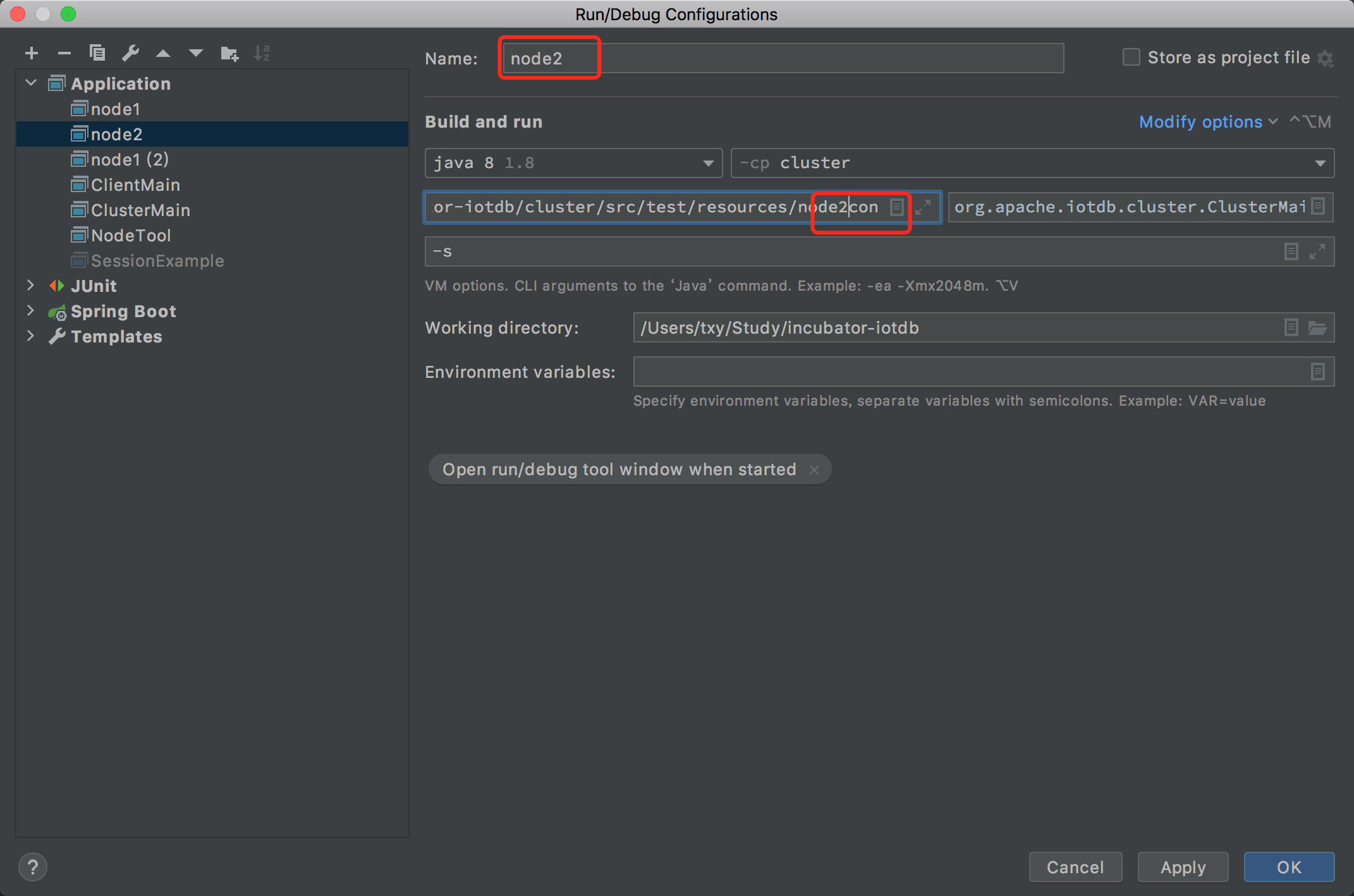
- 编辑好 node3 的名称和配置文件
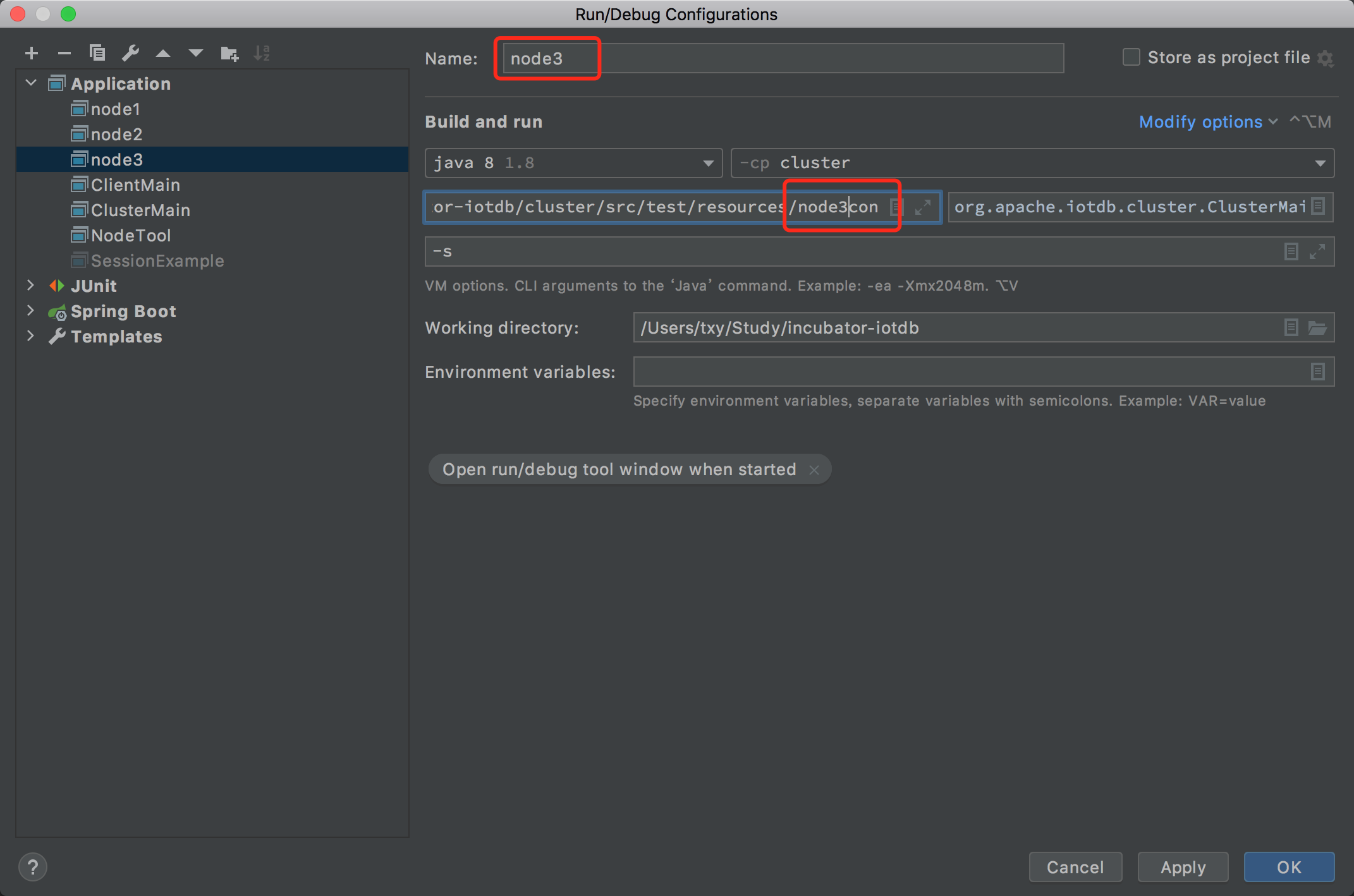
- 以 debug 模式分别启动 node1,node2 和 node3
