2022 TiDB Hackathon 产品组最佳校园奖总结
背景
2022 年 10 月,2022 TiDB Hackathon Possibility at Scale 成功举办。
作为暑期实习在贵司事务组的 intern,在对 TiKV 的 codebase 有一定了解后,我兴致勃勃地拉了实验室的同学报名参加了此次 Hackathon,并且最终拿到了产品组的最佳校园奖,虽然没有拿到更大的奖项,但已经玩得十分开心了。
非常感谢 Hackathon 期间队友,mentor,组织者和评委对我们组的帮助和认可。
本文将简单介绍我们组的工作和思考以做回顾。
以下是我们项目的一些相关资料,欢迎点击了解:
注:本文仅代表个人看法。
工作
本小节将沿着答辩 PPT 的思路介绍我们的工作。
我们的名字是热点清零队。我们的项目是无畏写热点,我们希望能够解决 TiKV 写热点问题的最后一公里。

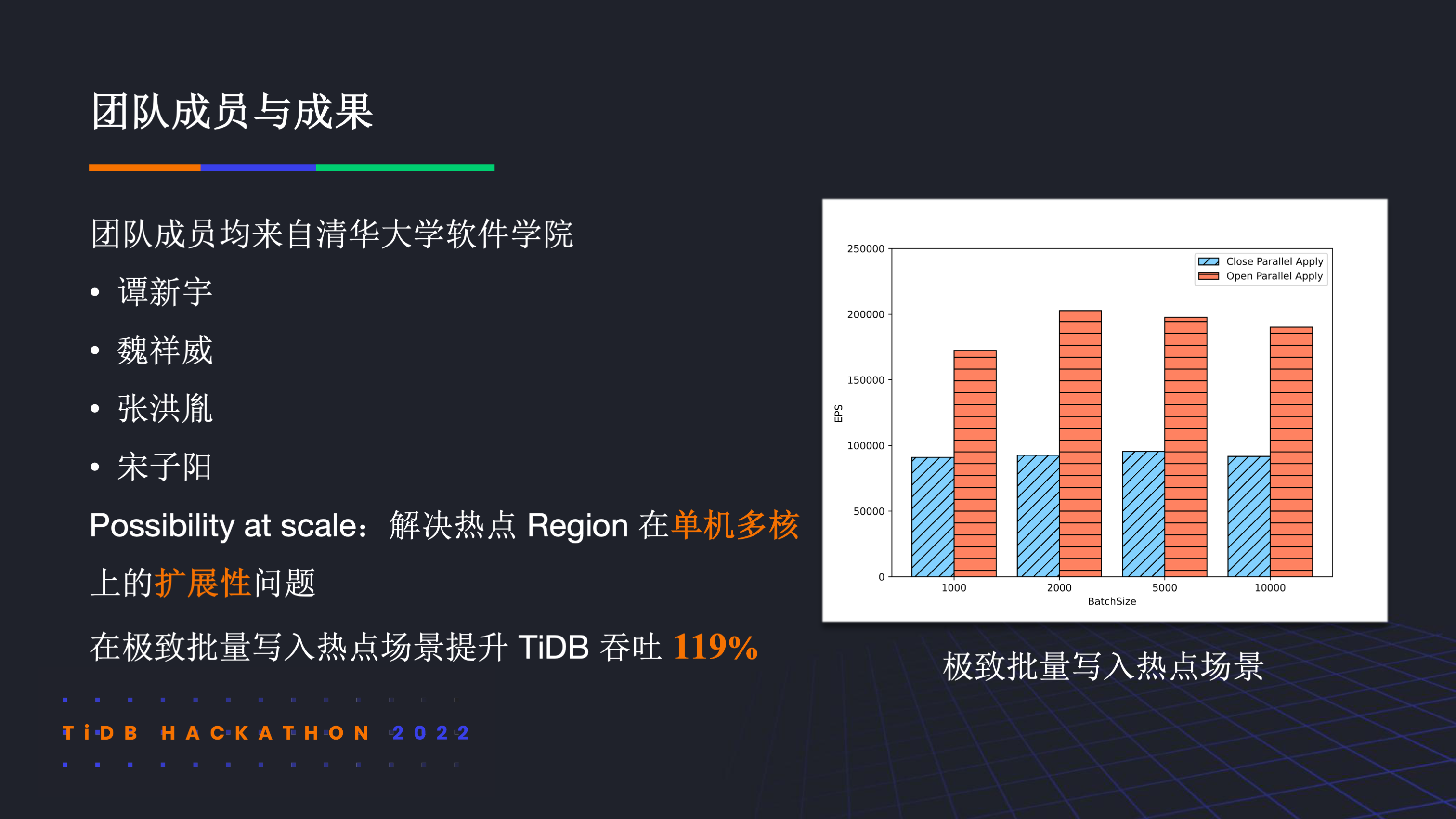
我们的团队成员均来自清华大学软件学院。今年 hackathon 的主题是探索 scale 的可能性,我们的主要工作是解决热点 Region 在单机多核上的扩展性问题。在极致场景下我们提升了 TiDB 接近 1.2 倍的吞吐。
从用户视角来看,写热点问题会给他们带来多少困扰呢?比如某用户就提出,批量写场景下 TiKV 的 CPU/IO 都没用满,但写入依然很慢,这些现象给用户带来了不便和困扰。我们统计了 AskTug 论坛上写满 tag 帖子的原因分布,大致如右上图所示,可以看到写热点问题占比第一。

那现在的 TiDB 是如何解决热点问题的呢?其整体思路都是通过划分 region 来均匀承担负载,从而能够扩展。如右图所示,理想情况下随着 region 的分裂,热点会被稀释,进而线性扩展起来。然而,在当前上层数据分片的语义下,对于聚簇索引,唯一自增索引等场景,写热点问题难以避免。
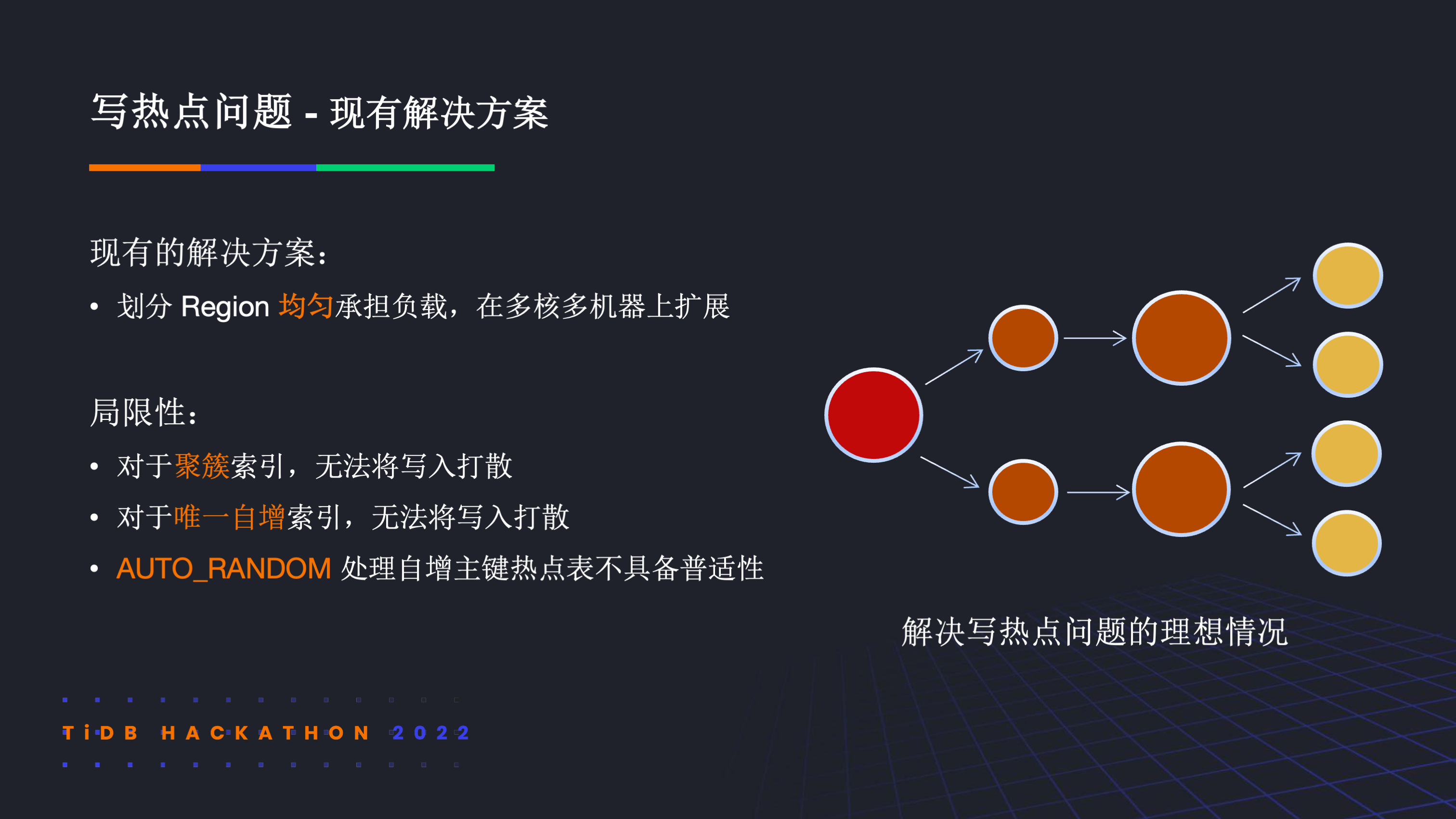
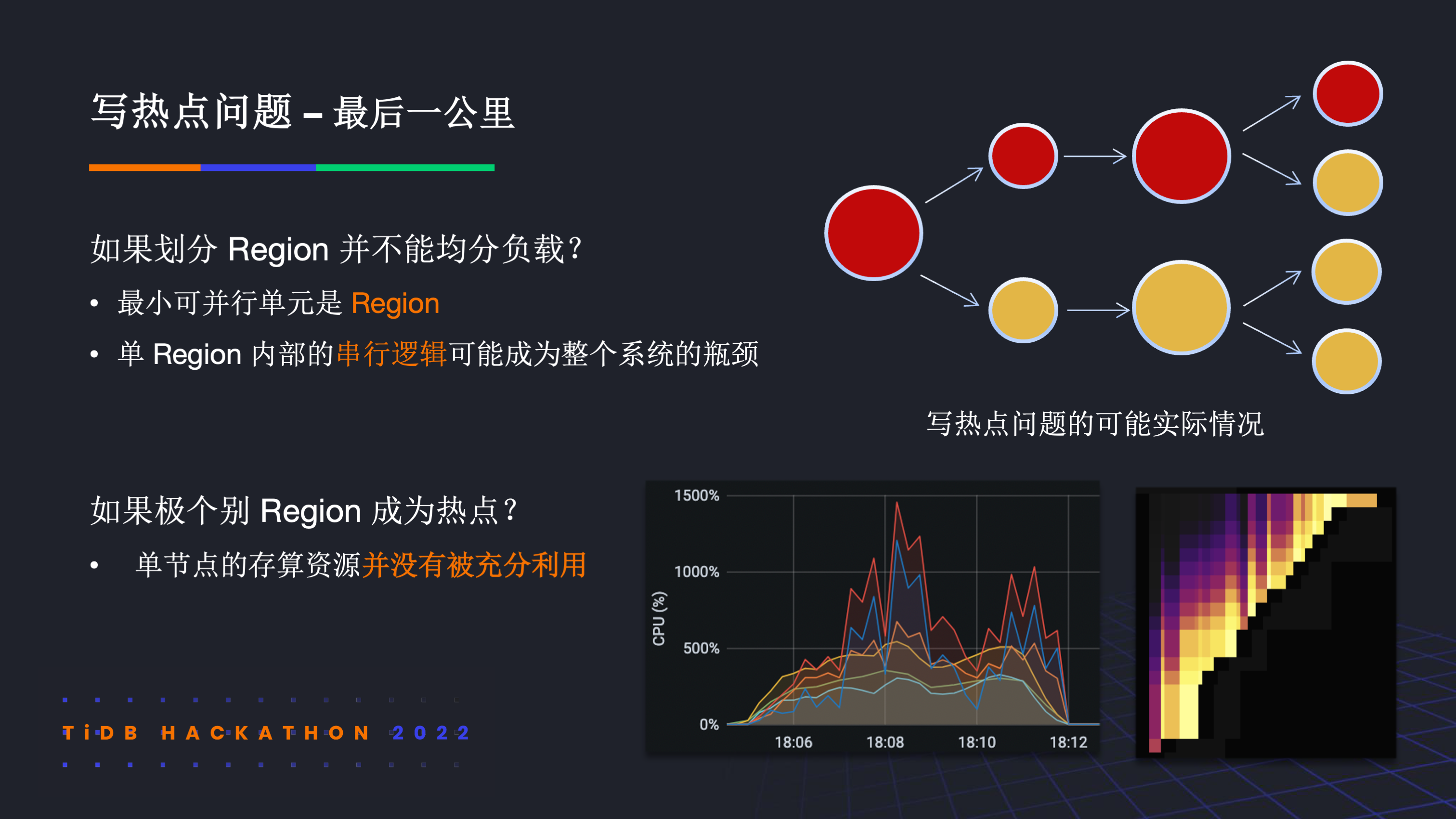
当分裂 region 不能均分负载时,实际情况会如右上图所示,尽管分裂出了多的 region,但写热点始终集中在个别 region 上。在这种场景下,往往会遇到单节点存算资源并没有被充分利用的情况。其实不论上层怎么去分裂 region,单 region 热点始终是写热点问题的最后一公里,无法回避。
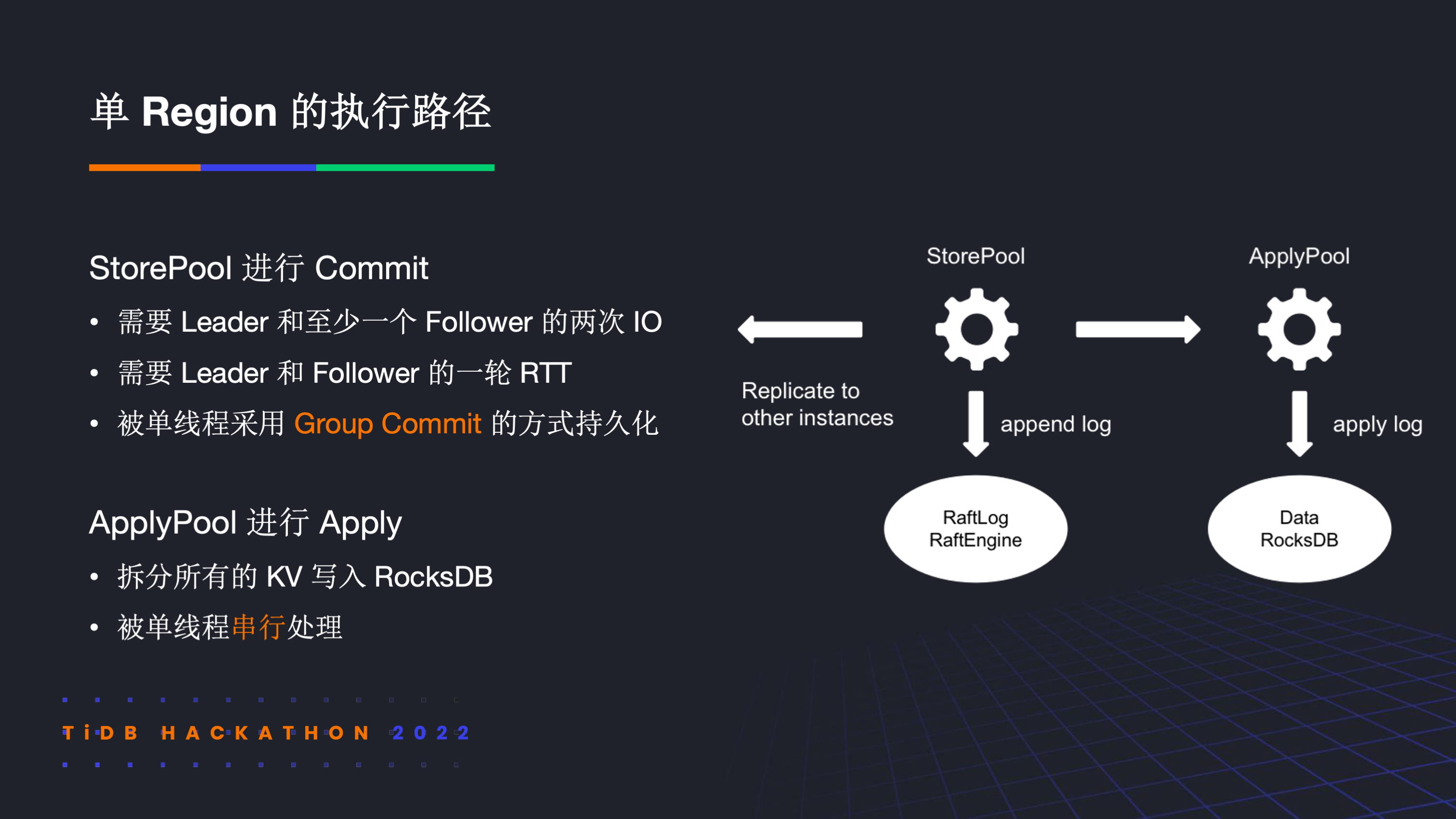
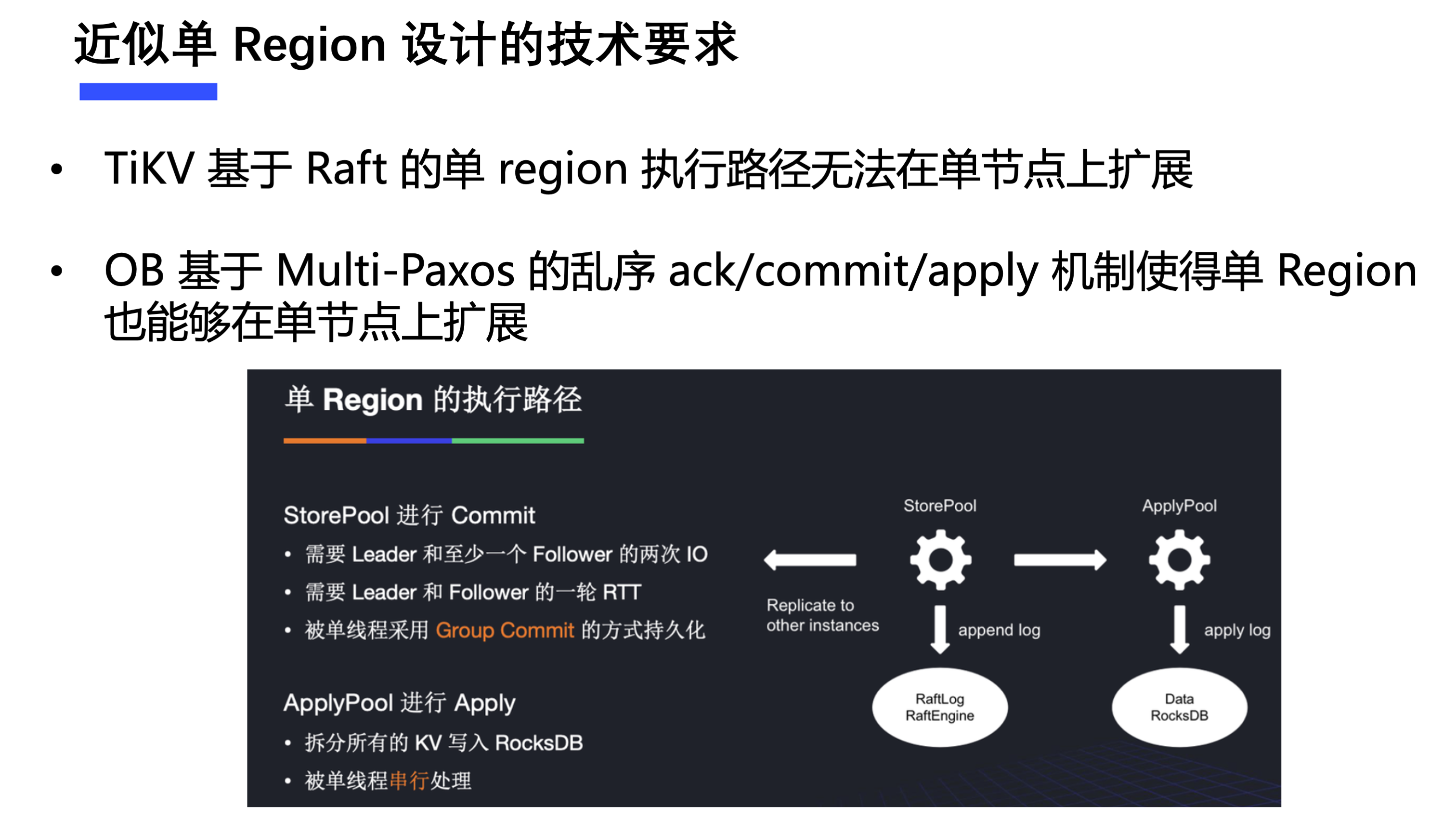
那让我们看看在 TiKV 中单 region 的执行路径。总体来说是需要在 StorePool 中进行 commit,在 ApplyPool 中进行 apply。然而在现有的实现中,不论是 StorePool 的持久化还是 ApplyPool 的写 memtable,并行度都是 1,因而不具备在单机上的扩展性。
那如果我们想要在单机上扩展热点 region,那可以从存储资源和计算资源两个方面来入手。对于存储资源,可以利用 IO 并行来提高吞吐,比如将单 region 不同批的日志用异步 IO 并行化处理,去年的 TPC 项目已经做过尝试,取得了不错的效果。对于计算资源,理论上也可以采用多核并行来提高吞吐,这也是我们的尝试,即去做 Parallel Apply

Parallel Apply 的整体思路是将无依赖的日志并行处理,从而提升整体吞吐。2018 年 VLDB 和 2021 年 JOS 已经对 Parallel Apply 的可行性和正确性进行了证明。