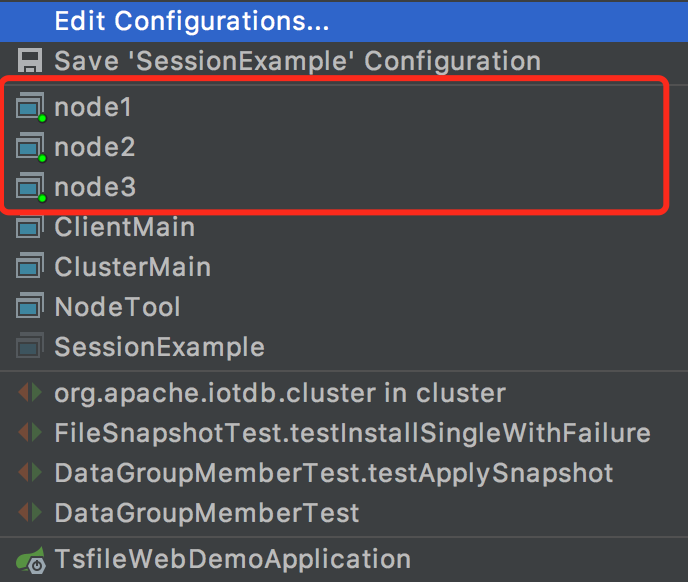
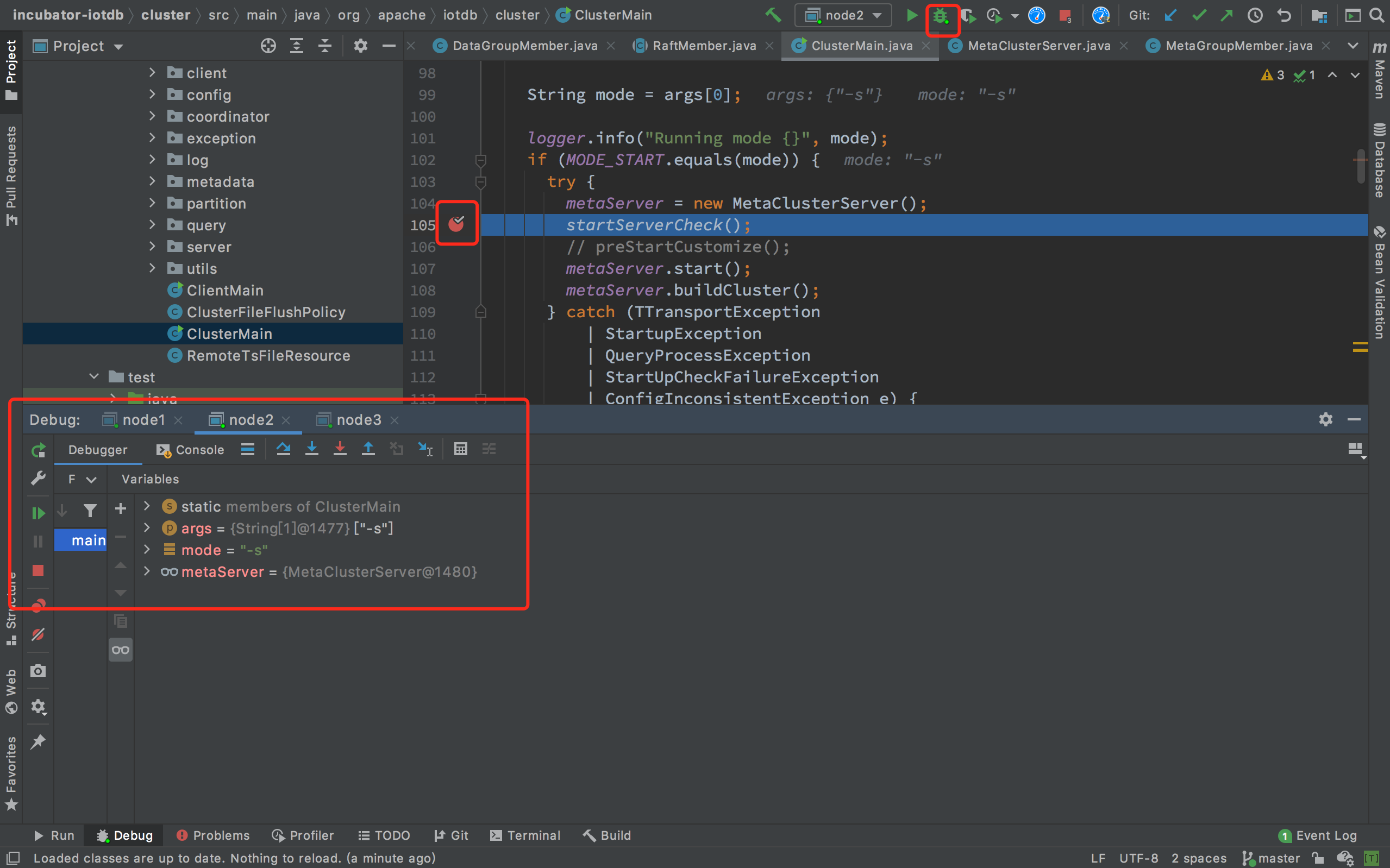
- 可以执行对应的请求来触发 bug,从而开始 debug 调试(此时相当于 idea 用 debug 模式启动了三个进程,构成了一个可以 debug 的三节点伪分布式 IoTDB)
总结
本片博客简单介绍了如何使用 IDEA 调试分布式 IoTDB,希望能对大家 debug 分布式系统有所帮助。