那在 TiKV 上落地 Parallel Apply 会有哪些难点呢?我们主要遇到了 4 个问题,比如如何保证依赖顺序的正确性,数据正确性,语义正确性和 index 正确性等等,以下分别进行介绍

我们的整体思路是在 ApplyPool 以外额外引入一个 ParallelApplyPool,并在 StorePool 中判断路由,进而使得单 region 的日志存在并行的可能性。同时在实现过程中,为了避免锁导致的线程切换,我们的共享状态均使用了原子变量。
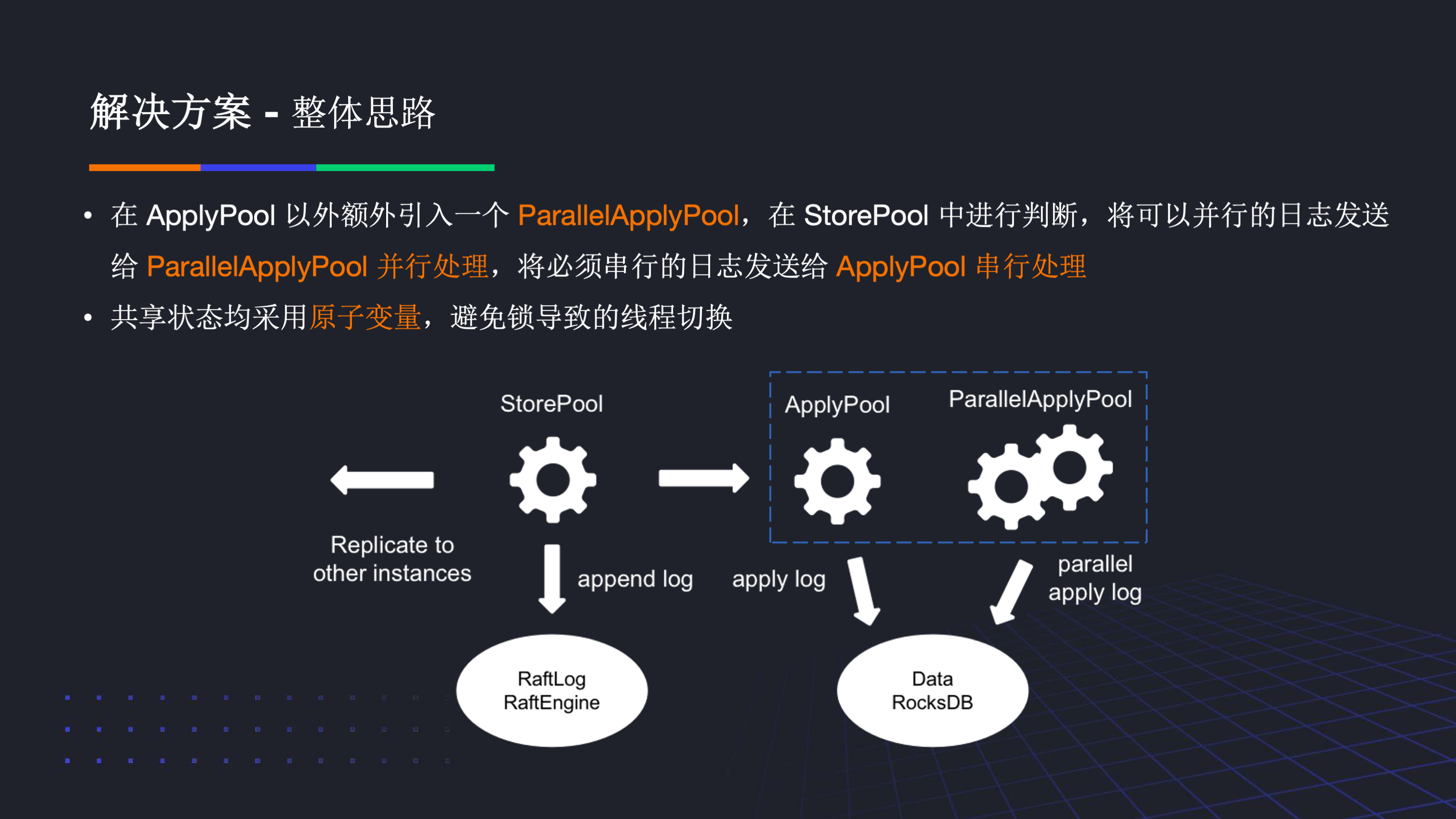
对于刚刚提到的难点,我们简单介绍一下解决方案。
对于如何保证具有依赖的日志执行顺序正确?在 Leader 侧和在 Follower 侧需要有不同的处理方案。
- 在 Leader 侧,得益于上层事务语义的约束,我们不需要引入依赖检测结果便可以无约束的并行 apply 普通日志,因为他们的 key 范围必定不会重叠。
- 在 Follower 侧,最简单可以串行执行来保证正确性,更进一步也可以考虑基于拓扑排序的依赖检测机制来并行 apply 日志从而满足依赖关系。
对于如何保证 leader 切换或重启时数据依然正确?我们则很简单的使用了 Raft 的 term 变量,当且仅当日志的 term 为当前 term 时才考虑路由到 ParallelApplyPool 并行处理。这样的机制保证了 Leader 切换或者节点重启时系统不会将本不能并行处理的日志并行化处理,从而导致数据不一致。

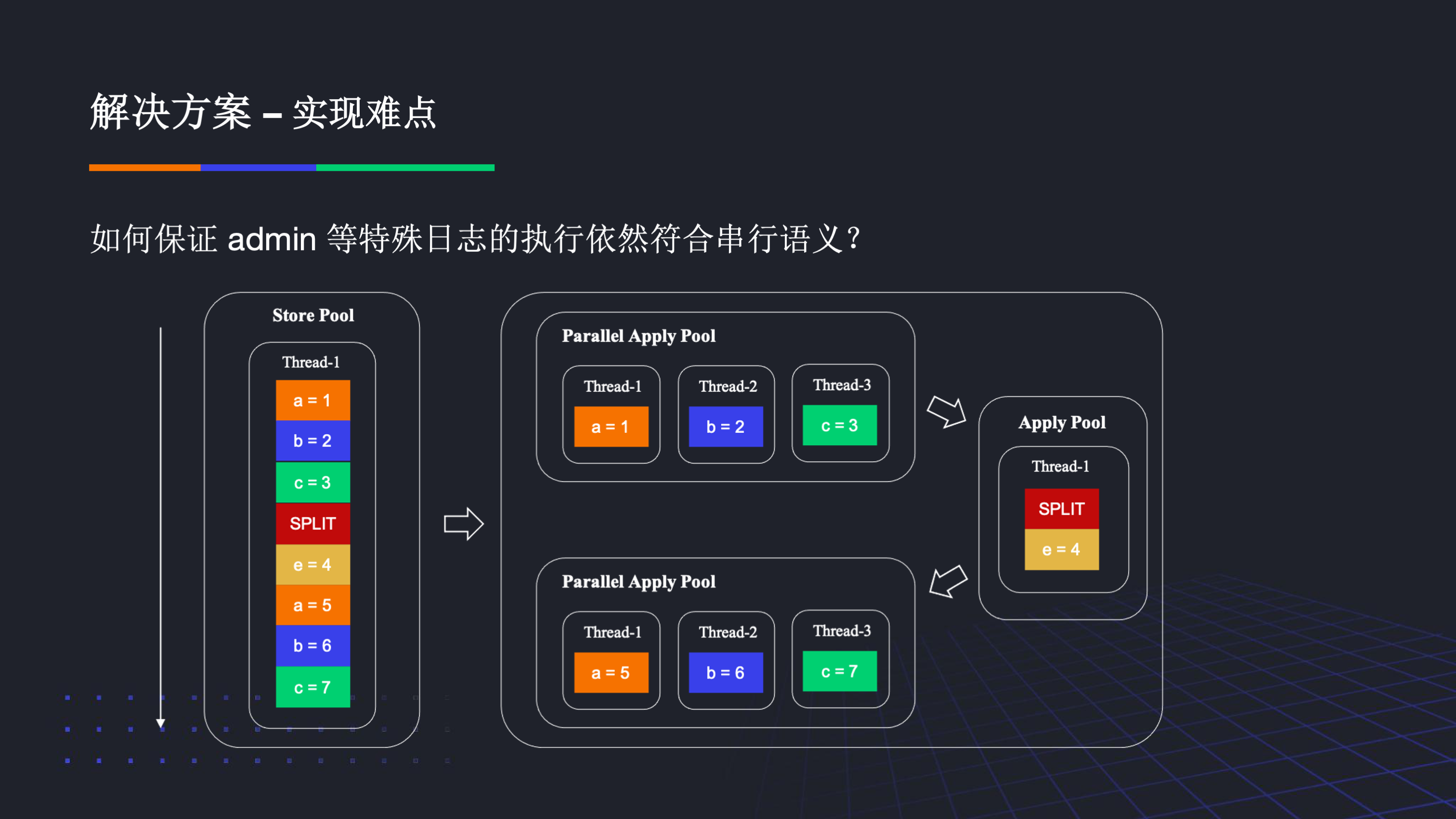
对于如何保证 admin 等特殊日志的执行依然符合串行语义?即在 admin 日志执行之前其前面的所有日志均需要已经执行,在 admin 之后的日志执行前必须保证该 admin 日志已经执行。这个具体实现非常复杂,简单来说,我们在 Parallel Apply Pool 和 ApplyPool 中用原子变量共享了一些状态,对于单 region,StorePool 会将无冲突的普通日志在 Parallel ApplyPool 中并行执行,当出现 admin 日志时,当 StorePool 未感知到其执行完时,所有的日志都会被路由到 ApplyPool 中串行执行,当 admin 日志的 apply 结果返回 StorePool 后,之后的普通日志可以被继续路由到 Parallel Apply Pool 中并行执行。在 ApplyPool 中,我们还用原子变量来保证了只有 Parallel Apply Pool 中有关该 region 的所有普通日志都已执行完才去执行 Admin 日志。这些工作使得 admin 等特殊日志的执行依然符合了串行语义。在实际测试中,大部分普通日志都能够在 Parallel Apply Pool 中并行处理。,这也是我们在写热点场景性能提升的根源。
对于如何保证 applyIndex 的更新,我们发现不需要在磁盘上实时更新 applyState,这主要与底层 KV 引擎的幂等语义有关。我们在内存中维护了可能存在空洞的 applyIndex,当其连续时才推进 StorePool 中的 applyIndex,这也与现有的代码实现了兼容。

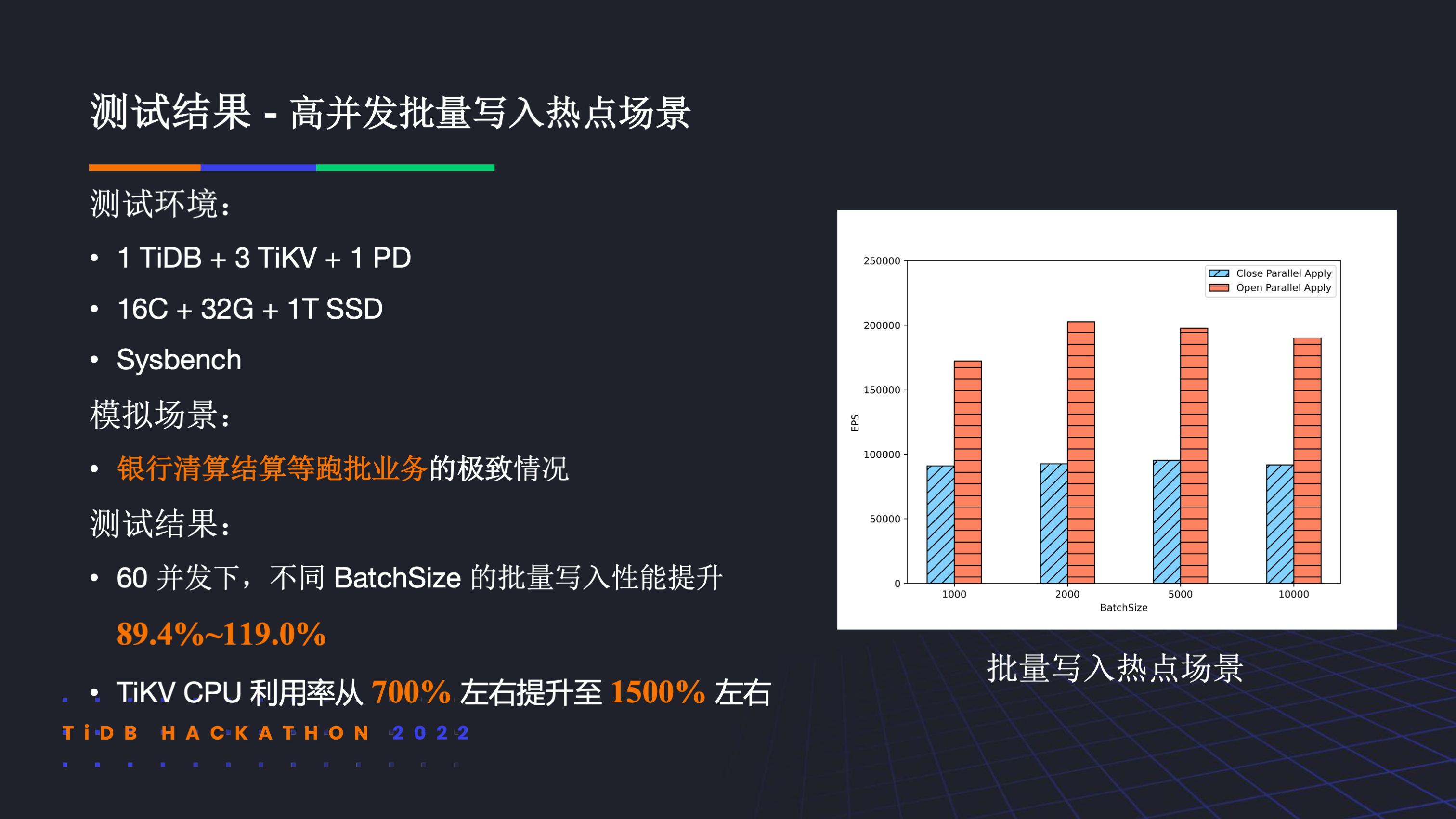
我们模拟了银行清算结算等跑批业务的极致情况,在 60 并发下,不同 BatchSize 的批量写入性能提升 89.4%~119.0%。TiKV CPU 利用率从 700% 左右提升至 1500% 左右。
我们也尝试了通用的批量导入热点场景,对于 TPCC prepare,在 1024 BatchSize 下,不同并发批量写入性能提升 29.8%~36.0%,TiKV CPU 利用率也从 750% 左右提升至 1000% 左右

在测试过程中,我们也更深刻地体会到了木桶效应。在 apply 是瓶颈的热点场景下,我们能取得很好的效果。但是对于 apply 不是瓶颈的场景,尽管这个阶段可能会加速,但根据阿姆达尔定律,最终的整体收益也不明显。

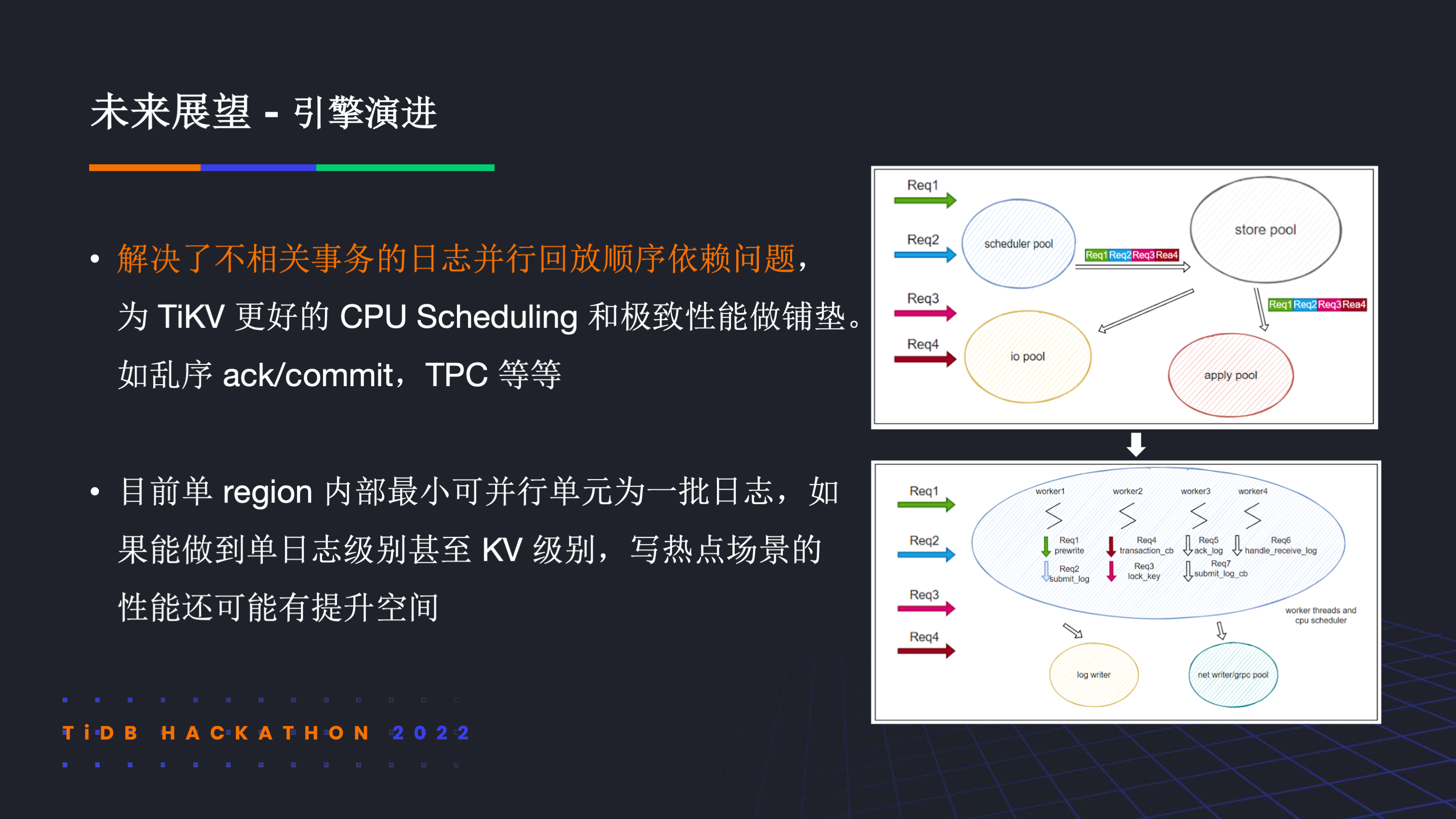
展望未来,我们认为我们的工作拼好了 TiKV 解决写热点问题的最后一块拼图,给出了解决写热点问题的终极形态。在多节点上,我们可以用 Split Region 的方式来在多节点上 scale。在单机上,我们可以用 Parallel Redo log 甚至是 Multi-Paxos 来更好地利用磁盘资源,也可以用 Parallel Apply 来更好的利用 CPU 资源,最终也能够在单机上彻底 scale。

同时在引擎演进方面,我们解决了不相关事务的日志回放顺序依赖问题,为 TiKV 更好的 CPU Scheduling 和极致性能做了铺垫。比如未来可以结合乱序确认乱序 commit 和 TPC 策略来对资源进行更精细的控制。
思考
本小节将更随心的介绍一些我们的思考。
在这次 Hackathon 中,从技术上我们为 TiKV 做了 Parallel Apply 的优化;从产品上我们在高并发批量写入热点场景会有不错的收益。
上小节已经介绍了基于 region split 的方式来缓解热点问题的局限性,那么如何解决这种局限性呢?这就要回到一个圣战问题了:Raft 和 Multi-Paxos 有什么区别?
如同我在 RFC 中介绍的一样,相比 Multi-Paxos,Raft 不能乱序 ack,不能乱序 commit,不能乱序 apply,因而有同学认为 Raft 不如 Multi-Paxos。
dragonboat 的作者对此观点进行了 反驳,其主要有两个观点:
- 乱序并行 apply 不如拆分出更多的 raft 组来并行。
- 对于一个通用的共识库,不能乱序 apply 是受限于 RSM 模型本身的限制,并不是 Raft 本身的问题。对于特定场景,乱序 apply 可以达到一定效果,但并不是一个通用性的优化。
对于第一个观点,从 TiKV 的角度来看,目前默认的 region 大小为 128M,尽管理论上 raft 组数拆的越多,单 raft 组内的串行化 apply 对性能的影响就越小。然而,raft 组过多带来的其他问题也会接踵而来,比如在 TiKV 实际测试中观察到过多的 region 和过大的 LSM Tree 都会导致性能的回退,因而未来 TiDB 的 Dynamic Region 工作计划一方面调大 region 大小到 512MB 至 10GB 从而减少 region 个数,另一方面则是拆分 RocksDB 实例。由此可见,影响 region 大小的因素并不只有 raft 串行化的问题。在未来,一方面 TiKV 的 region 会比现在更大,因此单 raft 组内的串行化问题会更加明显从而可能成为瓶颈;另一方面拆分 RocksDB 实例后 split 也不会再像现在这么轻量,因而实时动态的 split 负载均衡策略相比现在也会趋于保守。总体来看,在 TiKV 内实现乱序 apply 在未来是一个非常有可能的性能优化方向。
对于第二个观点,的确从通用的共识库的角度出发,乱序 apply 并无太大意义。但从 TiKV 中内嵌的共识算法来看,由于共识层之上的事务层已经定了一次序,因而共识层的重复定序在有些 case 下是没有意义,此时的乱序并行 apply 更可能提升热点场景的性能。
事实上,如果不支持乱序 apply,那共识算法的乱序 ack 和乱序 commit 可能没太大意义,因为整个共识组的瓶颈受限于最慢的模块。如果只能顺序 apply,那即使乱序 commit 了一批日志,如果这些日志之前存在空洞,那么这批日志也只能在内存中等待而不能被 apply。然而如果支持了乱序 apply,那结合乱序 ack 和乱序 commit 就更可能提高共识组的吞吐上限。比如一旦支持乱序 commit,那可以使用多个 IO depth 来持久化不同批的日志,这样每次 IO 的大小减少了,也可能能够减少每次 IO 的平均时间。此外支持乱序 commit 后也可以将前面存在空洞但确保与空洞日志无依赖关系的一批乱序 commit 日志提前 apply 处理,进而抬高 apply 的瓶颈天花板。
总体来看,Parallel Apply 能够解决 region 写热点在多核上的扩展性问题,Multi-Paxos 能够解决 region 写热点在现代硬盘上的扩展性问题。因此,Multi-Paxos + Parallel Apply 理论上能够解决写入热点在现代硬件上的扩展性问题。预计能够在写热点场景更充分的利用硬件资源,从而提升性能。
在写 Hackathon RFC 的时候我更多的关注了对于写热点场景下 Raft 与 Multi-Paxos 的区别,然而对于其他场景,我意外的发现 Raft 和 Multi-Paxos 也能体现不同的价值。
在 OB 社区 4.0 版本的 介绍 中,专门提到了一个很大的变动:自适应日志流,即将分片与共识解耦。在不考虑 leader 打散情况下,每个租户在一个进程中可以有多个分片但只会有一个共识组。
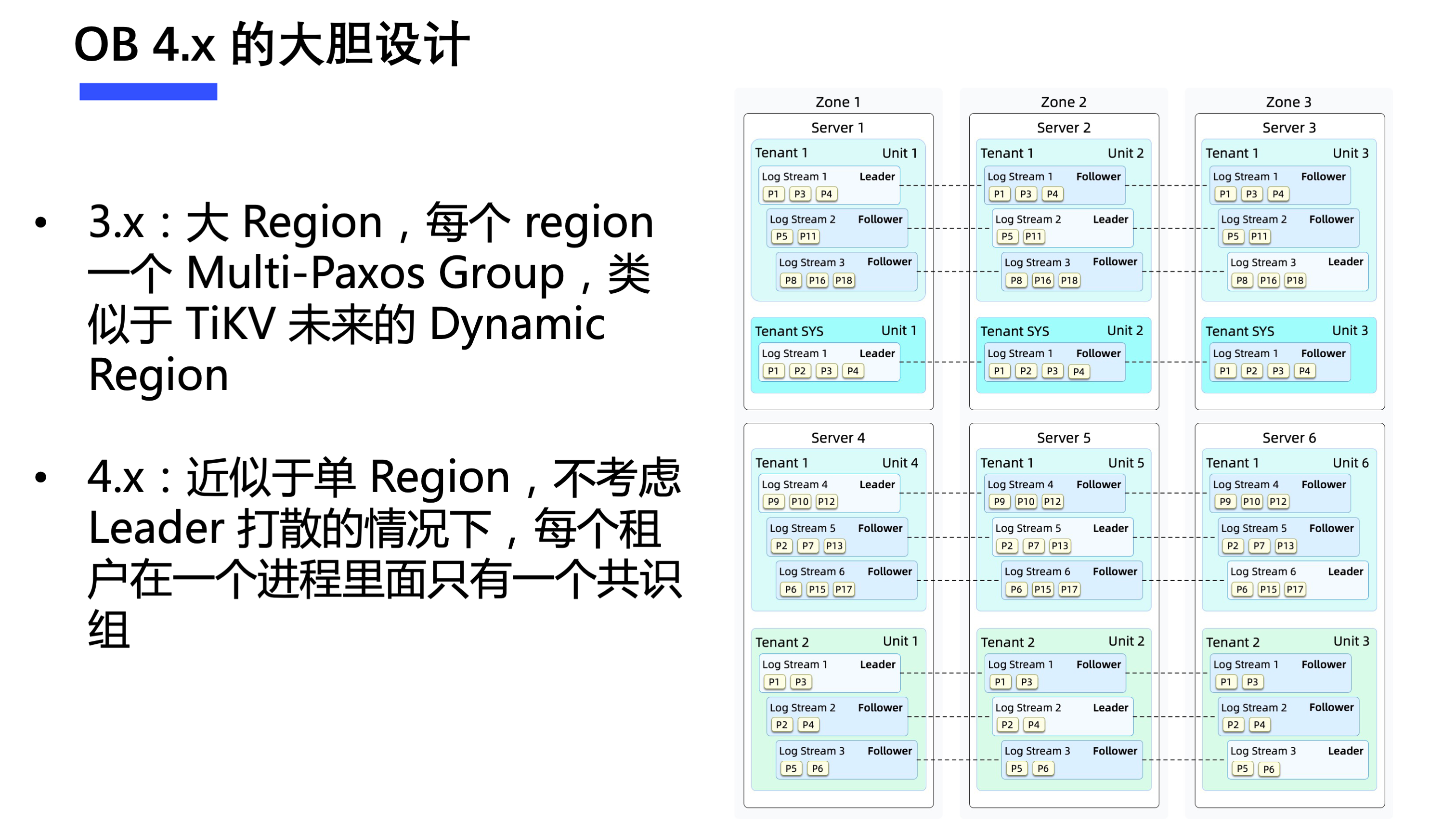
基于传统 Raft 的方案是很难去做出这样的架构设计的,但 Multi-Paxos 可以做到。
在收益方面,除了完全控制共识组个数和增大 1PC 比例以外,OB 4.0 更是基于自适应日志流架构重构了事务引擎,从而对大事务有了更好的支持,并基于这些工作产品化包装出了单机分布式一体化架构。这个架构的缺点就是灵活扩缩容和实时负载均衡会更难做,但如果考虑云上的部署形态,这些新的问题又可以通过其他方案来缓解。

总体而看,一个系统的架构设计就是要在关键模块的各种 trade-off 中做出纠结的选择,并且一旦做出了某个选择,就需要基于这个选择更进一步做非常多的产品化工作和优化打磨来提升这些技术对于用户的实际价值。例如,TiDB 选了 TSO 的时间戳获取方案并不代表就不能服务跨数据中心场景了,其也做了 Local/Global TSO 的产品化工作来满足部分用户场景的跨数据中心需求。CRDB 用了 HLC 之后并不仅仅体现在获取事务时间戳更快,其至少还基于 HLC 在 Strong/Stale Follower Read 这一块做了许多工作来减少跨域流量从而降低成本。对于 OB,其选择了 Multi-Paxos 而不是 Raft,并且更进一步在 4.0 架构中提出了单机分布式一体化架构来解决其他数据库很难彻底解决的写热点缓解,大事务支持和 1PC 比例增大等难点。当然,这些技术和产品化的工作短期内很难形成事实标准,也都能够在各自的用户场景产生价值,至于孰优孰劣就很难客观判断了。

仅就技术而言,如同我在之前有关 共识算法综述博客 开头中介绍的一样,对于 Raft 和 Multi Paxos 孰优孰劣这一圣战问题,我的主观看法是对于普通 KV,很可能区别不大。对于结合共识和事务模块的 NewSQL 数据库,Multi-Paxos 能够在整体上为一些难点问题提供一点不一样的思路(例如增大 1PC 比例,缓解写热点问题,大事务支持等等),可能有更高的性能天花板。
总结
本文简要总结了 2022 TiDB Hackathon 产品组最佳校园奖热点清零队的工作,并简要分享了本人对 Raft 和 Multi-Paxos 异同的看法,希望能够引起更多的讨论。
感谢您的阅读~